





How Redpanda Cloud Topics rethinks Kafka compaction
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct
The metadata tier and how we built our own key-value store into Redpanda for durability and scale








In part one of our Cloud Topics series, we walked through the Cloud Topics architecture, where producers writing data into L0 files, the Reconciler lifting that data into read-optimized L1 files, and consumers navigating between the two. Along the way, we also mentioned that L1 metadata lives in a shared metadata tier backed by an internal topic and a key-value store.
This post is about that metadata tier (what we call the metastore) and why we ended up building our own key-value store to back it.
As L1 accumulates data, the metastore tracks where everything lands. Functionally, that means mapping Apache Kafka® offsets to positions within L1 objects in object storage, so when a consumer asks for a given offset, the metastore knows exactly which object it should read and which byte range to request. It also tracks things like leader term boundaries, compaction state, and a myriad of other information required to correctly serve the Kafka protocol.
With that in mind, you can imagine a cluster with thousands of partitions and weeks of retention produces a lot of metadata. We needed something that could scale without being bounded by memory or local disk, and we needed it to be flexible enough that adding new kinds of metadata wouldn't require reworking it.
In Tiered Storage, Redpanda's existing mechanism for serving data from object storage, we manage segment metadata with a highly optimized in-memory ordered map that spills to object storage to avoid hitting memory limits. It works, and it's served us well, but the serialization format and the spill-to-cloud logic are tightly coupled to the structure of the metadata itself. Adding new kinds of metadata means changing both, and scaling it means re-solving the spillover problem each time.
Another option was to host the metadata on an external system. While this could have helped us scale storage separately from metadata, it would have also forced us, and our customers, to manage and pay for a whole separate service that we had limited control over improving. That didn't sit well with us.
For Cloud Topics, we wanted a general-purpose storage layer that could scale independently of the metadata format, without bringing in an extra service to get there.
That led us to build our own key-value store. Heavily inspired by LevelDB and RocksDB, at its core it's an LSM tree: writes land in a write-ahead log and are absorbed into an in-memory buffer (the memtable), which is periodically flushed to a persistent, sorted file (an SSTable). A manifest tracks what SSTables exist, along with their key ranges.
Each metastore partition gets its own LSM instance, backed by its own Raft group within an internal Redpanda topic. User-created topic-partitions across the cluster are hash-assigned to a configurable number of these metastore partitions. Within each instance, our implementation diverges from a standard LSM in a few ways, but the divergence we'll focus on here is what backs each persistence layer.
In a textbook LSM database, the SSTables, manifest, and write-ahead log typically live on local disk. For a metadata store that needs to survive cluster loss, that's not an option. We needed each layer backed by something durable and accessible beyond the node it runs on.
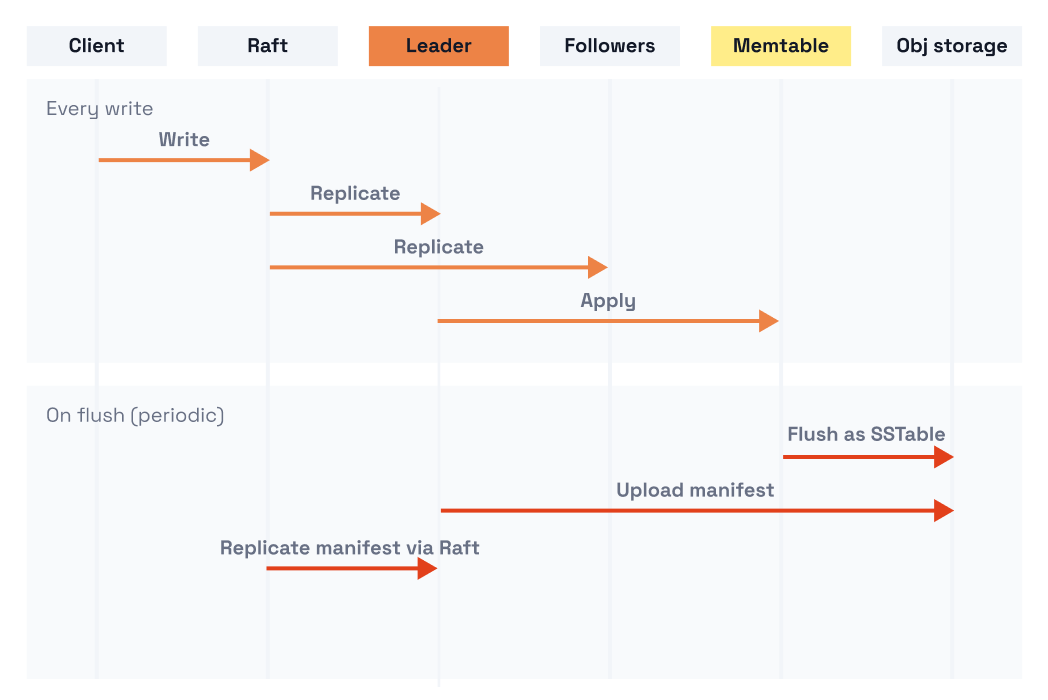
Putting it together, the write and flush paths show how these layers interact:
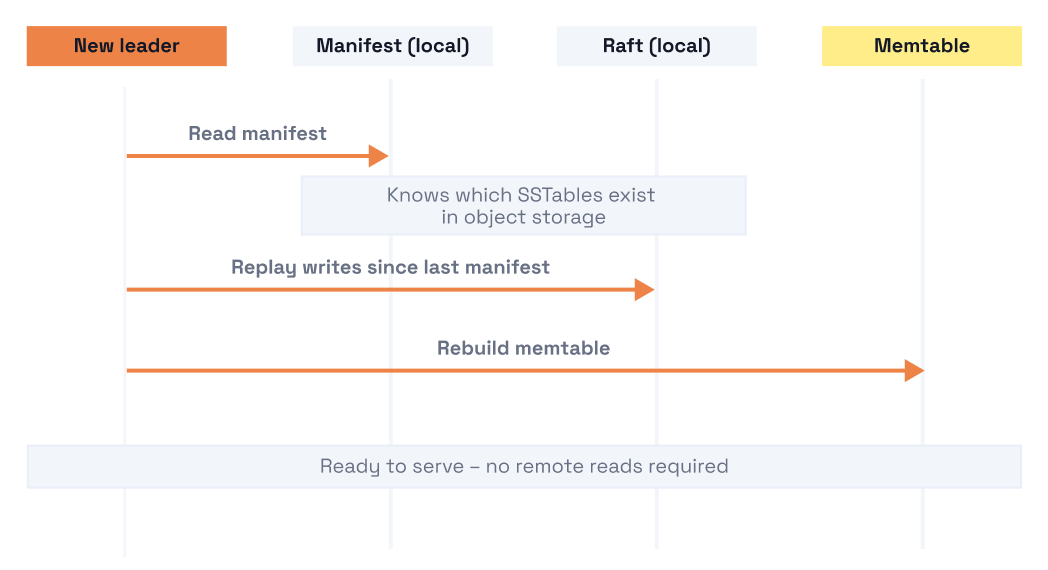
Because both the manifest and the WAL are replicated through Raft, failover is fast; the new leader already has everything it needs locally:
The pluggable persistence layers also give us something beyond scale: the metadata is readable outside the cluster. Each store flushes its memtable every ten minutes by default, which means the complete metadata state in object storage is never more than ten minutes behind. This has two practical consequences:
Redpanda supports Whole Cluster Restore, which recovers a cluster from object storage after a catastrophic failure. Because the metastore's SSTables and manifests are already in object storage, Whole Cluster Restore can rebuild the internal metastore topic directly from object storage. From there, restoring every topic is a matter of reading the metastore to determine where each partition left off, so we know which offsets to continue writing from moving forward.
A read replica topic is a topic that serves a read-only view of data from a different cluster using only what's in object storage. There is typically no direct connection to the source cluster, meaning no additional load on the source. For Cloud Topics specifically, a read replica topic bootstraps by downloading the appropriate metastore manifest. It then pulls SSTables from object storage on demand and serves Kafka clients using the same metadata queries as the source cluster.
In both cases, the tradeoff is the same: the metadata in object storage is only as fresh as the last flush. With a ten-minute default, that window defines the recovery point objective (RPO), the maximum amount of metadata that could be lost in a disaster. It's also the upper bound on how far behind a read replica topic might lag. For our users, that's been a comfortable balance between durability and write amplification.
If you're running Cloud Topics, the metastore is working behind the scenes. It's how the read path looks up offsets in long term storage, how Whole Cluster Restore brings back your topics after a cluster outage, and how read replicas serve your data from another region without talking to your source cluster.
Under the hood, it's a replicated key-value store built into Redpanda with each persistence layer plugged into the right backing store for durability, scale, and accessibility. Cloud Topics is its first use case, but the underlying storage was designed to be a foundational primitive that we’re excited to continue to build on, optimize, and share with you in the future.
In the meantime, you can try Cloud Topics in Redpanda 26.1 with an Enterprise trial. If you’re keen to learn more about Cloud Topics and how Redpanda works under the hood, here are a few links to browse:
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct

A detailed look at the bug we found and the compaction algorithm that solved it

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.