




How Redpanda Cloud Topics rethinks Kafka compaction
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct
When to hold, when to delete: inside Redpanda's L0 garbage collection









Instead of developers manually tracking and deleting unused data, a garbage collector scans for objects that are no longer needed and cleans them up. The challenge is timing: act too soon and you delete something still in use, act too late and you waste resources.
In a previous post, we introduced the architecture of Redpanda Cloud Topics, which covered how incoming data is batched into Level Zero (L0) objects, how metadata is persisted through the same Raft layer as non-cloud-topic data, and how the reconciler reorganizes that data into read-optimized Level One (L1) objects.
These L1 objects become the source of truth for historical reads. They are larger and offer per-partition spatial locality that's not available in the smaller, temporally batched L0 objects. The L0 objects themselves are temporary by design, so the goal of L0 garbage collection is to identify and remove them as soon as the reconciler finishes with them, but no sooner. After all, the simplest form of garbage collection routes everything to /dev/null.
Read on to learn how Redpanda tracks the flow of temporary objects through Cloud Topics and determines when they’re safe to remove.
Consider an L0 object O comprising data from partitions {p0, p1, p2}. To a first approximation, it resembles any other shared, read-only resource. We can think of each chunk of unreconciled data as a "reference" to the object, and the object is safe to delete only once the number of references reaches zero (i.e., the reconciler has lifted all enclosed data to L1).
Simple enough, but this framing belies an ocean of complexity.
First, these reference counts must be durable. Partitions themselves are spread across the cluster to balance load, so we'll need to support updates from anywhere. Do they need to be linearizable? Reference count updates are tightly correlated with the partition-local state that reconcilers use to make progress. Maybe they need to be atomic then? Would we be satisfied with eventual consistency? These are real questions about distributed systems design.
This is a good time to mention that Redpanda does not track L0 objects this way. Instead, we assign an "epoch" to every object in L0 (think of it as a coarse-grained logical timestamp) and leverage carefully structured per-partition state to construct a global view of which L0 objects are safe to remove. No central index, no shared state, and no coordinated updates.
The cluster epoch is a monotonically increasing counter that we embed in every L0 object ID at creation time. Since the epoch is updated periodically and only ever increases, any given epoch E must eventually age out of the cluster. Once we have reconciled every object created in epoch E, it stands to reason that any L0 object with that epoch can be safely deleted. The rest of the GC system is built on this observation.
So we're left with a somewhat more refined goal: find an epoch M that is safe to GC. But this is still non-trivial as Redpanda is a distributed system. For example, if a partition's leadership changes, ingress might resume on a different node whose cached epoch could be out of date.
Given an oracle M(p) that gives the safe-to-GC epoch for any Cloud Topic partition, we can construct an aggregate M that's globally safe-to-GC.
The aggregate M is easy to construct:
P={p0,...pn} and safe epochs Ms=min(M(p) over p in P)M=min(Ms) is safe to GC by epoch monotonicity and the definition of minThis is an intuitive result. Once an epoch is inactive everywhere, it's safe for GC anywhere. So all we need is a source of truth M(p) and machinery to apply a global minimum, and we can derive the desired M.
Short of coordinating in-progress writes at the cluster level, we should be able to track each partition's safe-to-GC epoch directly in the Raft log. That is, local to the partition. To support the lazy aggregation scheme described above, the result should be both monotonic and always valid. That is, staleness should not invalidate any previous result.
Our initial design tracked a single epoch per partition, the max across all produced placeholder batches, and rejected anything older on the replication path. This trivially supports both invariants, but it's too strict in practice. If partition leadership moves to a node with a stale epoch cache, we’ll reject every new write until cache expiry, which could be minutes away. Not ideal.
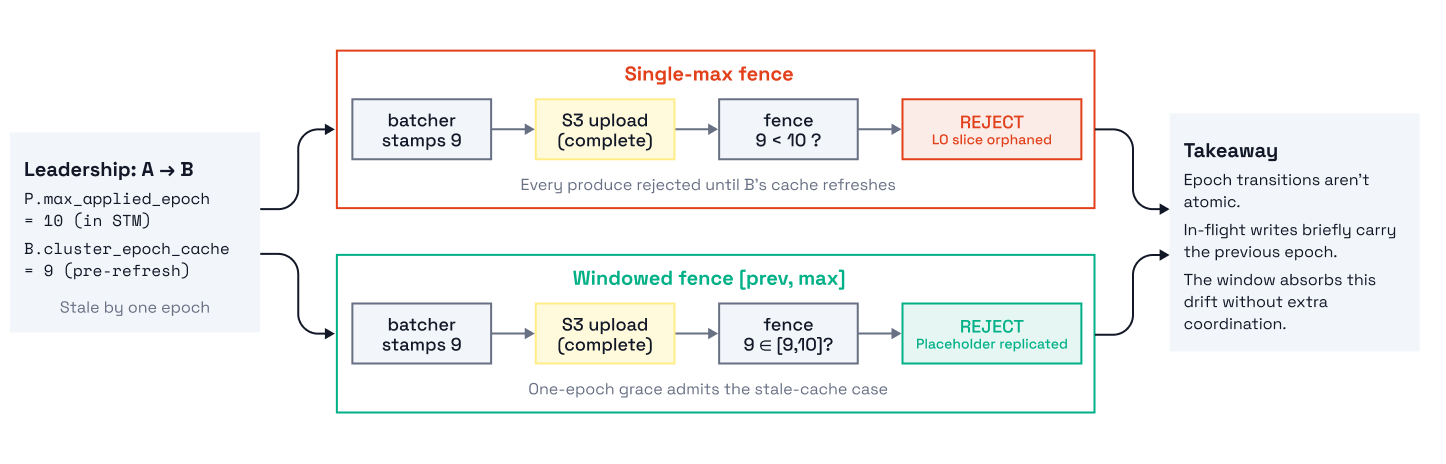
Rather than approaching this as a distributed cache coherence problem (hard!), we can bake resilience to this epoch lag right into the algorithm. Local to each partition, we maintain a sliding window of active epochs. When we see a new epoch for the first time, slide the window forward. We still get monotonicity by construction, but we gain some flexibility to accept writes that were in flight when the window moved.

Each Cloud Topic partition maintains this sliding epoch window through a dedicated replicated state machine embedded in the partition’s Raft log. The most important bits of state are as follows:
As discussed, [previous_applied, max_applied] describes the range of active epochs we expect to see, and anything below this range is rejected before entering the replication pipeline. M(p) is simply prev(min_epoch_lower_bound).
Note that the computation of M(p) is actually a bit stricter than what we described before; that’s because reconciler progress gives the final word on which epochs are safe to delete. So while the window itself slides forward as soon as a new epoch appears, we only advance the safe epoch once we’re sure all the L0 data up to that point has been reconciled into L1.
MNow that every Cloud Topic partition p tracks an inactive epoch in its own Raft log, all that’s left is to combine these into a single global M. Turns out we can piggyback this information on an existing periodic metadata-dissemination service internal to Redpanda.
If a node is temporarily operating on stale metadata, that’s fine. A nice side effect of epoch monotonicity is that once we prove some M is safe, it never becomes unsafe. Every epoch <M is gone forever. Or until int64 rollover.
In any system, garbage collection must strike a balance between safety, timeliness, and scale. We've now laid the groundwork for L0 garbage collection with per-partition epoch tracking, but that's only part of the story. Once we know which epochs are safe to delete, we then have to go and delete them. Stay tuned for part 2, where we discuss how the garbage collector's design enables us to continually delete thousands of L0 objects without any locally persistent state, explicit coordination, or wasted work.
In the meantime, you can try Cloud Topics in Redpanda 26.1 with an Enterprise trial. If you’re keen to learn more about Cloud Topics and how Redpanda works under the hood, here are a few links to browse:
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct

A detailed look at the bug we found and the compaction algorithm that solved it

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.