




Adaptive write request scheduling in Redpanda's Cloud Topics
Solving a Kafka problem to balance batching efficiency against latency and cost
Solving the performance bottleneck for high-latency storage









Redpanda was built in an era of shifting bottlenecks. In the early days of designing Redpanda, we loved to talk about how the I/O bottleneck was migrating from the storage device to the CPU. Modern storage devices were becoming so fast that it wasn’t a clunky spinning disk slowing things down; it was thread context switching and cache invalidations.
Today, we take the existence of these fast storage devices for granted and work around the CPU bottleneck using a thread-per-core architecture. Redpanda uses Seastar to provide a thread-per-core solution in C++, but many other languages offer similar solutions.
Fast forward to today, and we see that bottlenecks are shifting again. Demand for low-cost storage solutions, such as cloud object storage, is reintroducing high-latency I/O into systems designed around the assumption of low-latency storage. In Redpanda, this shift occurs within Cloud Topics, a new storage mode that uses inexpensive cloud-based object storage. Just as older systems had to confront the introduction of high-performance storage, Redpanda isn’t immune either.
In this post, we discuss how the introduction of high-latency storage wreaked havoc on our performance when developing Cloud Topics, and how we flipped an architectural oversight into an improved process.
Here’s what happened: an old bottleneck in our request pipeline resurfaced with the introduction of object storage into the write path for Cloud Topics. To understand why that happened, we’ll share how Redpanda handles writes today when low-latency storage is available. This is the same storage you use in Redpanda with standard or Tiered Storage topics. The diagram below illustrates this write pipeline.
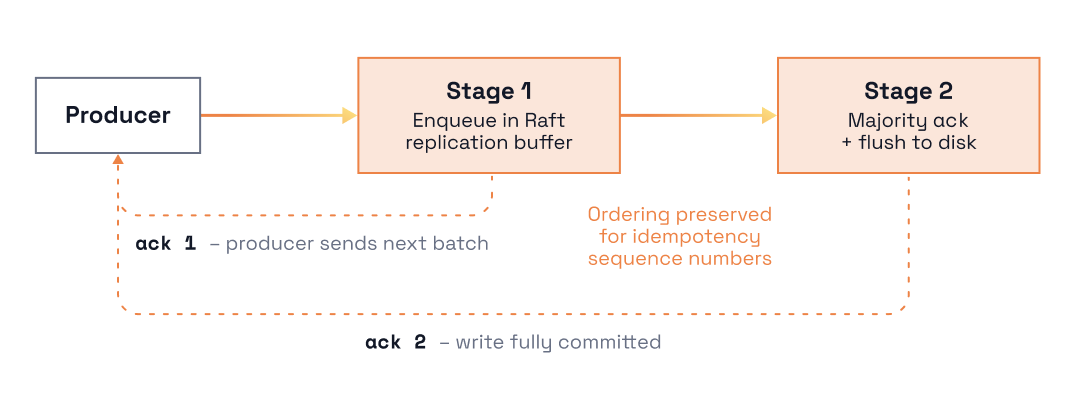
Each Apache Kafka® produce request on a connection is processed sequentially:
There is one wrinkle: the first two stages are extremely fast (e.g. < ~1ms). So if replication takes, for example, 10ms, then the system can only process 100 requests per second per connection. And indeed, replication is the bottleneck in this pipeline.
However, we observed early on that after a request’s position in the pipeline has been guaranteed, all of its dependencies have been resolved, and the next queued request can be processed before previous requests have been replicated. This allows pipelined processing of produce requests and was a significant improvement over the early design.
If the produce handling in Cloud Topics had merely replaced the replication phase in the pipeline described above, with an even slower I/O path based on object storage, we might not be writing this post. In such a model, the same assumptions about relative performance would have remained unchanged. However, things are more complicated than this in Cloud Topics.
To understand where the new bottleneck arises, it’s necessary to know that storage in the Cloud Topics write path consists of two stages: one for metadata management and another for application payload data.
This is different than standard topics where application data and metadata are stored together. In particular, the existing replication layer handles Cloud Topics metadata, while payload data is written directly into cloud object storage. In the diagram below, notice that an additional queue and object storage upload phase is introduced before the metadata is enqueued into the replication layer. We effectively reintroduced the exact same class of bottleneck.
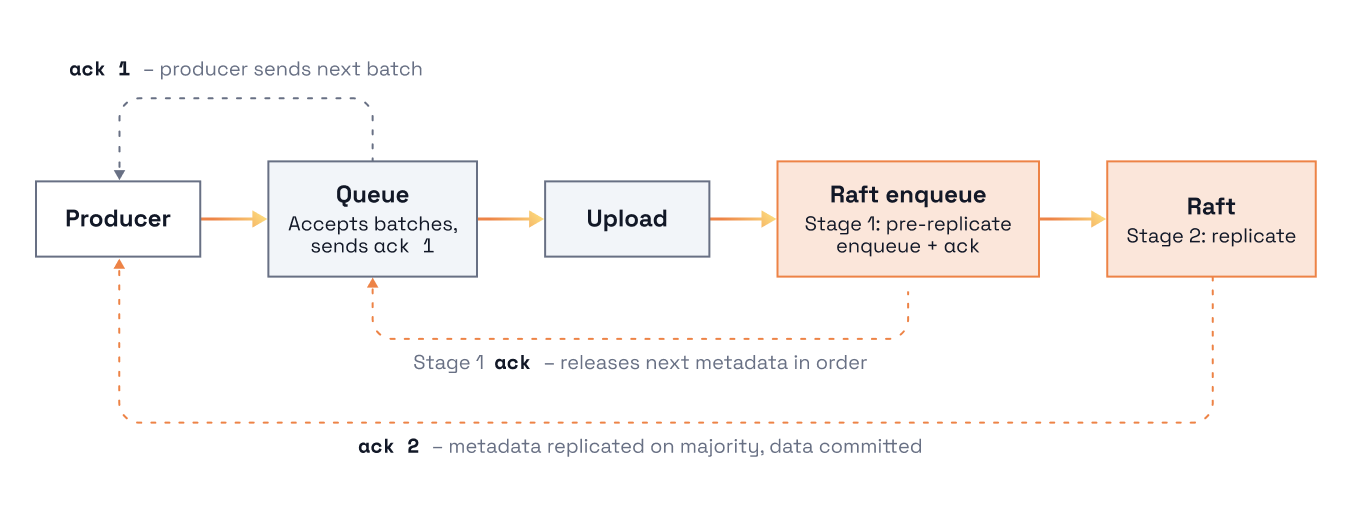
What is different now is that the latency of the upload phase could be up to 100x slower than the replication phase. This makes it easy to feel the implication of Little's Law, which equates to Throughput = Latency * Concurrency.
To improve our throughput with the increased latency, we had to figure out how to increase concurrency. Just like last time, we addressed this with an additional layer of queuing. As shown in the image above, this extra queueing is introduced during the upload phase of the write path, before requests are processed by the replication layer, and helps hide the large latencies caused by cloud object storage.
The additional queue becomes a mechanism for the producer and networking layers to release more batches into the system. And, with more requests queued in this new layer, we can upload more batches from a single producer in parallel.
Once the data is uploaded, we preserve the ordering from the producer and release it into the replication layer, again waiting for the replication layer to ensure our position meets the needs of idempotent workloads. We still hold the producer acknowledgment until the metadata is fully replicated across the cluster. This means we preserve the correct ordering and data durability requirements at every stage while allowing more concurrency in the latency-bound part of request processing.
So how well does this work? Running OpenMessaging Benchmark with this change was the key to unlocking throughput, and allowed us to easily push through to the GB/s scale we were targeting without needing to change any producer configurations.
When we discovered this bottleneck in our performance testing a few months ago, we realized we had been so focused on building functionality that we hadn’t been focused on pushing real-world workloads through the system. Thanks to the entire Cloud Topics team, our carefully thought-out implementation readily accepted the fixes we needed, and what could have been a serious architectural oversight became an insightful process.
Interested in trying Cloud Topics and saving on your cross-AZ networking bill? Cloud Topics is available in Redpanda 26.1 with an Enterprise trial. If you’re keen to learn more about Cloud Topics and how Redpanda works under the hood, here are a few resources to browse:
Solving a Kafka problem to balance batching efficiency against latency and cost

Now deployable on Amazon Web Services (AWS)
The metadata tier and how we built our own key-value store into Redpanda for durability and scale
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.