





Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too

Start replicating your data the Redpanda way








Most organizations require business continuity: the ability to keep operating while handling and recovering from a significant disruption, such as a regional outage. This is where disaster recovery comes in, and for streaming data, this almost always means continuous replication. While this would historically be done with external tooling, Redpanda now has built-in replication that’s fast, simple, and offers perfect fidelity.
For teams that need reliable, cost-efficient replication with the lowest operational complexity, shadow linking is a safe bet.
In this blog post, we’ll walk you through the new Shadow Linking feature within Redpanda and inspire you to take even better care of your streaming data by replicating it to another cluster.
Disaster recovery helps ensure you don’t lose revenue when your systems are unavailable for an hour or so. Keeping disruption to a minimum means first understanding, and later reducing, two elements:
Replication helps achieve both; RPO can be reduced by replicating in near real time, while RTO can be reduced by enabling application recovery through failover.
Replication is also useful beyond disaster recovery:
Shadowing is Redpanda’s enterprise-grade disaster recovery feature that’s built into the heart of the broker itself. It replicates everything you need to use a topic on a remote cluster:
_schemas topic can be replicated when the feature is enabled, allowing schemas (and schema settings, such as compatibility) to be replicated.The architecture follows a simple active-passive pattern. The source cluster processes all production traffic while the shadow cluster remains in read-only mode, continuously receiving updates:
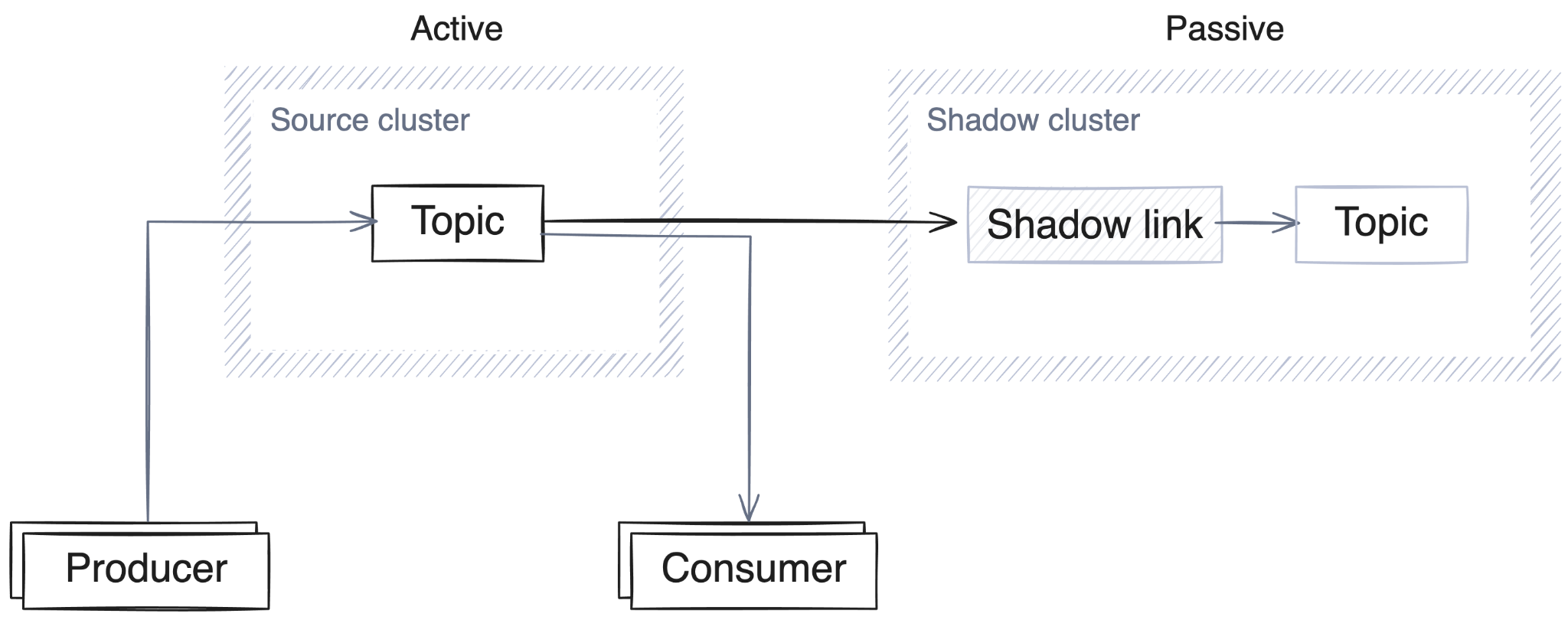
If a disaster occurs, you can fail over the shadow topics, making them fully writable on the shadow cluster. At that point, you can redirect your applications to the shadow, which becomes active as the new production cluster:
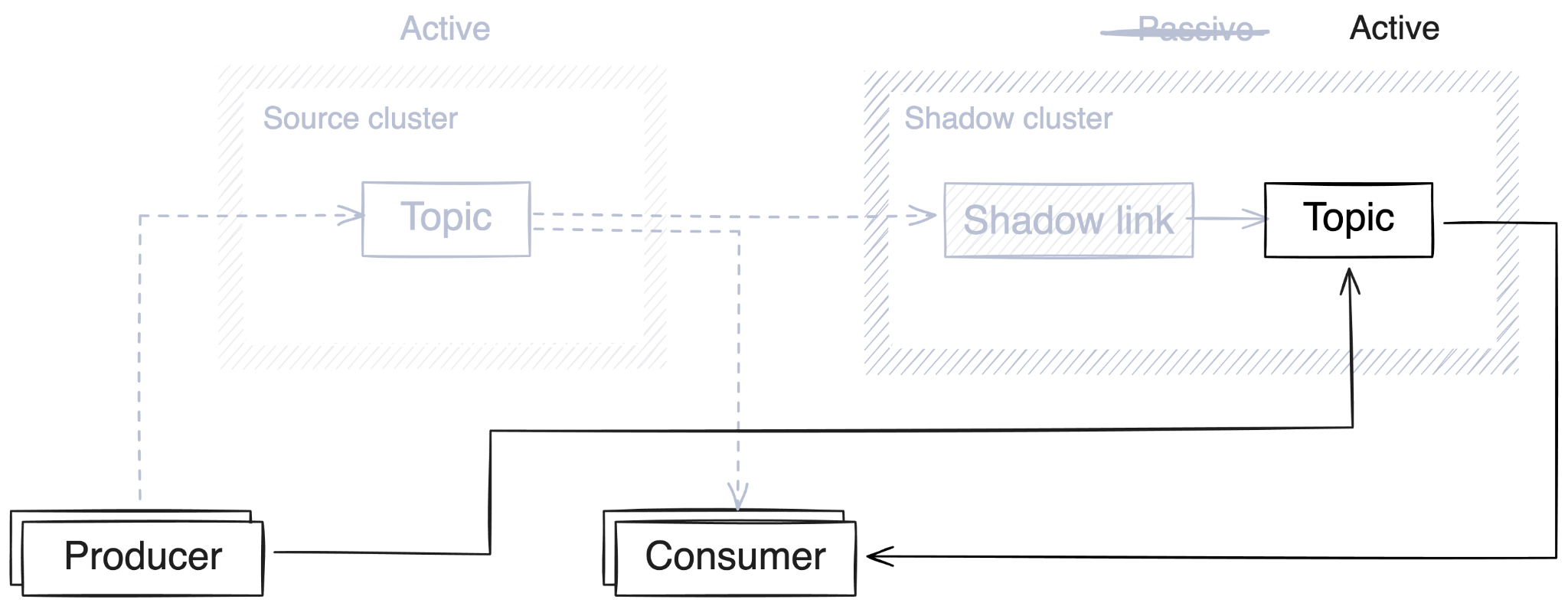
A shadow link is defined within the shadow cluster and creates tasks internal to the broker that read data from the source cluster and write it locally. These tasks read data from the source using the standard Kafka API. Once the link is established, topics will be created and configured automatically, ACLs will be applied, commits will be replicated, and (of course!) messages will be mirrored, all on a continuous basis. Let the data flow!
Things to be aware of:
Asynchronous replication has been available using tooling such as Apache MirrorMaker 2.0 for many years, so why has Redpanda developed Shadow Linking now, and what is different about it?
Firstly, Shadow Linking is broker-native functionality, not an external service. When we replicate messages, we guarantee they will always have the same offset as they do on the source, without any offset translation.
This is a huge advantage over traditional approaches:
Operating a Shadow Link is also simple:
From either a development or an operational perspective, simplicity always has an outsized payoff; complexity adds cognitive load, adds unknowns and ambiguities, and increases the number of failure points. In short, it adds risk. Simple is good.
This simplicity means that failover isn’t something to fear, but something that can become routine. By practicing failover, teams can provide verifiable evidence of their disaster recovery readiness. Having high confidence in your preparedness (based on demonstrated capability) is infinitely more useful than the usual hopeful assumptions.
Shadow Links also have the benefit of efficient infrastructure. Consider replicating a stream of messages at 1GiB/s using an external tool such as MirrorMaker:
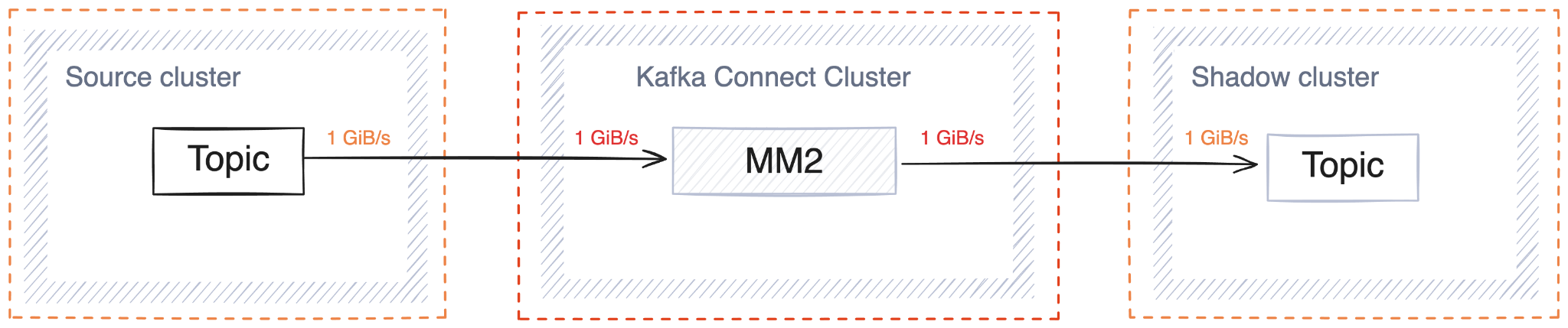
In addition to the source and sink clusters, you would need another cluster to host the replication workload. In contrast, when using shadowing, no additional hardware is needed:
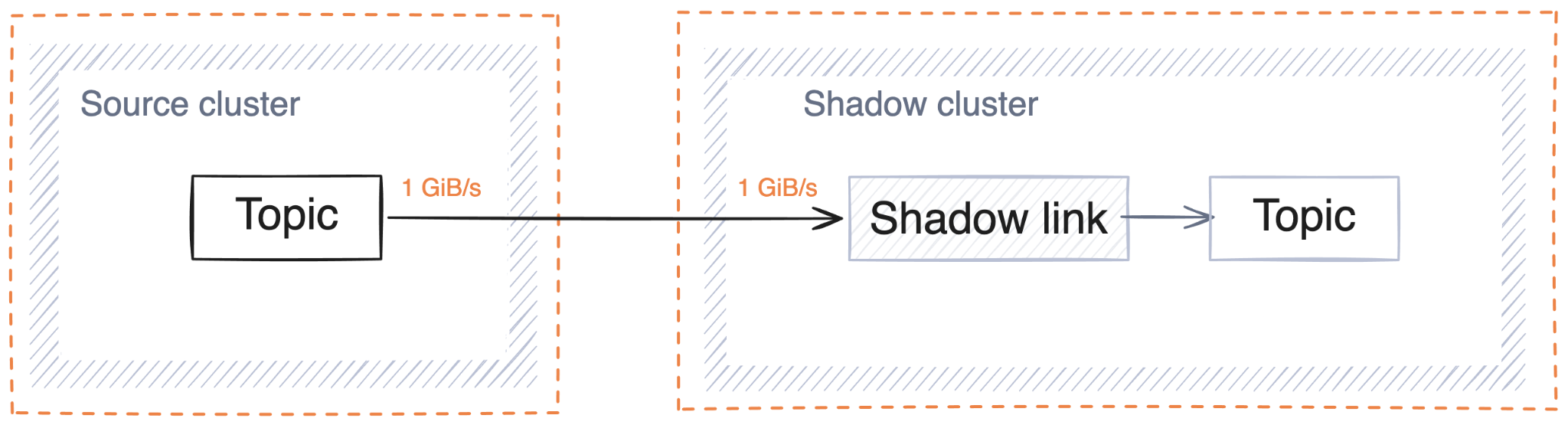
Worse still, external replication tools can’t guarantee the fidelity of the replicated data; it’s not uncommon for duplicate messages to be introduced by the replication layer. In other words, not only is the external tool approach more expensive, but it also yields a worse outcome. (Lose-lose, anyone?)
It’s always true that nothing comes for free; adding shadow linking to an existing cluster will use resources, but it’s also important to consider that your existing Redpanda clusters may have enough processing headroom already. In which case, by using shadowing, you’re doing the work directly on the broker, getting even more value from your existing investment.
Just like the rest of the Redpanda broker, the Shadowing components are written in high-performance C++, which means that not only do you get great replication performance, but there’s also no Kafka Connect and no JVM tuning in sight. Woohoo!
As an illustration of the performance, I recently scale-tested shadowing, driving the source cluster at 2.5 GiB/s. During that experiment, I was able to replicate with a total lag (across all topics) that was consistently lower than 10,000 messages—on a workload producing 2.5 million messages per second—giving us an effective RPO of around 4 milliseconds on average.
Shadow linking also scales naturally with the cluster, both vertically and horizontally. If you use bigger nodes with more cores, Redpanda’s internal shared-nothing architecture can use that to its fullest. If you scale out the cluster and add more nodes, we will use them to increase the shadowing parallelism, all without you needing to tune anything out of the box.
When a link is active, data is flowing to the shadow cluster and the topics being written to are read-only to other producers. So what happens when the source cluster gets hit with a meteorite? (Or more likely, you’re having an outage in a specific cloud region?)
This is where failover comes in. When you failover a link, either by topic or entirely, the replication flows stop and the linked topics will become writable to regular producers. At this point, you can migrate your consumers and producers by reconfiguring them to point directly to the shadow cluster instead of the source cluster and continue where you left off.
Keep in mind that if you have an app-level outage, you don’t need to failover the whole link—just failover individual topics as needed. Sorted. And, if an emergency does happen,we’ve got you covered! Not only do we have a world-class support team on standby, but we also have a failover runbook for you to use. Definitely one to keep bookmarked!
As we’ve seen above, shadow links are unidirectional: data always flows from the source cluster to the shadow, in an active-passive manner, with the shadow cluster serving only as a backup. Some organizations may wish to distribute risk by having shadow clusters serve primary roles to get the most out of their infrastructure.
Let’s say you run your business in two regions, and have producers (and Redpanda clusters) based in each region. Under normal circumstances, you’d want each producer to write to their local Redpanda cluster in order to get the lowest produce latencies, rather than having some of them always write to a distant cluster. This kind of reciprocal active-passive architecture, in which both clusters are active and usable, can still be achieved with parallel shadow links.
In this deployment architecture, each cluster acts as both a source cluster and a shadow at the same time:
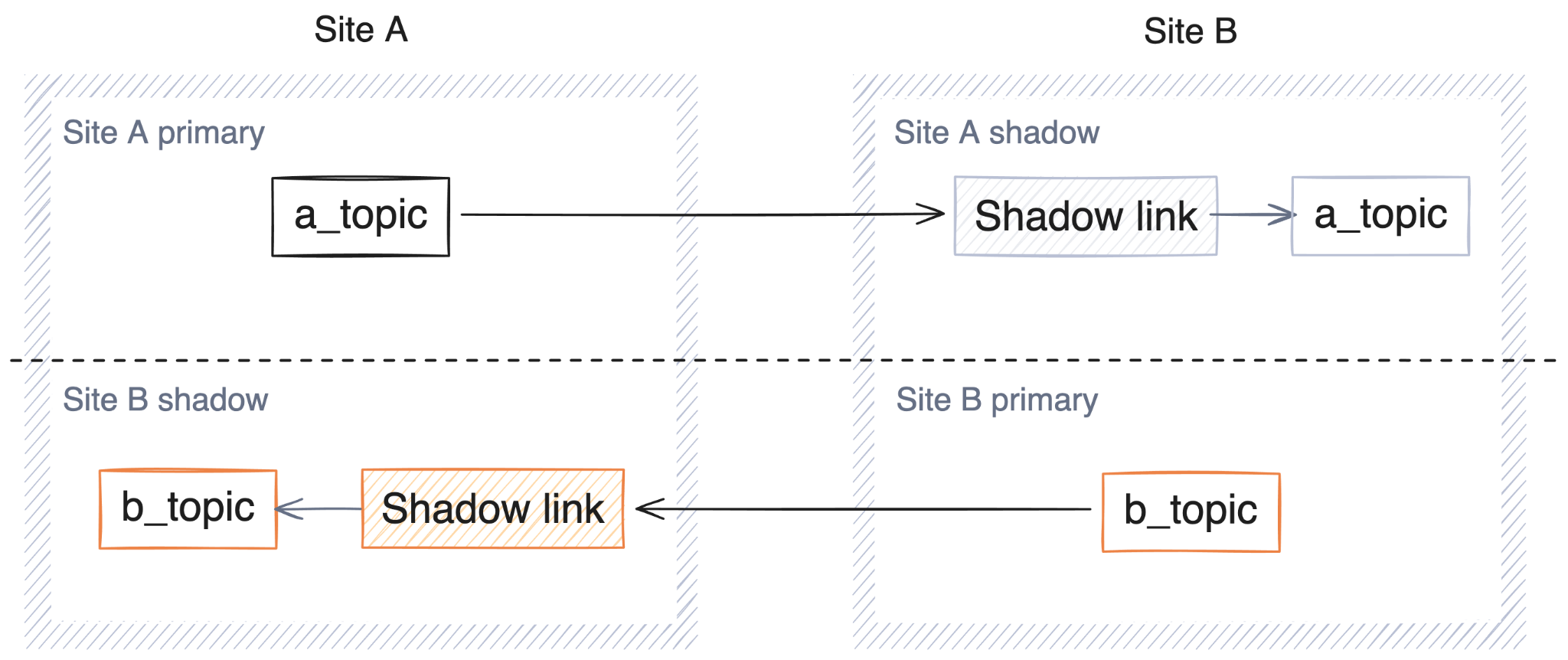
Running a reciprocal active-passive cluster pair is as simple as configuring two shadow links — one on each cluster. This design benefits from using a consistent prefix to name topics and consumer groups, identifying their source site. In the example above, the prefixes of a_ and b_ in the topic names indicate which cluster they originate in.
While not strictly necessary, the name prefixing is helpful for multiple reasons:
In addition, a primary site for schema registry would need to be chosen (since both sites will use _schemas).
When running a reciprocal active-passive cluster pair, producers will be configured as expected: simply writing to their local topic. Consuming messages is conceptually a little more complex, in that there are now two topics that need to be read by the same consumer group (local and shadow). In practice, this just means a little more configuration of the consuming client.
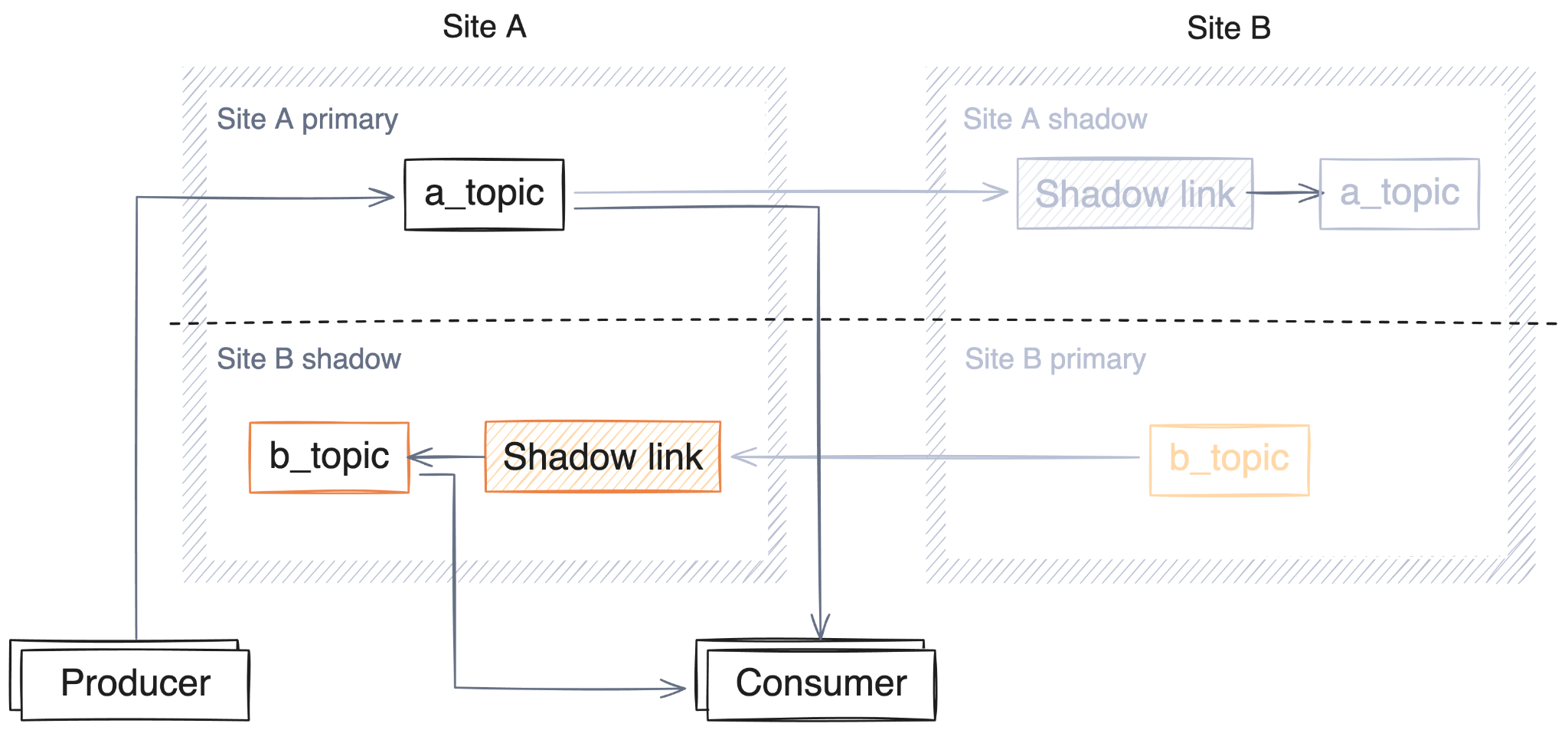
As you might expect with this architecture, both sites support simultaneous producing and consuming. Failover in either direction (from A to B, or B to A) is possible, making this design fault-tolerant to an outage in either location.
Shadow linking addresses the core challenge of real-time data replication with both simplicity and performance. Now that you’re ready to learn more about shadowing, we have options for you:
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

