
Redpanda SQL
Query everything. Including the last millisecond.
Analyze data in both Redpanda topics and Apache Iceberg tables in a simple SQL statement. No data movement. No pipelines. No waiting.
Your analytics tools are constantly playing catch-up.
The pipeline always has a price.
Before your analysts can query streaming data, someone has to build the ETL pipeline, configure the Kafka Connect sink, deal with schema mapping, and own it when it breaks. That's the pipeline price: weeks of engineering overhead before anyone touches a dataset.
Two systems. Zero unified view.
Keeping streaming and lakehouse data aligned means checkpointing, gap detection after job failures, duplicate handling, and ongoing job monitoring. Two systems don't just complicate queries. They create operational toil and a tax to pay before analysis can start.
Nobody likes the debugging workaround.
Debugging a streaming app or chasing a data quality issue means either writing code, or exporting topic data to a file and parsing through it by hand. Every engineer who's done it has thought the same thing: this could have been a SQL query.
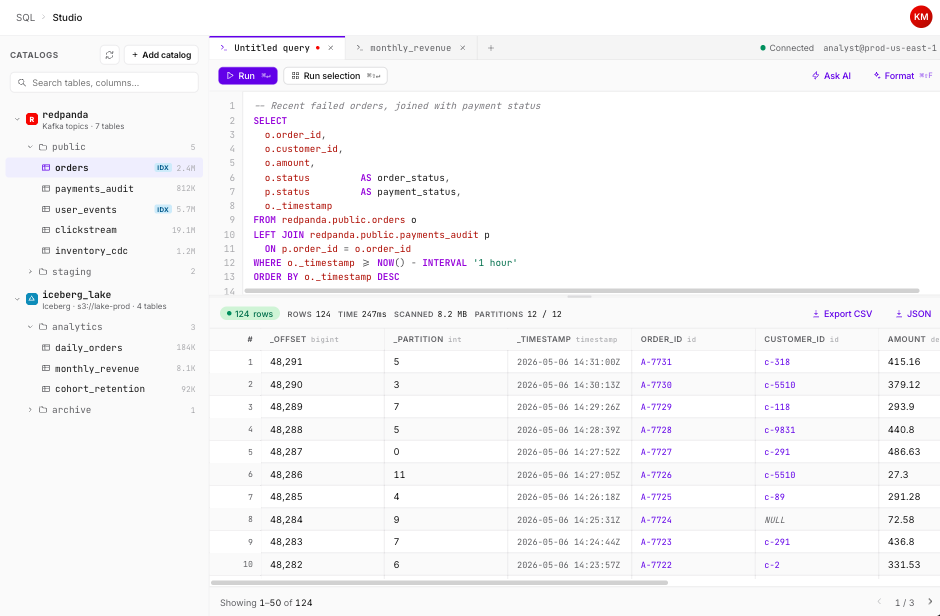
One query. Live real-time topics + Iceberg history. No mess.
Redpanda SQL is a Postgres-compatible analytical query engine that reaches across Redpanda streams and your existing lakehouse, without moving a single byte outside your network.
SQL your team already knows.
Redpanda SQL speaks the Postgres SQL dialect and wire protocol. Almost any standard SQL client connects without modification: psql, DBeaver, DataGrip. No unfamiliar query syntax or semantics.
No pipeline. No lag.
Redpanda SQL queries data in place. No ETL. No connector to babysit. No manual deduplication. Results from data that arrived milliseconds ago seamlessly fused with last year’s data.
Stays inside your network.
Redpanda SQL runs inside your Bring Your Own Cloud (BYOC) cluster, on the same infrastructure as your Redpanda Streaming brokers. Every query executes in place. Nothing leaves your perimeter.
Redpanda SQL queries data in place. No ETL. No connector to babysit. Results from data that arrived milliseconds ago.
Redpanda SQL does four jobs your warehouse can't do.
Operational analytics
Query what's happening now alongside the full historical record. Immediate data freshness. One SQL statement. No pipelines. No data movement.
End-to-End governance & compliance
Regulated data that can't leave your environment can now be queried inside your VPC with BYOC deployment. No separate SaaS provider. No data egress.
Topic debugging
Malformed events, missing fields, poison pills — skip the scripts. Query your live topics with SQL and diagnose the culprit in your code in minutes, not hours.
AI agent workloads
Agents fan out across data sources, issuing hundreds of SQL queries in parallel. Feed them live data, not an old snapshot. Their answers match reality.
The Redpanda Data Platform
Stream, connect and query. One vendor.
Three products. One architecture. One operational model. One vendor.
Stream
GBs/sec throughput, built in C++. The substrate for every Redpanda service.
Connect
Hundreds of connectors. Filter, enrich, route, and transform messages between any two systems.
Query
Ad-hoc SQL across live topics and Iceberg history. No pipeline required.
The pipeline approach vs. Redpanda SQL
Redpanda SQL is not a replacement for your existing analytics stack. Snowflake stays. Databricks stays. Redpanda SQL covers what they can't reach.

What You Need | The Pipeline Approach | Redpanda SQL |
|---|---|---|
| Data freshness | 1–10 min lag from pipeline ingest | Milliseconds fresh, query data as it arrives |
| Coverage | Cold tier only (what made it to the warehouse/lakehouse) | Hot + cold unified, live topics and full Iceberg history |
| Pipeline burden | Build, deploy, monitor, maintain a connector or ETL/streaming job | No pipeline required, query directly |
| Analyst access | Requires pipeline to be built first | Almost any Postgres client, accessible with familiar PostgreSQL |
| AI agent query model | Batch-oriented / stale data, or bulky, per-query streaming jobs | Hundreds of parallel SQL queries against live data |
| Data governance | Data must egress to an external SaaS provider | Query in place, within your VPC |
FAQ: Redpanda SQL
Redpanda SQL is a Postgres-compatible analytical query engine that runs inside your Redpanda BYOC cluster. It gives you direct SQL access to live data in your Apache Kafka-compatible Redpanda Streaming topics and historical data in Iceberg tables, combined in a single table/query, without pipelines or new infrastructure to provision. It performs a single federated query across both and combines the results seamlessly and accurately. Connect using almost any standard Postgres client and start querying immediately.
Warehouses can only query data that's already been explicitly ingested, which requires a data engineer and typically adds 1–10 minutes of pipeline lag (or longer, for some infrequent batching jobs). Redpanda SQL automatically and transparently queries live streaming data and historical Iceberg data in a single, simple statement. No data engineering, complicated joins or union logic. It covers what your warehouse can't reach.
No. Redpanda SQL is fully ad-hoc: connect your Postgres client and query any topic, any time, with no pipelines or pre-defined views. This separates Redpanda SQL from tools like ksqlDB, which creates separate materialized views and requires additional infrastructure.
Redpanda SQL uses the Postgres wire protocol, so almost any standard Postgres-compatible SQL client connects without modification: psql, DBeaver, DataGrip, and most analytics tooling that supports the Postgres interface. No proprietary drivers, no new SDKs, no obscure query syntax or semantics (like with FlinkSQL), and no special configuration required.
No, Redpanda SQL is additive. Snowflake and Databricks handle the workloads they're designed for. Redpanda SQL covers what they can't: streaming data still in your topics before lakehouse ingestion, queried inside your own VPC without egress charges or compliance issues.
Iceberg Topics is a Redpanda Streaming feature that writes streaming data to both a hot tier (the live Redpanda topics on local storage) and a cold tier (Parquet/Iceberg in S3 or GCS). At this time, Redpanda SQL queries Iceberg tables written by Redpanda Iceberg Topics specifically — not external Iceberg tables populated by other tools. Standard Redpanda topics work fine without Iceberg for SQL use cases like topic debugging and real-time analytics.
Redpanda SQL is not built on PostgreSQL. It's built on the MPP (Massively Parallel Processing) engine technology that Redpanda acquired from Oxla, written from the ground up in C++ including many novel query engine innovations. The engine speaks the Postgres wire protocol natively, which is why standard clients like psql and DBeaver connect without modification.
It's designed for large-scale analytical workloads with strong data compression and cost-efficient scaling, and is managed entirely by Redpanda — no separate Oxla relationship or additional configuration required. The Oxla engine's novel ring-buffer streaming shuffle allows it to maximize CPU usage, especially at large core counts. Its design is described in a peer-reviewed paper, conditionally accepted for publication at VLDB 2026, one of the premier academic conferences for database systems research.
No. Since Redpanda SQL is only Postrgres wire-compatible, but does not otherwise share the same Postgres code base, you cannot employ extensions with it, such as PostGIS or pgvector.
Redpanda SQL is generally available today on Redpanda BYOC on AWS. GCP support is coming soon. Self-managed / on-premises deployment is targeted for 2H FY2027. Reach out to your Redpanda account team for current availability or to join the waitlist for upcoming deployment options, including Azure.

Your data is already there. Now you can query it.
Activate SQL on your existing cluster: no new infrastructure, no new vendor relationship, usage-based billing. Redpanda SQL is available now on Redpanda BYOC.