




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Your analytics stack can only see data that made it through the pipeline. That's only half the picture.









Great news: Redpanda SQL is generally available! It's a Postgres-based query engine that runs inside your Redpanda BYOC cluster, lets you query live-streaming topics and historical Iceberg tables in a single SQL statement, and requires no ETL pipeline or connector fleet to do so.
Now, a brief word on why the industry took so long to get here.
The data engineering industry spent a long time agreeing that if you want to query your streaming data, you should first move it somewhere. Build a pipeline, set up connectors, wait for ingestion, then query it. This created a lot of bulky streaming jobs (Apache Flink® and Apache Spark™ being the preferred “hammer looking for nail”), a lot of excess compute, and a lot of confusing methods to achieve the same ends.
Often, that view through the pipe was limited. You had to decide what to ingest, and data that arrived in the last few minutes remained invisible to your entire analytics stack, particularly when ingesting at high throughput using bulk data formats like Apache Iceberg™ or Delta Lake, which aren’t optimized for streaming ingest. Finally, when your Flink or Spark jobs break at 2 AM, you're left grepping through log dumps like it's 2003.
Today, we're fixing that.
Here’s how querying streaming data has worked for most teams (for a long time): producer data flows into Redpanda or Apache Kafka®. A connector picks it up and ships it to Snowflake, Databricks, BigQuery, or wherever your warehouse lives. A few (or many!) minutes pass. The data lands. Now it's queryable.
Modern lakehouse vendors have solid tooling for streaming ingest (with a few seconds to minutes of arrival delay). The pipeline is doing exactly what it was built to do. The problem is structural: your warehouse can only see data that made it through the pipeline. Everything still in motion—the last few seconds or minutes of your event stream—is completely invisible to it.
And so are streams not specifically selected for ingestion from the lakehouse side.
What are the malformed events and missing fields that your producer apps are spitting out right now? Most teams have decided that waiting and blind spots are acceptable. It is acceptable. It is also the reason your on-call engineers have a file called topic_dump_2024_03_15.json still sitting on their desktop and a Jupyter notebook called kafka_investigation.ipynb that connects to Kafka for what the commit message describes as "debugging purposes."
Nobody set out to build a system where querying live data required this much work. That's just what happened as the demand for integrating event streams into analytics ballooned, and people used the tools they had. Redpanda SQL is what happens when you stop accepting that as the answer and rethink the problem from first principles.
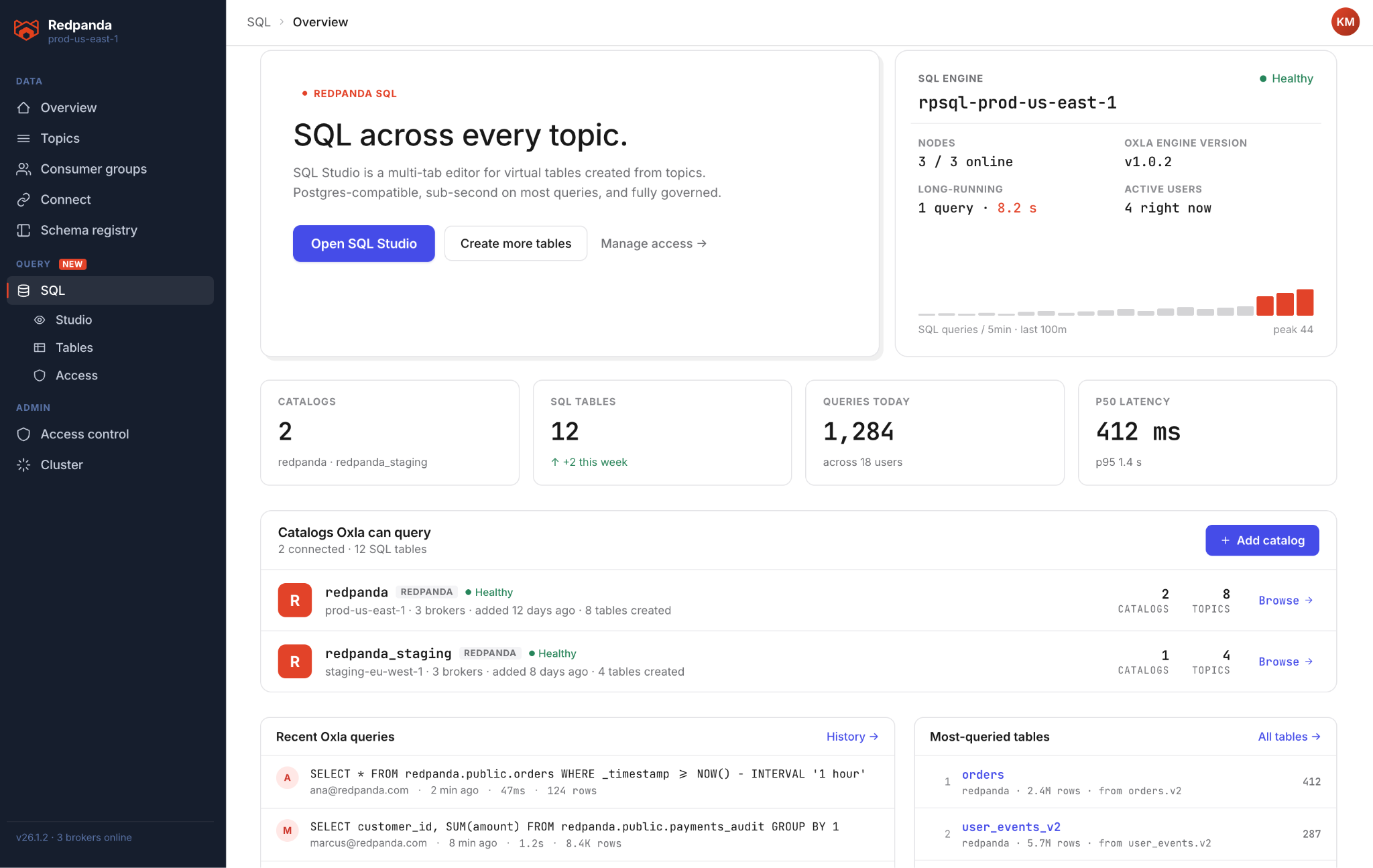
Redpanda SQL runs inside your existing BYOC cluster, on the same infrastructure as your streaming data brokers and Iceberg storage. It speaks Postgres. You connect with psql, DBeaver, DataGrip, or the SQL Studio built into Redpanda Console—whatever you already have open. Your topics are tables. You write SQL. You get results.
The data you're querying might have arrived three years ago or three milliseconds ago. Either way: same table, same query, same endpoint, same result. If you're using Redpanda Iceberg Topics, which store your streaming data in both a live tier and a Parquet/Iceberg cold tier in S3 or GCS simultaneously, Redpanda SQL bridges the two tiers transparently. The engine figures out an optimized read path across both. (And you don't have to care.)
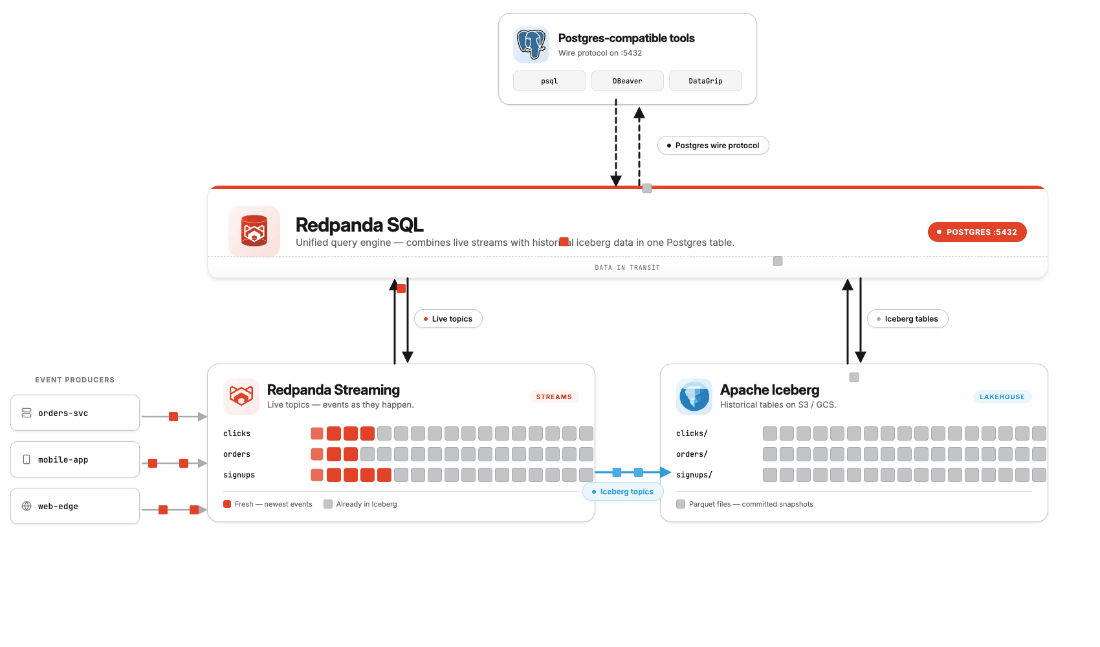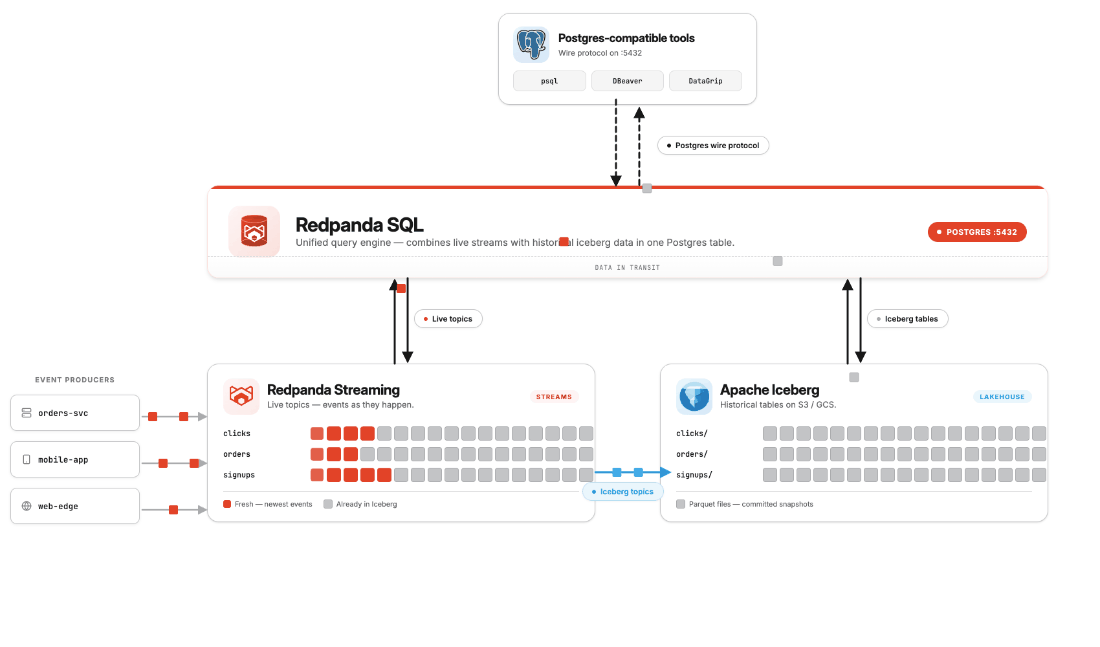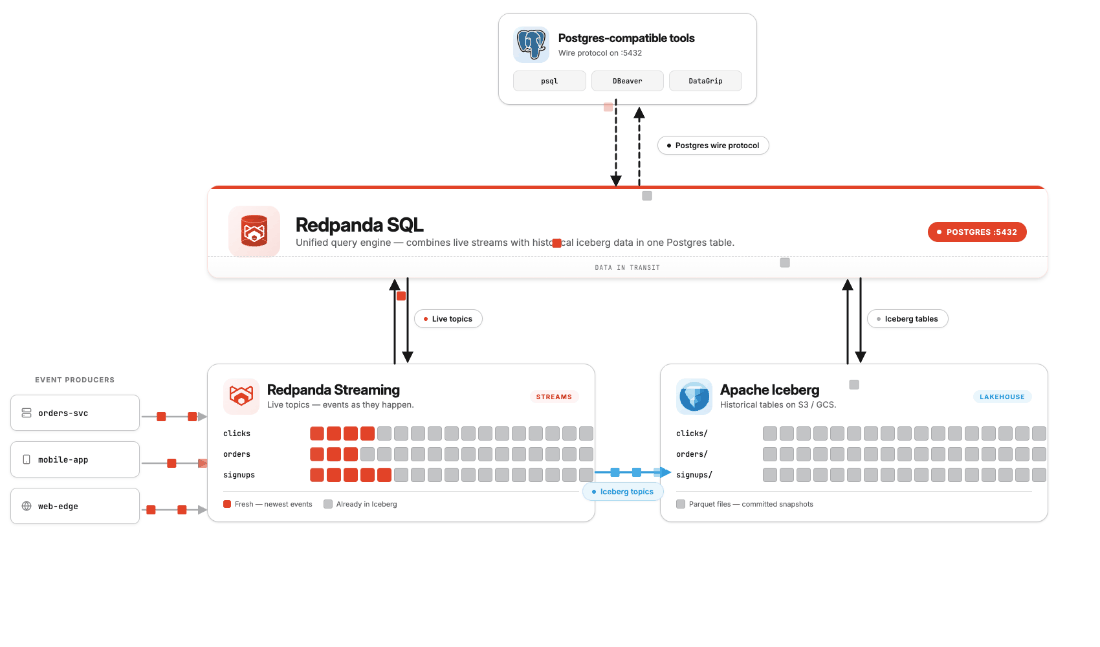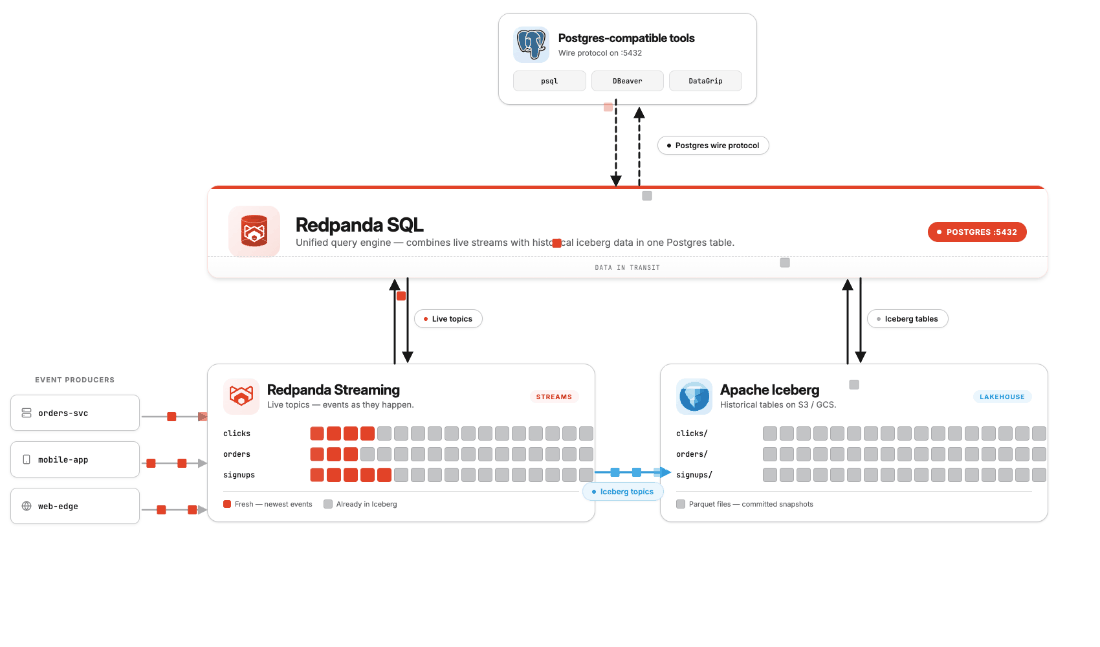
One thing worth explaining before you see it in the setup flow: you'll notice the name "Oxla" when you activate SQL. Redpanda SQL is built on MPP (Massively Parallel Processing) engine technology from Oxla, which Redpanda acquired in 2025. Like Redpanda Streaming, the engine is written in C++. It was designed to run analytical workloads at scale with extreme memory efficiency, amplifying OLAP query throughput, and it's managed entirely by Redpanda.
Yes, you can just write a SQL query. That’s the whole thing. There are no materialized views to predefine, nor a proprietary storage tier that shields data from other tools. No streaming pipelines to build before the data arrives. ksqlDB is a handy tool, but it requires you to decide what questions you're going to ask before the events arrive, which requires a level of foresight that most data quality problems, incident postmortems, or agent-driven analytics work suggest we do not actually have.
Redpanda SQL is fully ad hoc: connect a client, write a query, get results. No new drivers, no new query language, no new anything to install or embed into your apps. If your team writes SQL today, your apps, humans, and agents can query Redpanda tomorrow. It’s just Postgres.
Plus, the data doesn't move. Redpanda SQL runs on the same infrastructure as your brokers, inside your VPC, and every query accesses data in-place, in both the hot (stream) and cold (Iceberg table) tiers. Nothing is sent to a third-party compute service, which is critical if you have compliance requirements (and just as important for strong cybersecurity hygiene), working within your existing infosec-approved environment.

Let's set the scene: it's late, and production broke down. Something happened in your producer app and you need to know what. Maybe an errant new schema version got pushed, maybe not. Your warehouse is 1–10 minutes behind, which is technically fine, and also not fine right now. Your options are:
Most teams pick Option B because at least it gives them something to do. This has been the standard debugging workflow for streaming data engineers for years. Everyone accepts it. Nobody enjoys it.
With Redpanda SQL, there is Option C:
SELECT * FROM orders WHERE status = 'failed' AND timestamp > NOW() - INTERVAL '30 minutes'
Results in seconds. Faster mean time to resolve (MTTR). Incident closed. kafka_investigation.ipynb deleted at last.
Fraud models, recommendation engines, live leaderboards, inventory systems, intrusion detection—these are production applications that make a decision on every event, as it arrives. When those apps query a warehouse, they're working from data that's already minutes old. In fraud, that's the window where a transaction gets approved that shouldn't have been. In personalization, that's the moment you serve the wrong offer. In cybersecurity, that's the gap between "intrusion started" and "someone noticed." Redpanda SQL queries live topic data directly. There's no lag between the event and the decision.
Every analyst running queries in your warehouse is working from a snapshot of reality that's at least a few minutes old. For most workloads, this is fine. For quick investigations, like a spike in failed payments, a suspicious login pattern, or a pricing anomaly, those minutes matter.
Redpanda SQL queries live topic data and Iceberg history in the same statement, giving analysts an up-to-the-millisecond view without waiting for the pipeline to catch up. That translates to faster answers on BI dashboards, shorter incident timelines, and less time explaining to your CEO why the numbers don't match what production is doing right now.
Regulated data that cannot egress to an external SaaS provider can now be queried directly within your VPC, without procuring a separate query engine or moving data across providers, regions, or network zones. The data stays in your environment. Your data doesn't need to travel to be queryable.
A human analyst writes one query, reads the result, writes another. An AI agent fans out across dozens of tables and writes hundreds of queries simultaneously: comparing time windows, validating patterns, and exploring hypotheses in parallel. Agents need data that arrived seconds ago to make good decisions—not a pipeline snapshot from several minutes ago that may no longer reflect what's actually happening.
Redpanda SQL gives agents standard SQL access to live event streams and full Iceberg history in a single interface, at the freshness and scale their workload actually demands, with a minimal infrastructure footprint, so you can support swarms of those chatty, curious, data-devouring agents.
Redpanda Streaming moves your data. Redpanda Connect wires up sources and destinations. The question of what to do with it after that—SQL queries, ad hoc investigation, operational analytics—used to require a third system from a different vendor. As of today, it doesn't.
One architecture. One operational model. One vendor. And one fewer conversation about which tool handles the analytics layer.
SQL is in the top five most-used languages globally (Stack Overflow Developer Survey 2024, or just ask Claude and it will tell you it's top 3). If your team writes SQL (and statistically, they do) they now have a direct path to your streaming data that doesn't require learning Kafka, building a pipeline, or explaining to your analysts why the data they need isn't in the warehouse yet.
Redpanda SQL is GA today for Redpanda BYOC customers on AWS on a consumption-based (usage-based billing) plan.
GCP BYOC and BYOVPC support are coming soon, and your account team has the latest timeline, so just reach out. Self-managed deployment is targeted for 2H FY27.
If you're an existing BYOC customer on AWS on a usage-based plan, it’s just three steps and no cluster restart. You do not need to open a ticket. Just log in to Redpanda Cloud and follow the setup flow.
Not sure which plan you're on? Check in with your friendly neighborhood Redpanda account team!
For a deep dive with our pandas (and a demo), watch our Redpanda SQL tech talk on demand.
{{featured-event}}
You can also:
Already a Redpanda BYOC customer on a consumption-based plan? Log in to Redpanda Console and activate SQL from the cluster overview page. And kiss the topic_dump_2024_03_15.json on your desktop goodbye!
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.


