





Full CDC semantics land in the Iceberg output for Redpanda Connect
Your lakehouse mirrors the database, instantly.
.png)
Stream and transform CSV data with zero custom infrastructure








This blog provides a step-by-step guide on how to use Redpanda Connect to ingest CSV files from an S3 bucket, normalize and clean up the data (including stripping sensitive fields), and then publish the results to Redpanda for downstream processing. This creates a working data pipeline that runs continuously and can be deployed in minutes.
Redpanda Serverless integrates with its built-in secrets store, eliminating the need to hardcode sensitive credentials. For instance, placeholders like ${secrets.AWS_ACCESS_KEY_ID} and ${REDPANDA_BROKERS} are used, where ${REDPANDA_BROKERS} is a special environment variable that grabs your broker addresses from within the context of your cluster.
Bloblang is a powerful and concise language built into Redpanda Connect that is used to define how data should be processed. For instance, it can be used to directly convert user_id to a number and apply conditional logic to the ssn field. This "shift left" approach to data preparation is very efficient.
To avoid unnecessary charges, make sure to stop any running Redpanda Connect pipelines and delete your Redpanda streaming topic when you're done using them. Future pipelines will run continuously if they are listening to Redpanda streaming topics or to event notifications from AWS.
This blog mentions several transformations that can be applied when ingesting data into Redpanda. These include reading the CSV files efficiently, converting the user_id field to a number, changing the action field to UPPERCASE for consistency, and replacing any existing ssn field with a simple boolean flag to avoid storing sensitive data directly in the stream.
Teams often store logs and event data in Amazon S3. That data is valuable, but locked in a format that’s difficult to operationalize for real-time use. If you want to drive live dashboards, trigger alerts, or feed AI pipelines, you need a way to turn that cold, static data into a live stream.
Kafka Connect has long been a go-to tool for streaming data pipelines. Redpanda Connect takes a different approach, offering a streamlined and efficient way to handle your data pipelines. It’s designed for flexibility and performance, giving you a powerful yet approachable tool for data integration.
This post shows how to use Redpanda Connect to stream and transform CSV data from S3 into a Redpanda Serverless topic. We’ll walk through:
By the end, you’ll have a working data pipeline that runs continuously and can be deployed in minutes!
If you’re a visual learner, watch this 1-minute video to see how it’s done.
To follow along step-by-step, read on.
First, make sure you’ve deployed a Redpanda Serverless cluster and, within it, created a topic called clean-users:

Now, imagine you have some precious clickstream data stored in some log files, just lounging about in an S3 bucket, feeling neglected. Your mission: Scoop it up, clean it, and stream it into a Redpanda topic for real-time analysis.
Suppose your S3 bucket, brobe-rpcn-input, contains CSV files like these:
mini-clickstream.csv
user_id,timestamp,action
123,2024-05-01T12:00:00Z,click
456,2024-05-01T12:01:00Z,scroll
789,2024-05-01T12:02:00Z,hoverAnd, perhaps another file that includes sensitive information:
mini-clickstream-SSN.csv
user_id,ssn,timestamp,action
123,111-22-3333,2024-05-01T12:00:00Z,Smash!
456,444-55-6666,2024-05-01T12:01:00Z,Bash!!
789,777-88-9999,2024-05-01T12:02:00Z,Crash!!!We want to ingest this data into Redpanda, but with a few important transformations:
user_id field to a number.action field to UPPERCASE for consistency.ssn field exists, we want to replace it with a simple boolean flag (true or false) to avoid storing sensitive data directly in our stream.From within the context of your cluster, deploy this example Redpanda Connect YAML configuration as a Redpanda Connect pipeline. You'll need to update the input and output sections according to your own settings.
input:
aws_s3:
bucket: brobe-rpcn-input
prefix: input/
region: us-east-1
credentials:
id: ${secrets.AWS_ACCESS_KEY_ID}
secret: ${secrets.AWS_SECRET_ACCESS_KEY}
scanner:
csv:
parse_header_row: true
pipeline:
processors:
- mapping: |
root = this
root.action = this.action.uppercase()
root.user_id = this.user_id.number()
if this.exists("ssn") {
root.ssn = true
} else {
root.ssn = false
}
output:
redpanda:
seed_brokers:
- ${REDPANDA_BROKERS}
sasl:
- mechanism: SCRAM-SHA-256
username: ${secrets.REDPANDA_CLOUD_SASL_USERNAME}
password: ${secrets.REDPANDA_CLOUD_SASL_PASSWORD}
topic: clean-users
tls:
enabled: trueLet's break down this configuration:
input.aws_s3: This section tells Redpanda Connect to read data from your specified S3 bucket. The prefix: input/ is useful if your files are organized within a specific folder.scanner.csv.parse_header_row: true: This ensures that Redpanda Connect correctly identifies the column headers in your CSV files. The CSV scanner then takes each line and parses each field as a string.pipeline.processors.mapping: This is where the data transformation happens. We use Bloblang, a powerful and concise language built into Redpanda Connect, to define how our data should be processed. (Check out this Bloblang walkthrough!) user_id to a number and apply conditional logic to the ssn field. This "shift left" approach to data preparation is very efficient.output.redpanda: After transformation, your clean data will be sent to a Redpanda topic named clean-users.${secrets.AWS_ACCESS_KEY_ID} and ${REDPANDA_BROKERS}: These placeholders demonstrate how Redpanda Serverless seamlessly integrates with its built-in secrets store. No need to hardcode sensitive credentials like some kind of barbarian! ${REDPANDA_BROKERS} is a special environment variable that grabs your broker addresses from within the context of your cluster.secrets. are user-defined over in Redpanda Cloud's built-in secrets store:
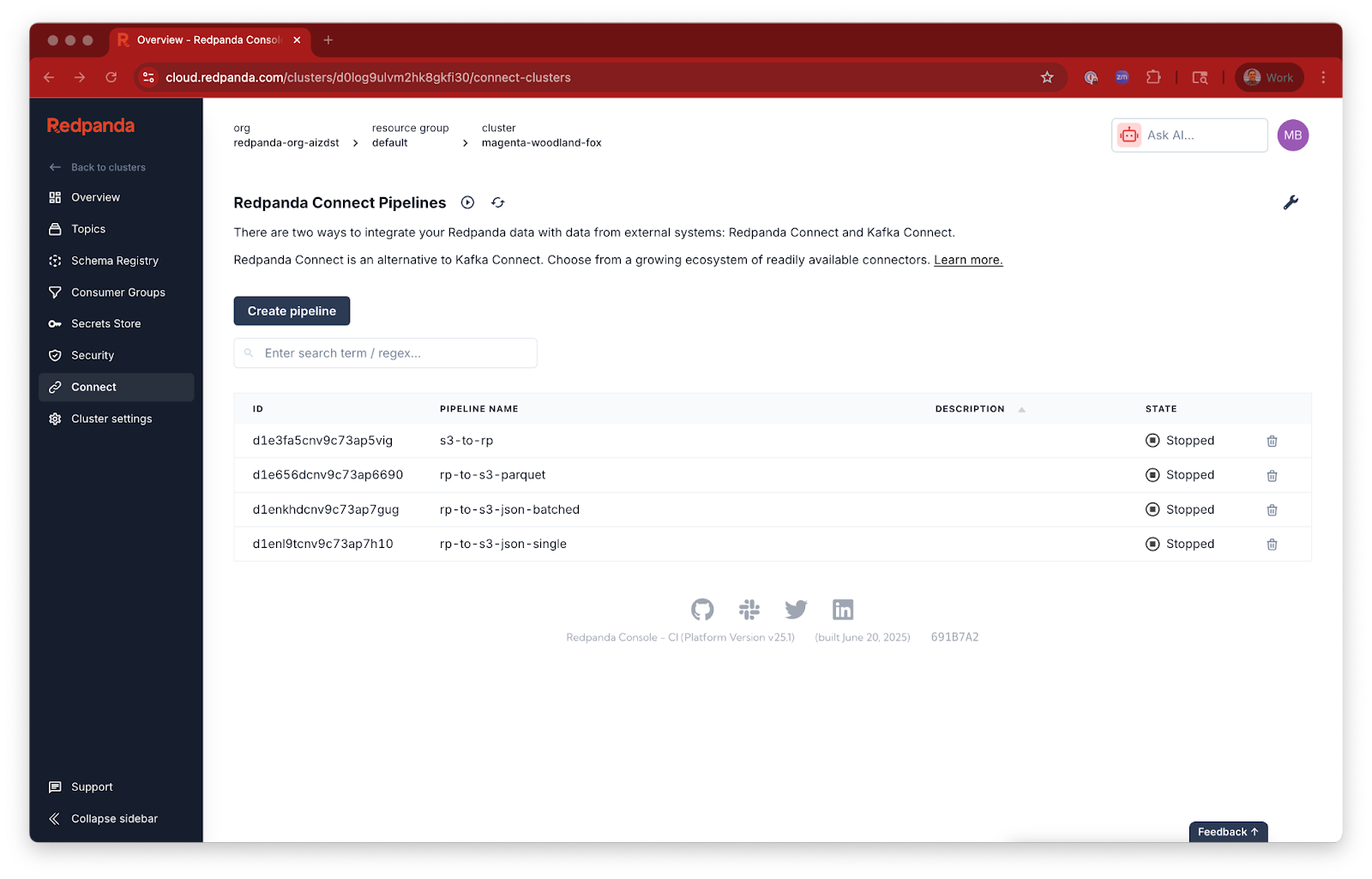
Once deployed, Redpanda Connect will begin reading your CSV files, transforming them according to your rules, and publishing the processed data to your clean-users topic.
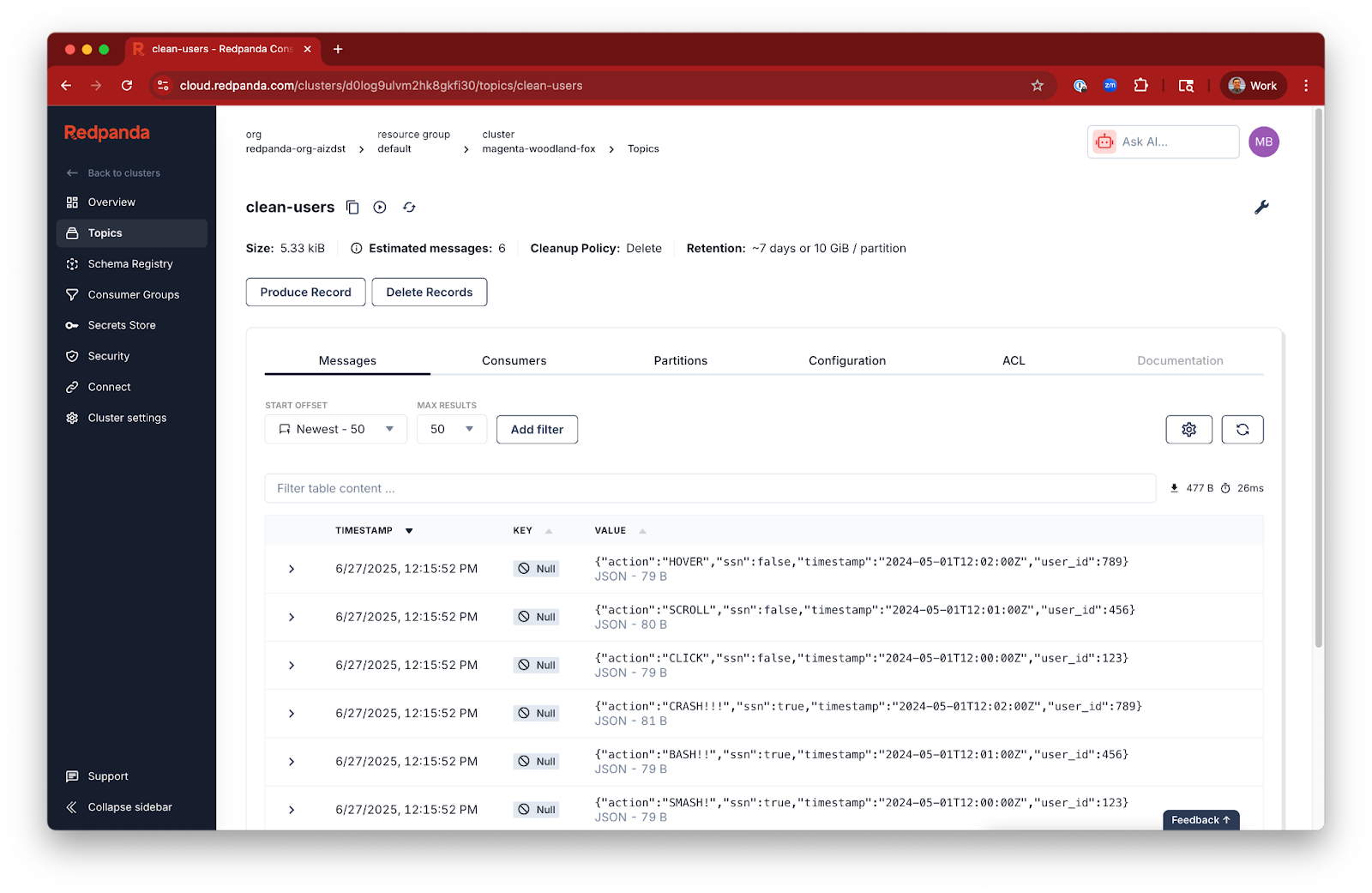
After running your pipeline successfully, you should see six messages in your topic:
Taking a break before the next example? No worries. To avoid any unnecessary charges, make sure to stop any running Redpanda Connect pipelines and delete your Redpanda streaming topic when you're done using them.
This pipeline should already be stopped, but future pipelines in the next few posts will run continuously if they are listening to Redpanda streaming topics or to event notifications from AWS.
You now have a functioning data pipeline from S3 to Redpanda complete with in-stream transformation logic and zero custom infrastructure. In our next post, we reverse the flow and export data from Redpanda to S3, with filtering and formatting options. Here's the full series so you know what's ahead:
If you have questions about this series, hop into the Redpanda Community on Slack and ask away.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

