




Apache Kafka's log compaction corrupts data. Here's how we fixed it
A detailed look at the bug we found and the compaction algorithm that solved it
A closer look at Cloud Topics in the Redpanda Streaming engine









Remember when we first introduced Cloud Topics? As a refresher, Cloud Topics allow you to store data directly in object storage (like S3 or GCS) while keeping your local disk footprint strictly for lightweight metadata. This means you can mix and match different topics within the same cluster to optimize each workload for latency, cost, and performance.
In this post, we dive into the architecture of Cloud Topics and how we created the first adaptable streaming engine capable of handling topics that replicate directly via cloud storage and topics that offload cold to object storage, all in a single binary.
And, with the release of Redpanda Streaming 26.1, Cloud Topics has officially entered General Availability.
The Cloud Topics architecture separates where metadata is stored (each partition's Raft log) and where data is stored (object storage). Traditionally, the data and metadata for the records that are produced are written and replicated using the Raft consensus protocol. Since Cloud Topics writes data directly to object storage, we can bypass the Cross-AZ networking tax incurred when replicating via Raft.
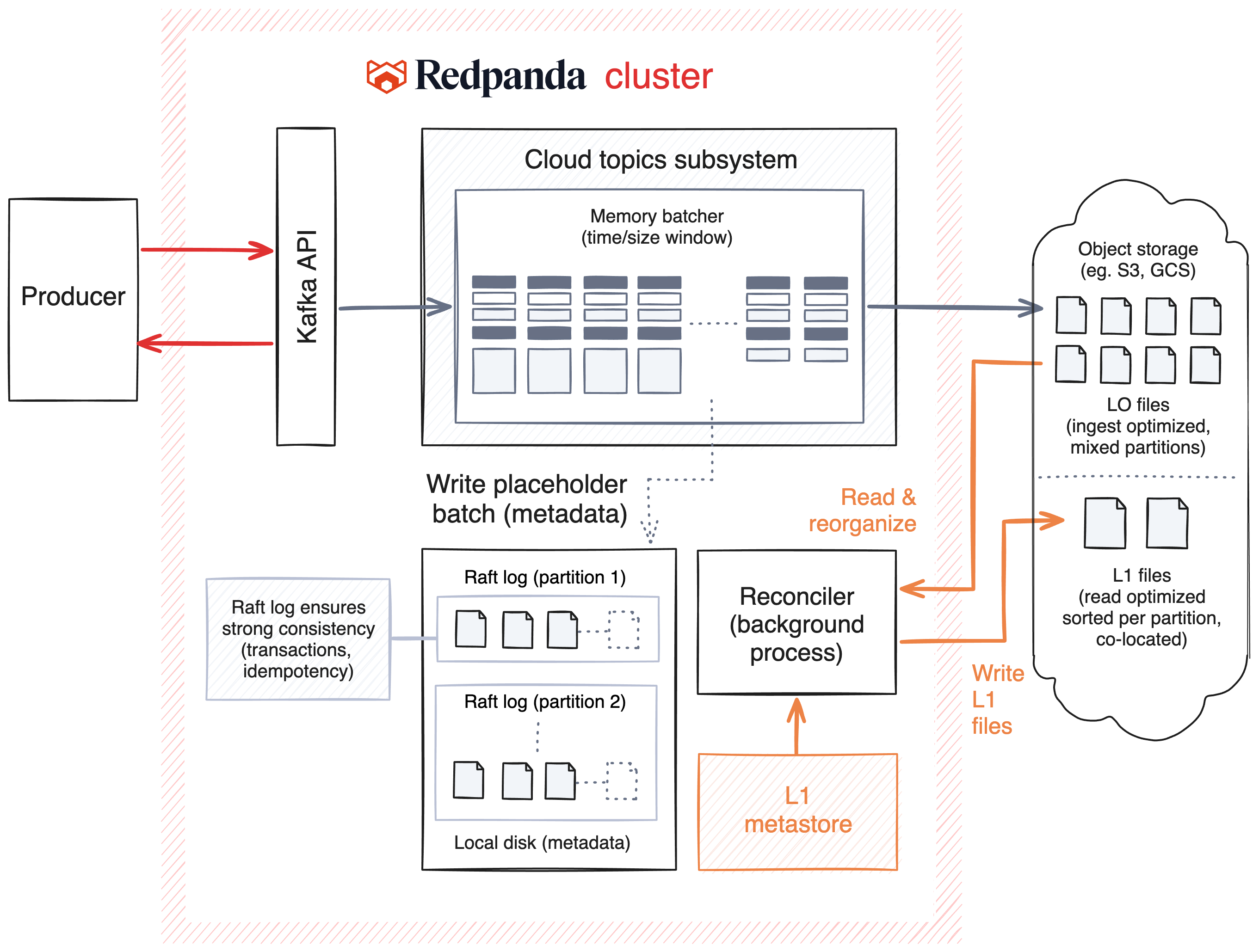
Here’s the breakdown of how it all works:
When a producer sends data to a Cloud Topic, it enters the Kafka API layer as usual. But instead of writing the full payload to the local disk’s Raft log (as we do with standard topics or Tiered Storage), the data is routed to the Cloud Topics Subsystem.
Here, we optimized for cost and throughput.
We batch incoming data in memory for a short window defined by time (e.g., 0.25 seconds) or size (e.g., 4MB). We collect this data across all partitions and topics simultaneously. We do this specifically to minimize the cost of object storage; by aggregating smaller writes into larger batches, we significantly reduce the number of PUT requests sent to S3.
Once a batch is ready:
You might wonder: with this new data path through S3, how do we handle things like transactions or idempotency?
This is where the placeholder batch reusing our normal battle-hardened produce path helps. Because we still use the Raft log for this metadata, Cloud Topics inherit the same transaction and idempotency logic as our standard topics. The data payload lives in the cloud, but the guarantees live in Redpanda.
L0 files are optimized for fast, cheap ingest. For tailing consumers, which represent the vast majority of streaming workloads, data is typically read directly from the memory cache, offering low latency.
However, if a consumer falls behind and needs to read from storage (a cache miss), reading from L0 can be inefficient. Because L0 files contain data from many different partitions batched together, reading a single partition’s history would require "scattered reads" across many different files.
To solve this, we use a background process called the Reconciler.
The Reconciler continuously optimizes the storage layout. It reads the L0 files and reorganizes the data, grouping messages that belong to the same partition and writing them into L1 (Level 1) Files.
L1 Files are:
Once L0 data is successfully moved into L1, it’s eligible for garbage collection and will eventually be removed.
Metadata for L1 files are stored in a shared metadata tier that’s backed by an internal topic and a key-value store. This ensures that the system maintains a robust, consistent view of where your optimized data resides. This includes updating metadata as the underlying data is rewritten by compaction, and removed as the retention policy kicks in.
When a consumer requests data, Redpanda routes the request based on where the data currently lives in its lifecycle. Each partition tracks a Last Reconciled Offset.
Cloud Topics represents a brand new replication mechanism in our streaming engine that slashes costs by using object storage. Stay tuned for future blog posts that dive into more technical details of our implementation. In the meantime, you can watch Cloud Topics in action in our Streamfest product demos.
Remember, you can try out Cloud Topics today in Redpanda Streaming 26.1! We’d love to hear your feedback. In the meantime, here are a few resources to get you rolling.
A detailed look at the bug we found and the compaction algorithm that solved it

Solving a Kafka problem to balance batching efficiency against latency and cost
The metadata tier and how we built our own key-value store into Redpanda for durability and scale
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.