





10X more data, same 4 seconds: testing Redpanda SQL at scale
A benchmark on how a single analytical query behaves as the dataset and cluster grow

Solving a Kafka problem to balance batching efficiency against latency and cost








Redpanda's Cloud Topics let partitions store data entirely in object storage, eliminating local disks and decoupling storage cost and capacity from the brokers themselves. Clusters become cheaper, elastic, and have effectively unbounded retention without the operational overhead.
Apache Kafka® producers connect and write exactly as they would against any Kafka cluster, without client changes or new APIs. However, under the hood, the data path is fundamentally different: every batch is uploaded to S3 as a "Level Zero" (L0) object before the produce request is acknowledged. That puts object storage directly in the hot write path, which makes how we batch and schedule those uploads load-bearing for the whole system. Get it wrong, and you pay for it in producer latency, throughput ceilings, or a surprisingly large monthly S3 bill.
So we built the write-request scheduler to solve exactly that problem. Instead, the scheduler dynamically adjusts upload parallelism across cores to balance batching efficiency against latency and cost. That means a cluster running at 50 MB/s and one running at 5 GB/s, both land
on the right behavior with no operator tuning. This post describes how it works.
The component that uploads data to S3 is the batcher. It aggregates write requests from many partitions into a single L0 object and issues one S3 PUT. Packing more data per PUT is efficient because it reduces requests and overhead. Except waiting to fill a batch hurts latency.
If every shard (a CPU core in Redpanda's terminology) ran its own batcher, a 32-core machine would issue 32 concurrent PUTs per cycle, with most carrying tiny payloads and wasting S3 requests. Latency also suffers since a single shard may not receive enough data to fill a batch quickly.
The batcher operates on two thresholds:
When a shard doesn't hit the size threshold, it falls back to the time threshold, adding up to 200 ms on top of the actual upload latency (tens of milliseconds).
The other major downside of per-shard batching is cost. If Redpanda uploads every 200 ms, PUT requests cost roughly $65 per month per broker. Per-shard batching multiplies that by the number of shards, so with 32 shards it becomes $2,000 per broker per month, or $120,000 per year for a 5-broker cluster in PUT requests alone.
Funneling everything through one shard maximizes batch size and minimizes cost. The same 5-broker cluster would spend $3,750 per year on PUTs, but it caps parallelism at 1x, which becomes the bottleneck under heavy load. The right answer depends on current throughput and changes continuously. Upload parallelism can't be configured in advance; it has to adapt automatically.
Redpanda is built on Seastar, a thread-per-core framework in which each shard owns its data and communicates only via message passing. Shared mutable state is anathema. Any solution to this problem must coordinate shards—deciding who uploads what and when—while minimizing cross-shard synchronization. That tension shaped the design.
The simplest approach is for one shard to become the coordinator. It checks every other shard's backlog, decides which shard should upload, collects requests from the chosen shards, sends them to the target shard, and triggers the upload. The coordinator must synchronize with every shard on every upload cycle via cross-shard locks. It itself becomes a bottleneck—all decisions and data flow through a single shard regardless of load. Except this doesn't scale.
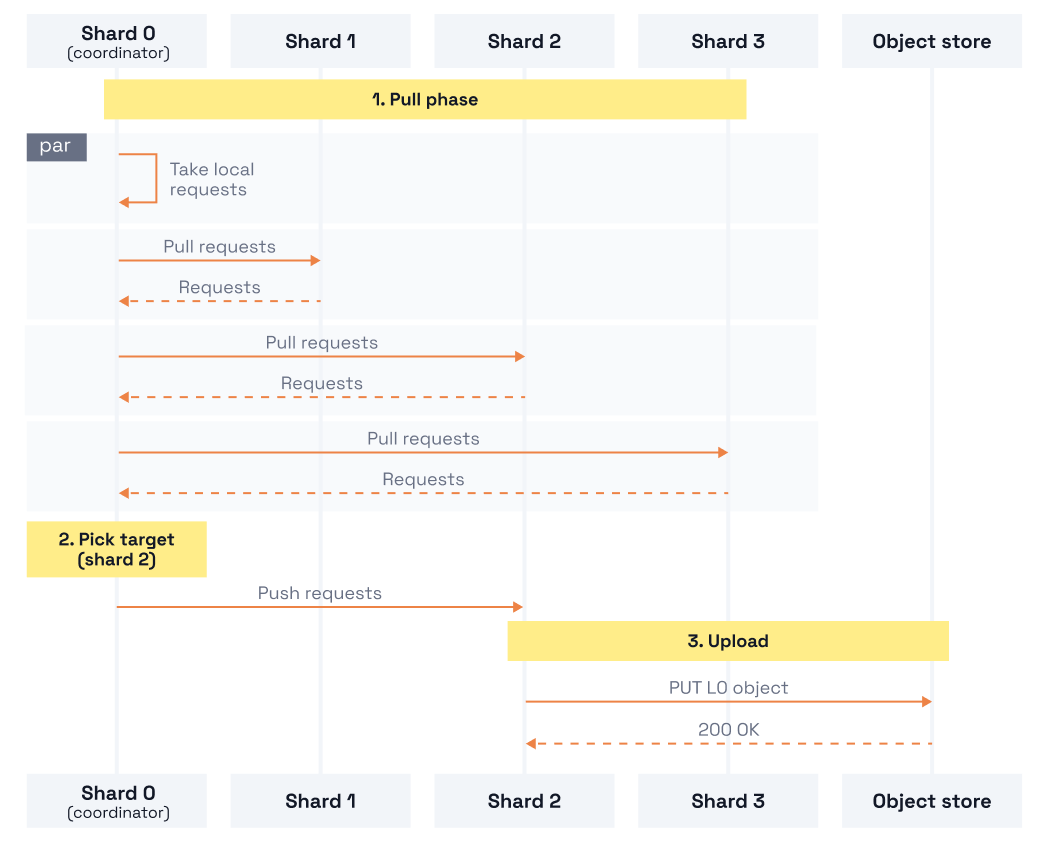
The coordinator no longer moves requests directly. Instead, it assigns shards to groups. Each group uploads independently with its own local leader; the global coordinator only rearranges group membership based on load. Groups upload in parallel, and the global coordinator is out of the hot path. This approach is an improvement, but splits and merges require global coordination, and the protocol for handing shards between groups is complex.
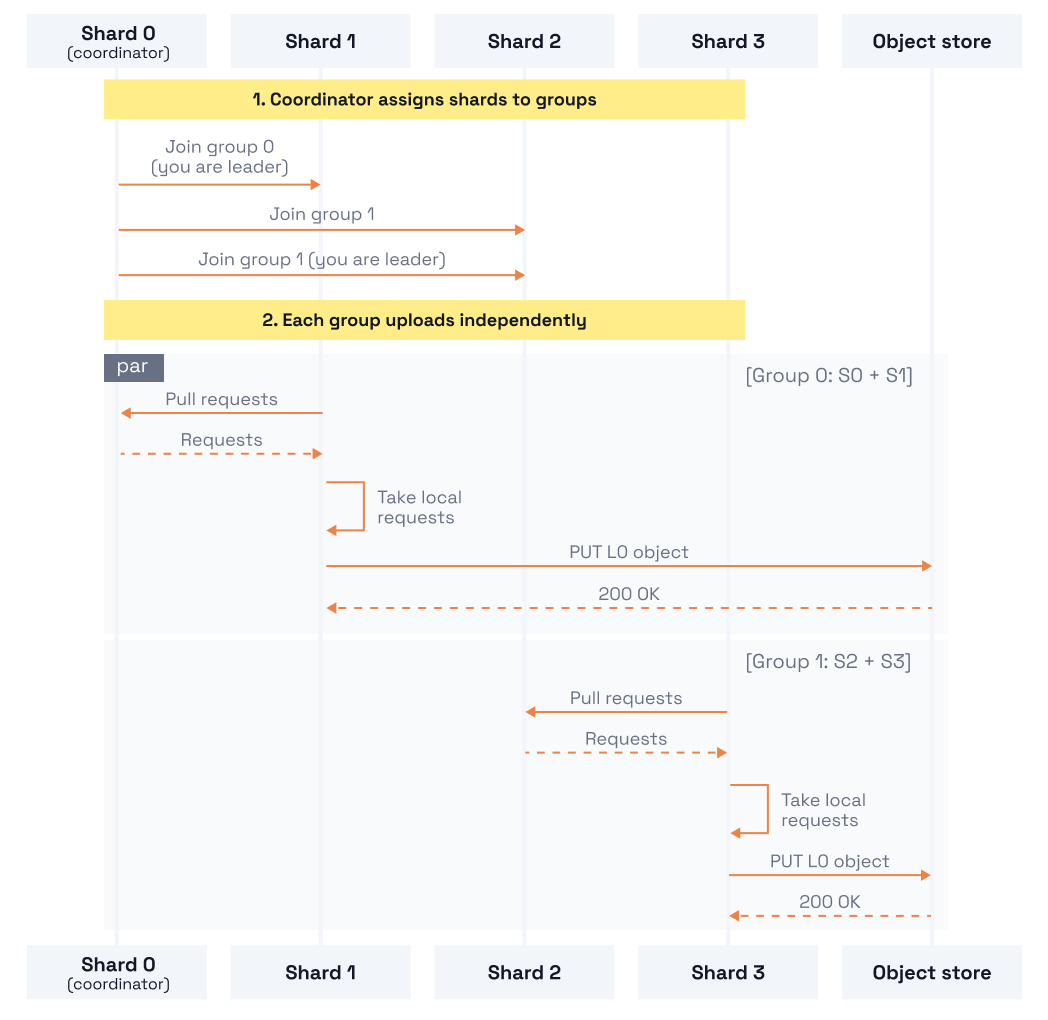
Both approaches above suffer from the same fundamental issue: a single shard makes decisions for all others, requiring it to synchronize with them. What if each group could make its own split/merge decisions using only locally observable state?
This question led us to the buddy allocator.
The buddy allocator is a memory management algorithm used in operating systems (and in Seastar). It maintains a pool of memory as a set of power-of-two-sized blocks. When an allocation needs a smaller block, an existing block is split in half. Each half is the other's "buddy." When both buddies are free, they merge back into the original block.
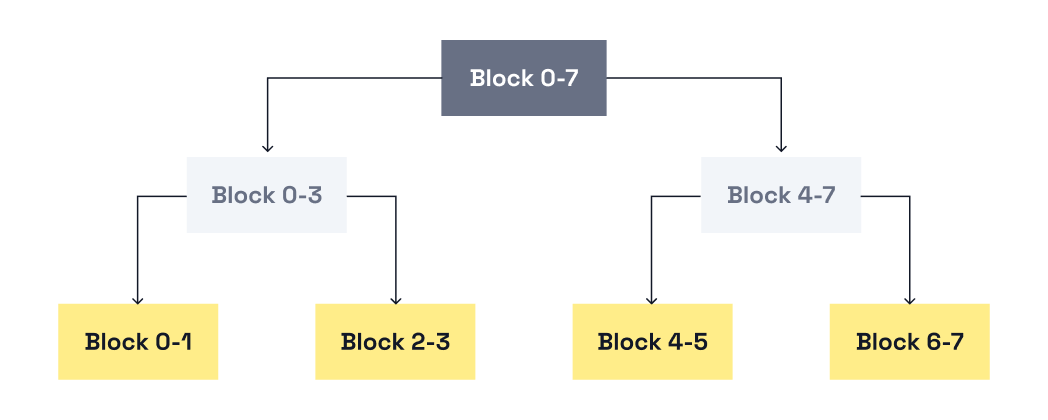
The property that matters for our use case is that split and merge decisions are local. A block only needs to know about its buddy, not about the global allocator state. Buddies are always adjacent and aligned to their size, so the relationship is implicit in the address without central bookkeeping or global locks.
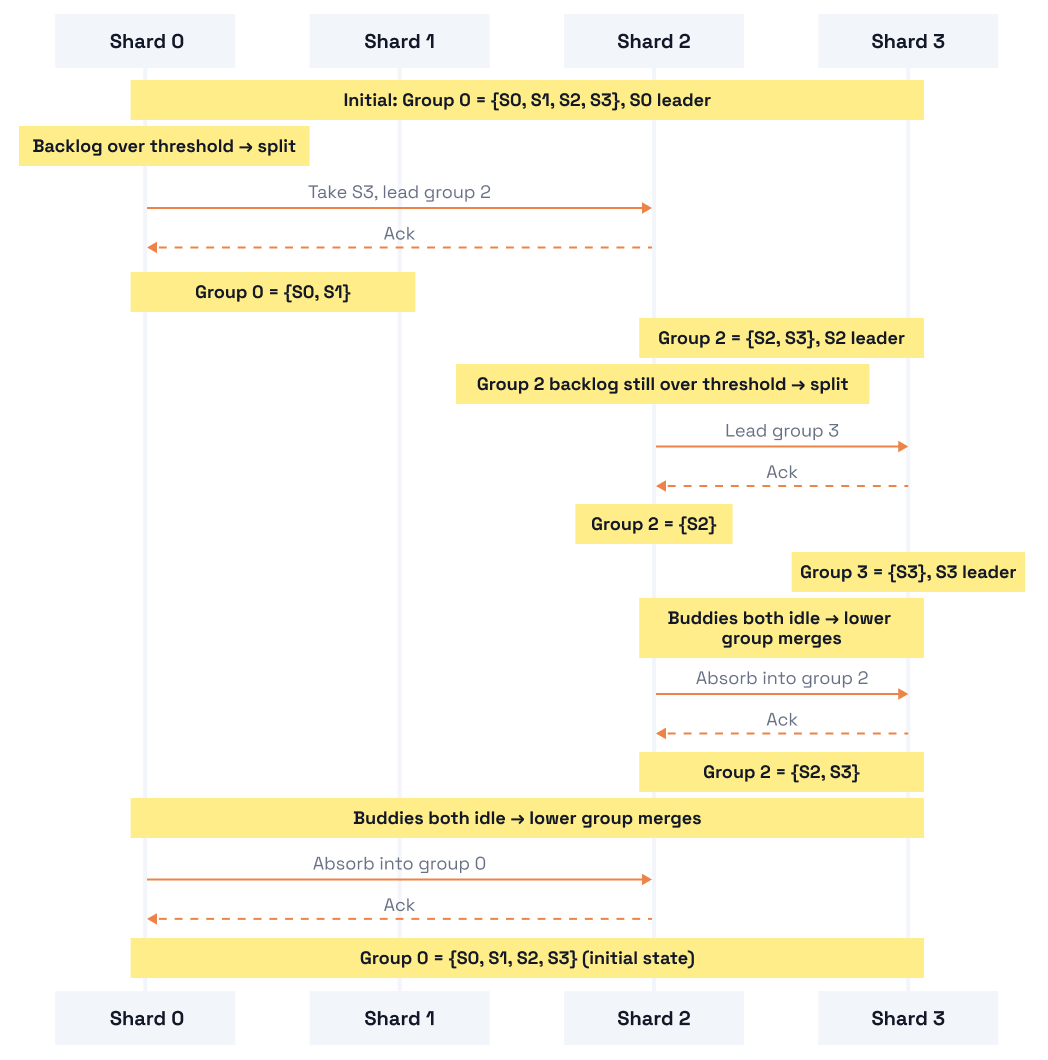
The scheduler organizes shards into groups. Shards within a group take turns uploading via round-robin. At startup, all shards form one group (maximum batching, a single upload stream).
The group leader (the first shard in the group) periodically checks the batcher's backlog. If the backlog exceeds a threshold proportional to the group's size, the leader splits the group in half. Each half becomes an independent upload stream with its own round-robin, doubling throughput. The new group's ID is simply the shard ID of its first member; no allocation and no coordination with other groups.
When both a group and its buddy have empty batcher backlogs, the lower-numbered group absorbs the buddy. Fewer groups mean larger batches and fewer PUTs. Only the lower group can initiate a merge, preventing two groups from racing to absorb each other.
The group assignment is an array mapping shard IDs to group IDs:
Initial (1 group): [0, 0, 0, 0, 0, 0, 0, 0] parallelism: 1x
After first split: [0, 0, 0, 0, 4, 4, 4, 4] parallelism: 2x
After further splits: [0, 0, 2, 2, 4, 4, 4, 4] parallelism: 3x
Maximum: [0, 1, 2, 3, 4, 5, 6, 7] parallelism: 8xThis is what makes the approach leaderless: no shard needs global knowledge. A group leader checks two things: its own group's batcher backlog and its buddy's. Both are readable via cache-line-padded atomic counters. The only shared mutable state is a per-group mutex, held briefly during the request-pulling phase but never during the S3 upload. A short hysteresis window between consecutive decisions prevents oscillation near threshold boundaries.
Under a lighter load, the system converges on a single group to maximize batching and minimize S3 overhead. Even in this single-group state, it handles substantial throughput. Under heavy load (many GiB/s), groups split until the batcher keeps up. When the load subsides, groups merge back. This happens continuously and without operator intervention.
The deeper lesson is architectural. The pipeline decouples what happens to a write from which shard does it, and that separation is what made the scheduler implementable as a small, local-only algorithm: a handful of atomic counter reads and a buddy-style state machine.
Now, we can add new pipeline stages without touching scheduling, and the scheduler can evolve without touching the batcher. Each stage does one thing, and the pipeline composes them, turning a hard coordination problem into an easy one.
If you want to learn more about Cloud Topics and how it works under the hood, here are a few links to browse:
A benchmark on how a single analytical query behaves as the dataset and cluster grow
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Fewer wasted CPU cycles and lower storage costs while keeping compaction correct
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.