





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
.png)
How to integrate Amazon SQS and S3 notifications to build event-driven pipelines








In this five-part series, we’ve covered how to get data into Redpanda from S3, clean it, and send it back out again in different formats: from raw JSON to Parquet. But what if you want to automate your workflows? Instead of running a pipeline on a schedule, you can trigger processing the moment new data lands in S3.
That’s where S3 Event Notifications and Amazon SQS come in.
You can configure your S3 bucket to send notifications to an SQS queue whenever new objects are created (or other events occur). Redpanda Connect can then listen to this SQS queue, receive these event notifications, and automatically process the newly uploaded S3 objects.
This is a fantastic way to build real-time, event-driven data pipelines directly from your object storage. So, in this fifth and final post of the series, we’ll show you how to do precisely that.
We’ll walk through:
This assumes you’ve deployed a Redpanda Serverless cluster and created a topic called clean-users (see part one, bringing data from S3 into Redpanda Serverless, if you haven’t already).
If you’re a visual learner, watch this 1-minute video to see how it’s done.
To follow along step-by-step, read on.
Deploy this example Redpanda Connect YAML configuration as a Redpanda Connect pipeline from within your cluster. You'll need to update the input and output sections according to your own settings.
input:
aws_s3:
bucket: brobe-rpcn-input
region: us-east-1
credentials:
id: ${secrets.AWS_ACCESS_KEY_ID}
secret: ${secrets.AWS_SECRET_ACCESS_KEY}
scanner:
csv:
parse_header_row: true
sqs:
url: https://sqs.us-east-1.amazonaws.com/194252440051/brobe-queue
pipeline:
processors:
- mapping: |
root = this
root.action = this.action.uppercase()
root.user_id = this.user_id.number()
if this.exists("ssn") {
root.ssn = true
} else {
root.ssn = false
}
output:
redpanda:
seed_brokers:
- ${REDPANDA_BROKERS}
sasl:
- mechanism: SCRAM-SHA-256
username: ${secrets.REDPANDA_CLOUD_SASL_USERNAME}
password: ${secrets.REDPANDA_CLOUD_SASL_PASSWORD}
topic: clean-users
tls:
enabled: trueHere's how this automated flow works:
input.aws_sqs component in our YAML will continuously poll your specified SQS queue for new messages.sqs.key_path and sqs.bucket_path configs.aws_s3 input is the same as those used in previous examples.This pattern is incredibly powerful for building robust, automated data ingestion pipelines directly from S3, without any manual intervention. It's the ultimate "set it and forget it" solution for getting your object storage data into your real-time Redpanda streams.
Now, let's take one more CSV file and upload it into our S3 bucket as mini-clickstream-SSN-sqs.csv:
user_id,ssn,timestamp,action
777,666-77-8888,2025-06-01T12:00:00Z,sleep powder
888,333-44-5555,2025-06-01T12:01:00Z,confuse ray
999,000-11-2222,2025-06-01T12:02:00Z,stun spore
And we can see the new, processed messages land instantly in our Redpanda topic.
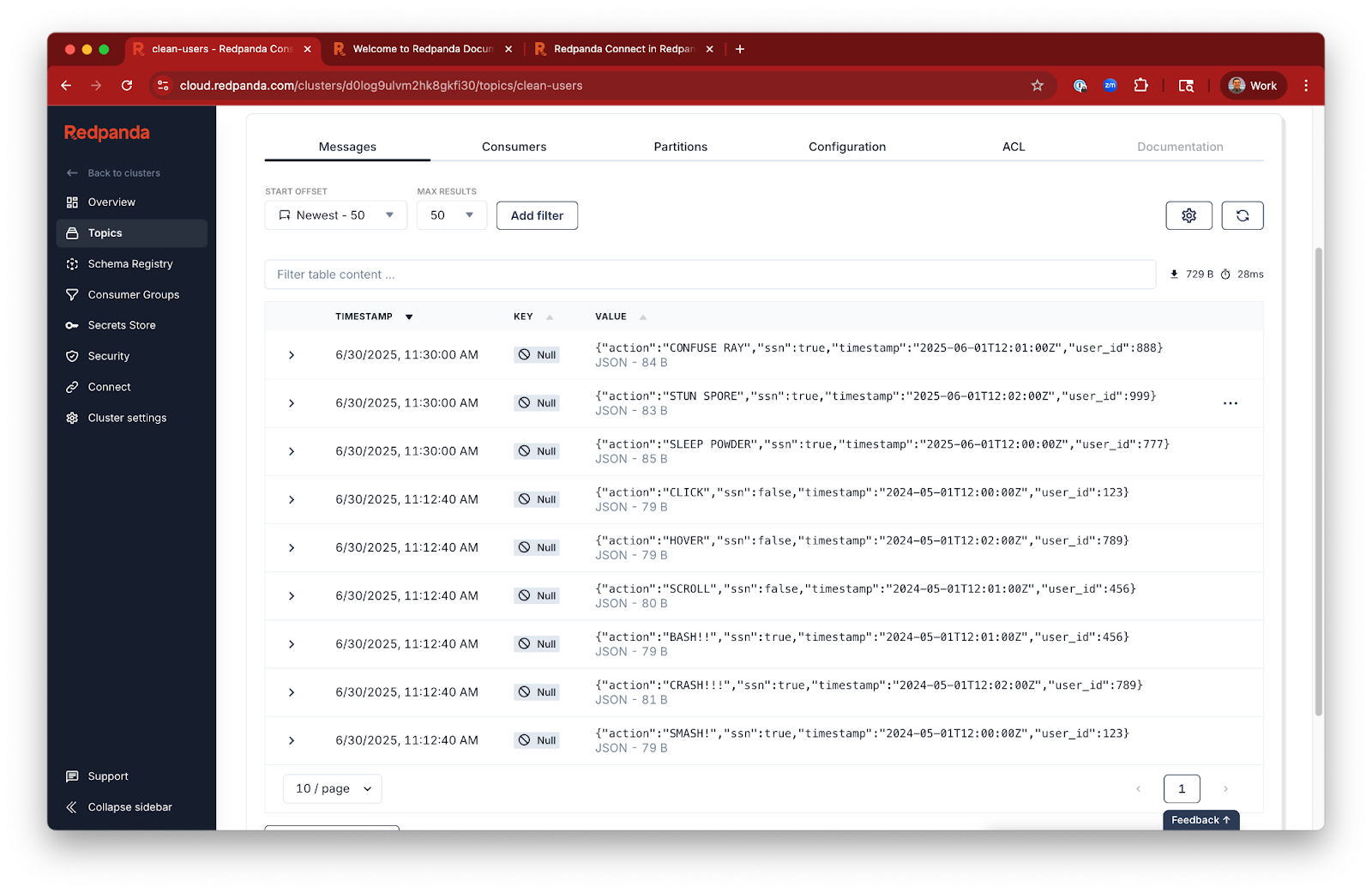
This pipeline runs continuously to listen to SQS. To avoid any unneeded charges, don’t forget to:
And that concludes our Redpanda + Amazon S3 series! So, what now? If you're ready to stop writing glue code and start building real-time pipelines in minutes, give Redpanda Serverless a spin. No infra to manage. No Kafka to wrangle. Just stream in, stream out, and get back to building.
Sign up for Serverless or hop into our Redpanda Community Slack if you have questions.
Check out the whole series:
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

