




Apache Kafka's log compaction corrupts data. Here's how we fixed it
A detailed look at the bug we found and the compaction algorithm that solved it
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct









In our first post on Cloud Topics architecture, we walked through how Cloud Topics reimagines the Apache Kafka® write and read paths for cloud-native streaming. Today, we’ll be talking about a feature that can be tricky to implement well at scale: Kafka log compaction.
Compaction is a deceptively expensive operation. If a cluster is sized incorrectly, brokers can end up doing far more work than necessary, burning CPU cycles while disks fill up.
In this post, we cover how Redpanda’s Cloud Topics architecture enables smarter compaction, with less redundant work and fewer wasted CPU cycles, while still achieving massive savings in cloud storage costs and supporting all the Kafka properties users have come to rely on in traditional disk-based Kafka solutions.
If you're already fluent in compacted topics, feel free to skip ahead. For everyone else, here's the TL;DR:
A Kafka log consists of a sequence of records, each containing a key, value, offset, timestamp, and a collection of metadata headers. To prevent Kafka logs from growing indefinitely, retention policies can be configured using the topic-level property cleanup.policy. Many Kafka topics lend themselves to a delete retention policy, where records are removed from the log based on time or size-based limits.
However, a Kafka topic configured with cleanup.policy=compact deduplicates records by key within partitions, retaining at least the latest value for each key in the log. The definition of “latest value” here is dictated by the offset assigned by the broker to a record in the partition, though KIP-280 proposes enhancing compaction with alternative strategies to determine the "latest value".
Compaction also enables the deletion of keys through tombstone records, as well as the clean-up of control batches left behind by transactional workloads, which would otherwise bloat the log.
This isn't a niche feature. Compacted topics are the correct choice for many workloads:
Compacted topics also support several important internal topics:
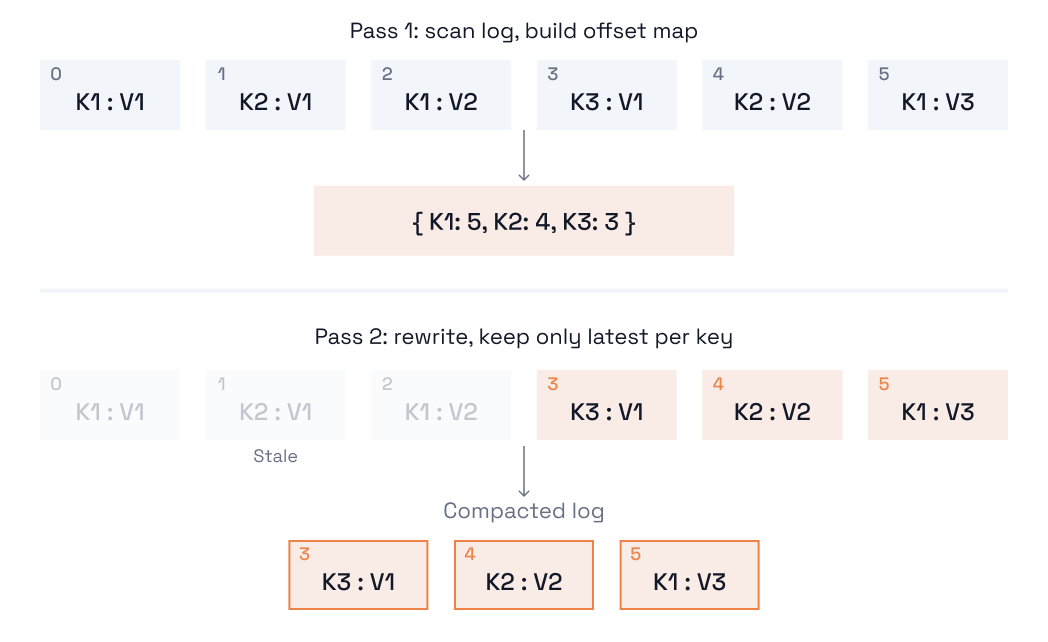
__consumer_offsets topic, every consumer group's position is a record, keyed by (group, topic, partition) _schemasThe basic algorithm is a fairly straightforward two-pass solution:
The real issue with compaction is having an implementation that scales without falling over. For example, what happens when not every key fits in memory? How do you handle the removal of tombstones? And, how should one deal with repeatedly rewriting potentially massive amounts of data held in object storage?
Psst! We found a bug in Kafka's compaction algorithm. Read the blog to learn how we fixed it.
We only have a finite amount of memory to work with, but partitions could contain an unbounded number of unique keys of varying sizes. Therefore, our key-offset map may only contain a subset of the total key space of the log, and on the granularity of a single compaction, it is impossible to guarantee a fully deduplicated log. This physical restriction is why the guarantees made by Kafka Compaction are somewhat loose, as described. In practice, however, a smart compaction implementation can guarantee eventually complete deduplication of all records and maintain an effective key-value store.
The first step to solving the memory problem is hashing. In Redpanda, we use a cryptographically secure and collision resistant SHA256 hash for keys when inserting them into our key-offset map, meaning the total size of one entry in the map is always a fixed 40 bytes (32 bytes for the hash and 8 bytes for a 64-bit integer offset). With a default allocation of 128MiB for our key-offset map, this means we can fit a grand total of slightly more than 3.3 million unique keys over one pass of the log.
The second step is proper bookkeeping of cleaned ranges in the log. These are offset ranges which have already had their records indexed and deduplicated with the prefix of the log before them in previous compaction runs.

A clever observation is that records which exist within these cleaned ranges do not need to be re-indexed in the key-offset map for future compactions. Another clever observation is that by performing the initial scan of the log over the dirty ranges backward, we can guarantee that the entry for any key indexed always has the latest offset. This enables us to stop our scan when we have either read all dirty ranges or our key-offset map is completely full.
For large partitions, the stopping criterion is usually the latter. Additionally, these clean ranges help us determine which tombstone records are discardable on rewrites of the log in the forward pass.
By codifying both of these learnings, in the steady-state, logs will converge to a fully deduplicated form over a finite number of compactions.
In traditional disk-based Kafka implementations, logs are replicated across brokers in a cluster according to their replication.factor to ensure availability and fault tolerance, meaning that the log's data physically exists in replication.factor number of places.
As a result, all brokers that host a replica of a compact-enabled log must individually perform compaction on their copy of the log to avoid filling disks and to efficiently serve consumers fetching from it. This redundant work is an unfortunate side-effect of replication that users pay for with wasted CPU cycles and overworked brokers.
The issue is only made worse when considering the other services a broker must provide (serving clients producing and consuming), and especially when using compression on compacted topics (leading to multiple decompressions and a single recompression of rewritten data during compaction).
Plus, this compaction effort is typically uncoordinated across brokers, which can lead to a very interesting race condition with tombstone removal, and a violation of the guarantees promised by Kafka mentioned earlier.
To recap, in traditional Kafka compaction, we suffer from a few issues:
Cloud Topics manages to alleviate all of these pain points. Recall from the architecture post that Cloud Topics decouples storage from the broker: committed data lives in object storage as immutable L1 objects, and replicated metadata (within our metadata service, the metastore) tracks which objects comprise each partition's log.
Compaction for cloud topics operates on this single shared copy of the log and the metastore rather than on local replica state. Because idempotency and transactions have already been handled in the L0 layer, compaction of L1 data need not concern itself with the removal of the aforementioned control batches.
This gives us numerous structural advantages. Because data is persisted once in object storage (not replicated across broker-local disks), compaction happens once against the canonical copy, removing any need for coordination across brokers. This also means that any broker (not just partition leaders!) can run compaction. In fact, any core (referred to as a "shard") on any node in the cluster is a potential compactor.
Redpanda is based on a shared-nothing architecture that pins partition state to specific cores per broker to make full use of modern hardware. And while this approach has its advantages and has made Redpanda the fastest streaming platform for years, it also comes with limitations that must be understood and accounted for.
For example, deciding which partitions a certain shard should host is a tricky matter. Redpanda uses partition auto balancing to ensure a fairly even spread of partitions across a broker's shards (and, at a higher level, an even spread of partitions across brokers themselves in a cluster).
However, at certain scales, it is impossible to guarantee that two heavily compactible partitions will not end up hosted on the same shard. In a naive scheduling implementation, this could cause shards to compete for CPU cycles during compaction, quickly leading to compaction starvation, large partitions, and full disks.
Luckily, with compaction for cloud topics, we have a bit more freedom with our scheduling approach. Instead of tightly coupling compaction work with shard placement of partition leaders, a compaction scheduler (running on shard 0 of each compaction node) maintains a priority queue of partitions this node is responsible for compacting.
This queue's heuristic is based upon existing Kafka concepts, such as the dirty ratio (in which logs are made eligible for compaction by comparing the number of dirty and total bytes in a log against the topic’s configured min.cleanable.dirty.ratio) and the time that has elapsed since written data has become eligible for compaction (the max.compaction.lag.ms).
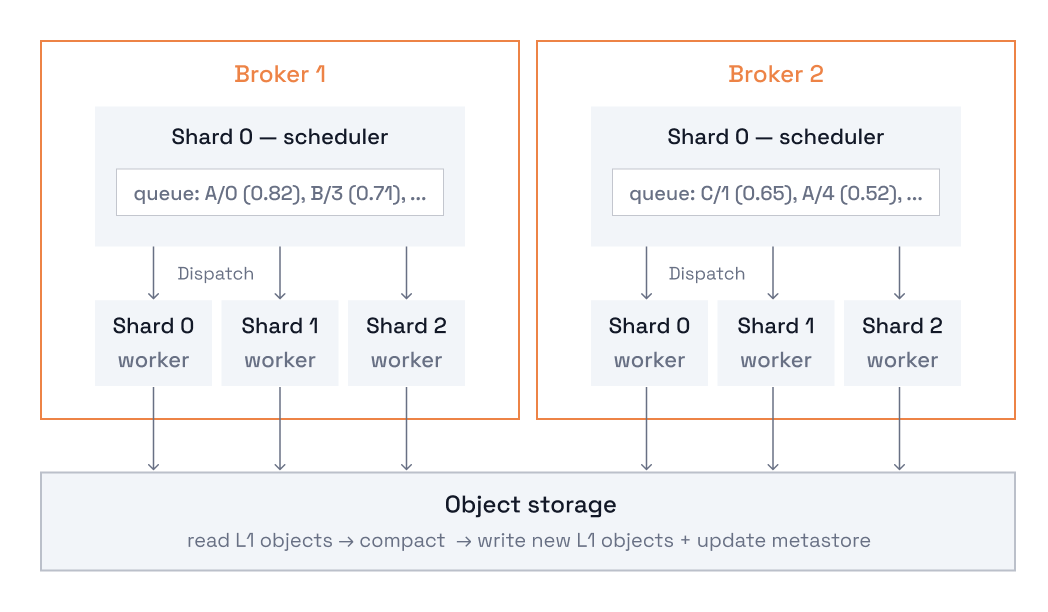
Compaction workers run on every shard of every compaction node. Using a pull-based model, each worker polls the scheduler for work and runs the compaction pipeline on whichever partitions the scheduler has detected are eligible for compaction. The compacted Kafka data is written via multi-part uploads to object storage, and a compaction metadata update is built up for the metastore and committed atomically.
Multi-part uploads allow us to scale the required amount of memory usage with part size instead of with the total size of the L1 object being uploaded. This is also a win because it means we don’t need to spill L1 objects to disk before uploading them. Multi-part uploads are supported by all the object storage vendors that Redpanda natively supports. Optimistic concurrency is enforced in the metastore via an integer compaction_epoch, (which is incremented upon every successful update application), to prevent any race conditions that could potentially result in stale data being re-added to the log.
If, for example, two nodes were scheduled to compact the same log, a simple check of the compaction_epoch is enough to determine whether we should accept or reject incoming compaction updates. In the happy path, the log’s data is rewritten to the cloud, new objects are registered with the metastore, and future compactions can continue through the rest of the log’s dirty ranges.
For more details on the metastore and the replicated LSM that backs it, check out our blog on how we built our own metastore for Redpanda Cloud Topics.
Compaction is an expensive operation that Kafka brokers can easily overwhelm themselves with if clusters are sized incorrectly. In traditional disk-based Kafka implementations, this quickly leads to full disks and red-hot CPUs. With Redpanda’s Cloud Topics, compaction has been designed to be flexible, simple, and correct.
If you want to try Cloud Topics today, start your free trial of Redpanda Cloud. If you’re keen to learn more before you dive in, check out the rest of our Cloud Topics series.
A detailed look at the bug we found and the compaction algorithm that solved it

Solving a Kafka problem to balance batching efficiency against latency and cost
The metadata tier and how we built our own key-value store into Redpanda for durability and scale
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.