





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
.png)
How to write messages from Redpanda to its own JSON file in an S3 bucket








In part one of this series, we built a Redpanda Connect pipeline that streamed CSV data from S3, cleaned it, and wrote it into a Redpanda Serverless topic. However, what if we wanted the reverse: streaming data into Amazon S3 (maybe for analytics, archival, or interoperability)?
Redpanda Connect makes it just as easy to export data to S3 as it does to ingest from it. Kafka Connect has long been a go-to tool for streaming data pipelines. Redpanda Connect takes a different approach, offering a streamlined and efficient way to handle your data pipelines.
In this second post, we’ll show how to take messages from a Redpanda topic and write each one to its own JSON file in an S3 bucket. This format is ideal for small datasets, debugging workflows, or any process that expects discrete JSON files.
We’ll walk through:
This assumes you read the previous tutorial on bringing data from S3 into Redpanda Serverless, and have already deployed a Serverless cluster with a topic called clean-users.
If you’re a visual learner, watch this 1-minute video to see how it’s done.
To follow along step-by-step, read on.
This approach will write each message from the clean-users topic as an individual JSON file in S3. While this might not be ideal for very large datasets in production, it's a clear way to see the basic data flow and can be useful for debugging or smaller archives.
See the first post, Redpanda Connect pipeline that streamed CSV data from S3, for an example data stream to use with this tutorial.
From within the context of your cluster, deploy this example Redpanda Connect YAML configuration as a Redpanda Connect pipeline. You'll need to update the input and output sections according to your own settings.
input:
redpanda:
seed_brokers:
- ${REDPANDA_BROKERS}
topics:
- clean-users
consumer_group: s3_consumer_stream
tls:
enabled: true
sasl:
- mechanism: SCRAM-SHA-256
username: ${secrets.REDPANDA_CLOUD_SASL_USERNAME}
password: ${secrets.REDPANDA_CLOUD_SASL_PASSWORD}
output:
aws_s3:
bucket: brobe-rpcn-output
region: us-east-1
tags:
rpcn-pipeline: rp-to-s3-json-single
credentials:
id: ${secrets.AWS_ACCESS_KEY_ID}
secret: ${secrets.AWS_SECRET_ACCESS_KEY}
path: stream_view/${!counter()}-${!timestamp_unix_nano()}.json
content_type: application/jsoninput.redpanda.consumer_group: This helps Redpanda keep track of which messages have been processed. It allows you to have multiple Redpanda Connect pipelines reading from separate pointers into the data stream.path: stream_view/${!counter()}-${!timestamp_unix_nano()}.json: This is where the magic of dynamic pathing happens. Redpanda Connect uses built-in !functions to generate unique file names automatically. !counter() gives an incrementing number, and !timestamp_unix_nano() provides a precise timestamp, ensuring unique file paths.When you deploy this, you'll see individual JSON files appear in your S3 bucket, each containing a single message from your Redpanda topic.
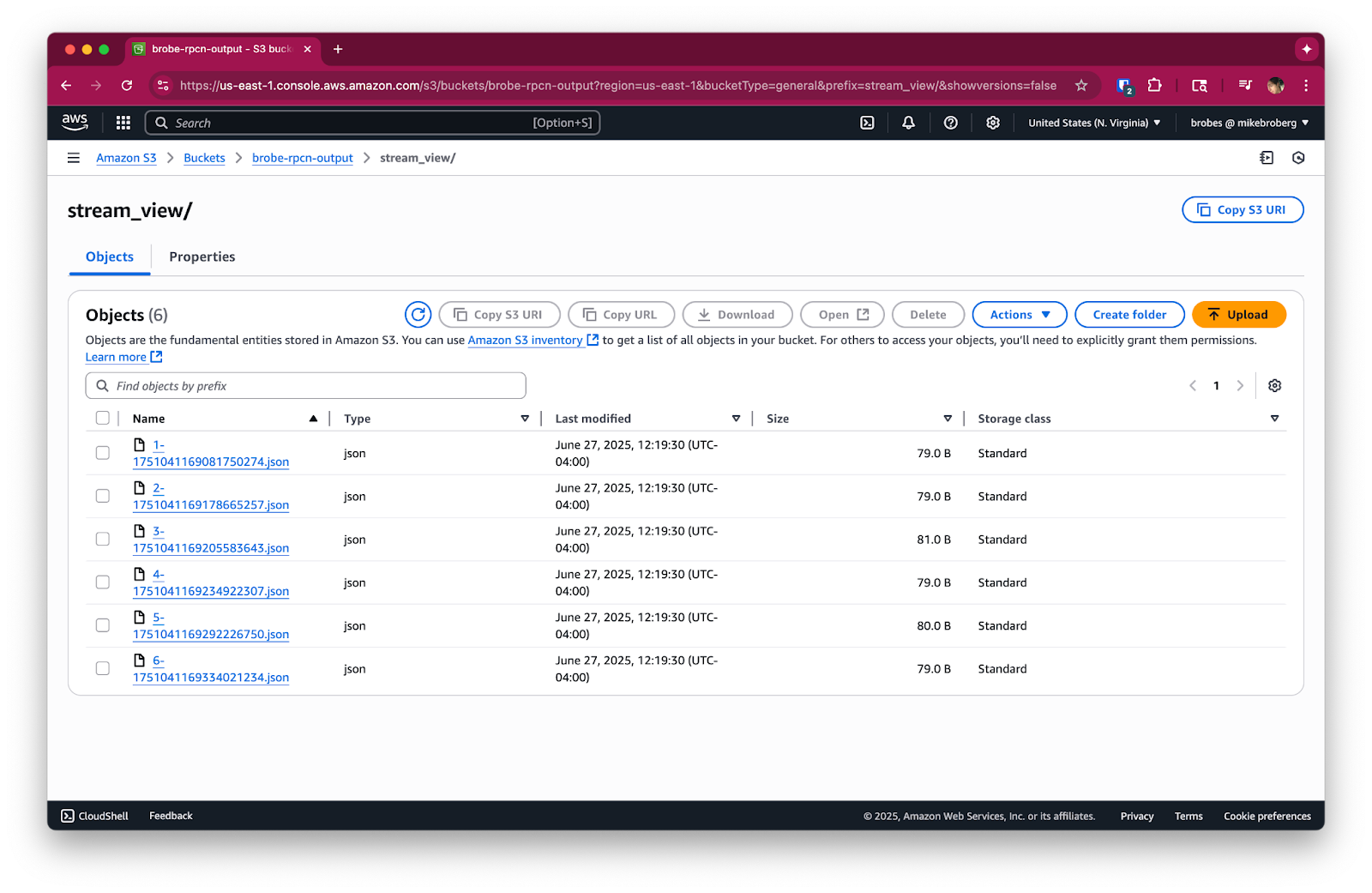
Since this pipeline continuously listens to a Redpanda topic, it will keep running until you stop it. To avoid any unneeded charges, please be sure to stop any running Redpanda Connect pipelines and delete your Redpanda streaming topic when you're done using them. If you were running tests or using a temporary bucket, it’s also a good time to clean up old objects in S3.
This pattern works well for small or debug-focused use cases, but when you start handling production-scale throughput, writing one file per message becomes inefficient.
In our next post, we take this same Redpanda to S3 flow and adapt it to batch multiple messages together, reducing the number of files, improving write performance, and creating cleaner archives. Here's the full series to make it easier.
If you have questions about this tutorial, hop into the Redpanda Community on Slack and ask away.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

