




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Unlock data lake interoperability, greater streaming scale, and fully automated cluster lifecycles









To set up Iceberg Topics in Redpanda BYOC for GCP, you need to create a Redpanda Cloud account, install or update rpk, and enable Iceberg integration for the cluster. Then, create a topic and configure Iceberg mode, produce data to the topic using Schema Registry, configure the Iceberg Topic to use Google Cloud Storage (GCS), create a BigQuery external table for Iceberg data, and finally query the external table in BigQuery.
Iceberg Topics is a feature introduced in Redpanda 25.1. It offers a fast, simple, and cost-efficient way to automatically store Kafka topics directly in open table formats like Iceberg. This feature enables downstream systems like Snowflake, Databricks, Google BigQuery, or Amazon Athena to query data from Redpanda topics using SQL.
Iceberg Topics on Redpanda BYOC allows you to build a real-time data lake or enable time-travel queries on fresh data. It also allows downstream systems like Snowflake, Databricks, Google BigQuery, or Amazon Athena to query data from Redpanda topics using SQL. This provides full control of your Iceberg data with zero compromises.
Apache Iceberg is an open standard for large-scale analytics table formats. It offers powerful capabilities such as schema evolution, time travel queries, ACID transactions, and high performance at petabyte scale. It's compatible with engines like Spark, Trino, Flink, and Apache Kafka-native platforms like Redpanda.
Before setting up Iceberg Topics in Redpanda, you need to create a Redpanda Cloud account, install or update rpk, and enable Iceberg integration for the cluster. These steps ensure that you have the necessary tools and permissions to proceed with the setup.
Apache Iceberg™ has emerged as the default open standard for large-scale analytics table formats thanks to its powerful capabilities, including schema evolution, time travel queries, ACID transactions, and high performance at petabyte scale. Its open architecture, broad ecosystem support, and compatibility with engines like Spark, Trino, Flink, and now Apache Kafka®-native platforms like Redpanda, make it the go-to for modern data infrastructure teams seeking scalable, reliable, and future-proof data lakehouse architectures.
In Redpanda 25.1, we proudly delivered an industry-first: a Kafka-Iceberg streaming data solution, Iceberg Topics, available on multiple clouds, AWS, Azure, and GCP. In this post, we show you how easy it is to get up and running with Iceberg Topics on BYOC.
For more product updates, check what's new in Redpanda Cloud in our docs!
We recently introduced Iceberg Topics in Redpanda 25.1, giving users a fast, simple, and cost-efficient way to automatically store Kafka topics directly in open table formats like Iceberg. Now, we’re extending those benefits to Redpanda Cloud with a beta for BYOC customers.
Iceberg Topics unlock new use cases that blend streaming and batch workloads, enabling downstream systems like Snowflake, Databricks, Google BigQuery, or Amazon Athena to query data from Redpanda topics using good old SQL. For BYOC customers who already control their own object storage buckets, this means full control of your Iceberg data with zero compromises.
What’s included in the beta:
rpk CLI or Cloud HTTP APICheck out the latest Iceberg Topics announcement or check our docs to learn how Iceberg Topics work on Redpanda Cloud.
In this demo, we show you how to set up Iceberg Topics in Redpanda BYOC for GCP. Let’s say we’re a manufacturing company streaming data from various sensors, and we want to produce that sensor data to Redpanda and then query it within Google BigQuery.
For this scenario, we’ll create a Redpanda BYOC cluster in GCP, enable Iceberg Topics, and then query the data in Iceberg format using BigQuery. If you’re more of a visual learner, here’s the video to follow along:
For those who prefer to skim the instructions, here’s the setup step by step:
There are a few things to do before you start:
To start, create a topic using rpk. Check that your Redpanda topic is configured with iceberg_enabled set to true and select the right redpanda.iceberg.mode (e.g., value_schema_id_prefix, value_schema_latest, or key_value). This configuration instructs Redpanda to write the topic data in the Iceberg format to the configured Tiered Storage location.
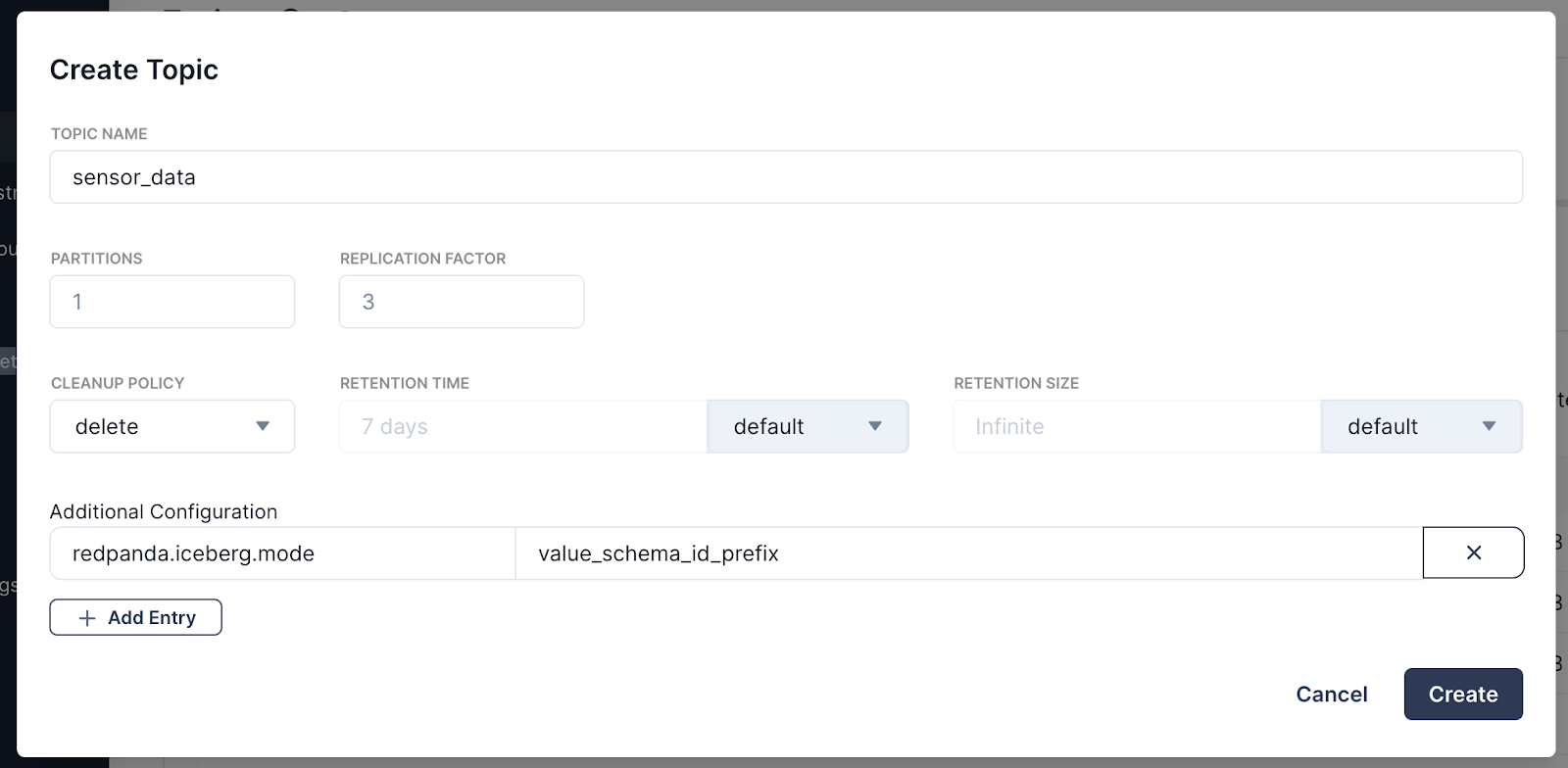
For this demo, we’ll go with value_schema_id_prefix, which means you have to register a schema in the Schema Registry (see next step), and producers must write to the topic using the Schema Registry wire format.
In this example, we’re using a data generator pipeline in Redpanda Connect. First, register the schema in Redpanda Console. In our example, we uploaded the following schema:
syntax = "proto3";
import "google/protobuf/timestamp.proto";
package com.example.manufacturing;
message SensorMeasurements {
float temperature = 1;
float pressure = 2;
float vibration = 3;
}
message SensorData {
string factory_id = 1;
string machine_id = 2;
string sensor_id = 3;
google.protobuf.Timestamp reading_timestamp = 4;
SensorMeasurements readings = 5;
int32 error_code = 6;
google.protobuf.Timestamp last_maintenance_timestamp = 7;
}Next, create your own pipeline with the following:
input:
batched:
policy:
count: 300
period: 1s
child:
generate:
mapping: |
let machine_id = random_int() % 300
let lastMaintenance = if $machine_id == 42 {
"2025-04-01T14:19:33.637-00:00"
} else {
"2025-02-14T15:12:30.123-00:00"
}
root = {
"factoryId": [
"us-west-1",
"us-east-2",
"us-south-1",
].index($machine_id % 3),
"machineId": $machine_id.string(),
"sensorId": ($machine_id * 10 + (random_int() % 10)).string(),
"readingTimestamp": now(),
"readings": {
"temperature": (timestamp_unix_nano() % 90).tan(),
"pressure": (timestamp_unix_nano() % 90).sin(),
"vibration": (timestamp_unix_nano() % 90).cos(),
},
"errorCode": if $machine_id == 9 { 1 } else { 0 },
"lastMaintenanceTimestamp": $lastMaintenance,
}
meta key = root.sensorId
interval: 0.0033333333s
count: 1
pipeline:
processors:
- schema_registry_encode:
url: "${REDPANDA_SCHEMA_REGISTRY}"
subject: sensor_data-value
basic_auth:
enabled: true
username: ${REDPANDA_USER}
password: ${REDPANDA_PASS}
output:
reject_errored:
redpanda:
seed_brokers: ["${REDPANDA_BROKERS}"]
topic: "sensor_data"
key: "${!@key}"
tls:
enabled: true
sasl:
- mechanism: SCRAM-SHA-256
username: ${REDPANDA_USER}
password: ${REDPANDA_PASS}
Now you’re ready to produce data. Hit Start on your data generator pipeline and watch the records show up in your sensor_data topic. You can click on a record to see how Redpanda Console decodes the schema in a readable format.
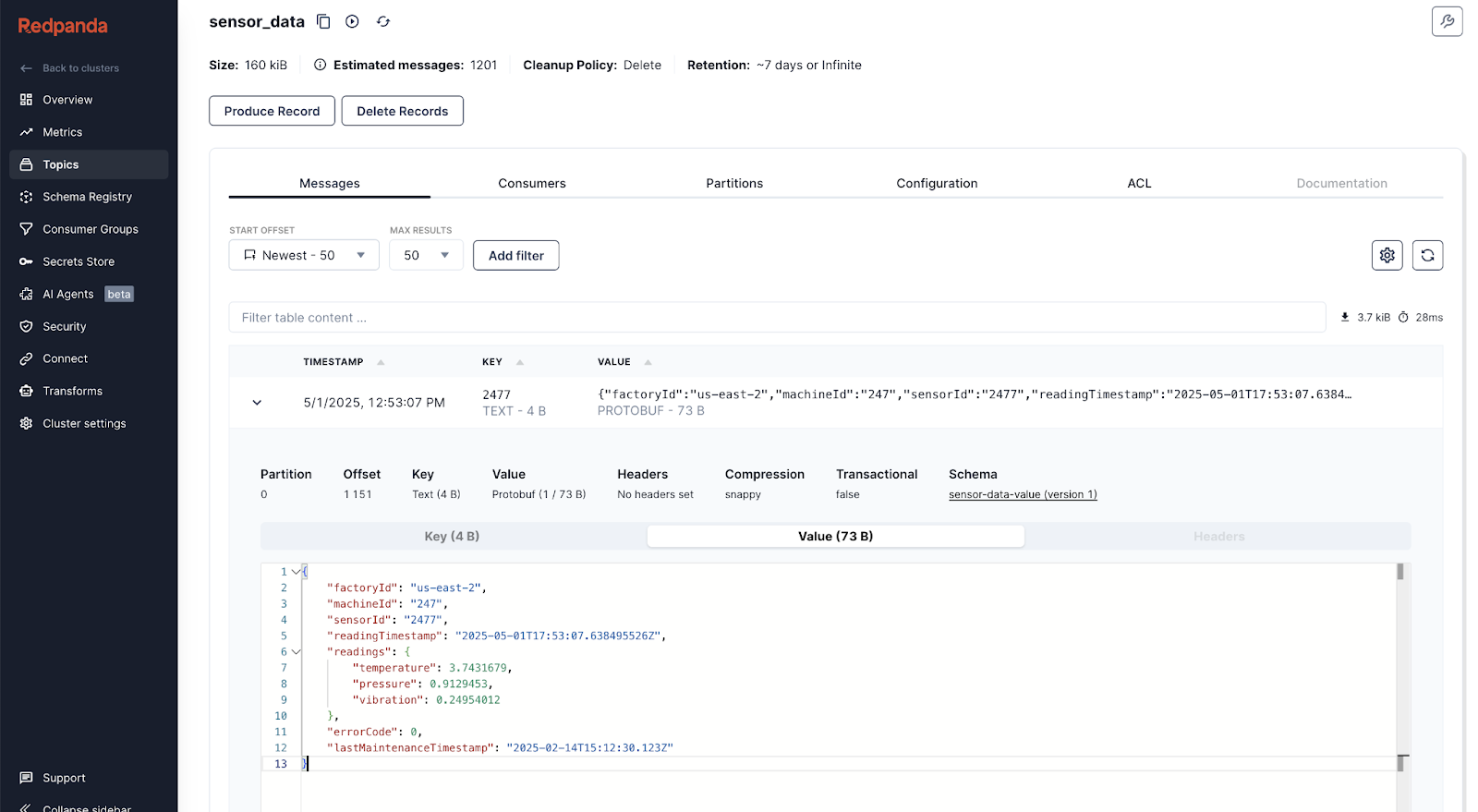
Make sure your Redpanda cluster's Tiered Storage is configured to write data to a specific GCS bucket, then create a BigQuery connection to GCS to access the data. Redpanda will manage the Iceberg table structure and metadata in the configured GCS bucket.
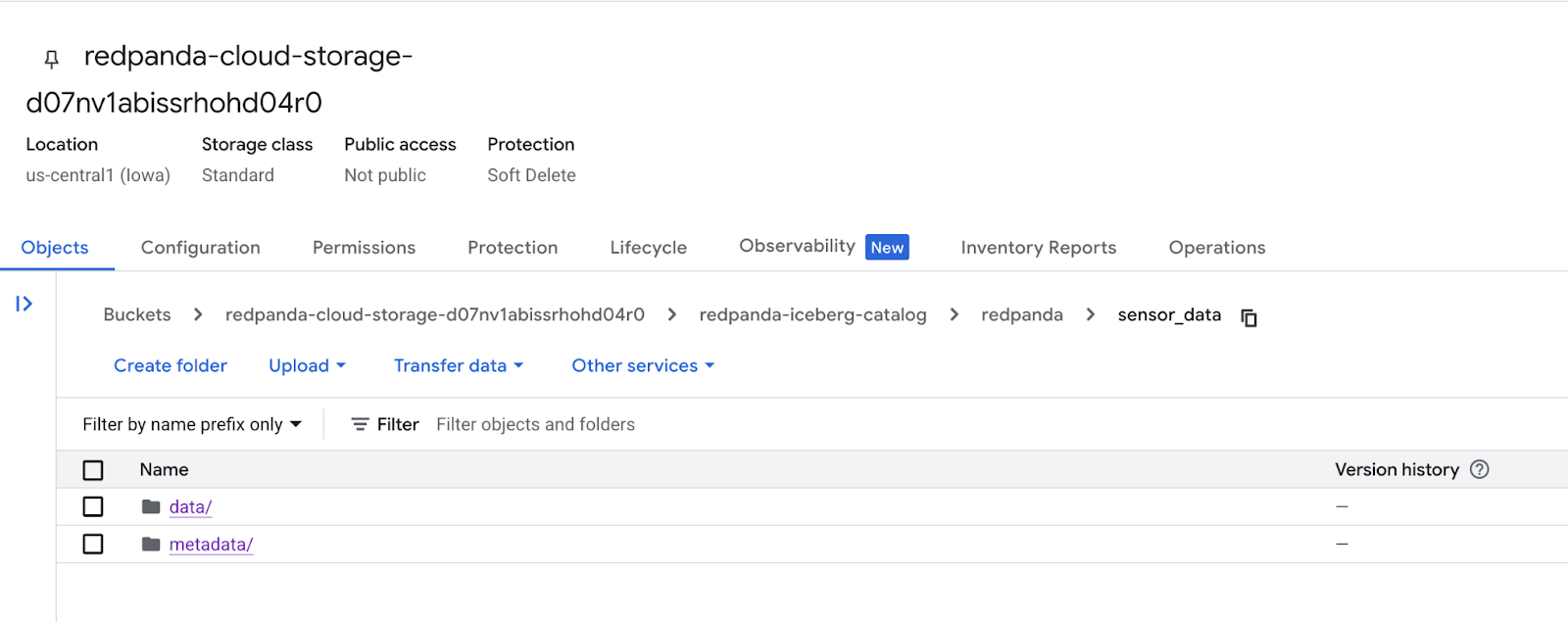
Within that GCS bucket, you’ll see a metadata subdirectory with the latest Iceberg metadata file. While those files are being created, move to the next step to create a dataset within BigQuery to house the incoming data.
Here you’ll create an external table in BigQuery that points to the Iceberg metadata file in GCS. You can use the BigQuery web UI or the bq command-line tool. A common method is to use a CREATE EXTERNAL TABLE SQL statement in the BigQuery console.
Run a statement like this, replacing the placeholders:
CREATE EXTERNAL TABLE YOUR_PROJECT_ID.YOUR_BIGQUERY_DATASET.YOUR_TABLE_NAME
WITH CONNECTION 'YOUR_FULL_CONNECTION_ID'
OPTIONS (
format = 'ICEBERG',
metadata_file_paths = ['gs://your-bucket-name/path/to/your/iceberg/table/metadata/vX.metadata.json']
);YOUR_PROJECT_ID: Your Google Cloud project ID.YOUR_BIGQUERY_DATASET: The BigQuery dataset where you want to create the table.YOUR_TABLE_NAME: The name you want to give your external table in BigQuery.YOUR_FULL_CONNECTION_ID: The fully qualified connection ID you obtained in the previous step.gs://your-bucket-name/path/to/your/iceberg/table/metadata/vX.metadata.json: The full GCS path to the latest Iceberg metadata file identified in Step 3.Once you’ve created the external table, you can query it just like any other BigQuery table using standard SQL. Open the BigQuery console and run your queries against the YOUR_PROJECT_ID.YOUR_BIGQUERY_DATASET.YOUR_TABLE_NAME table. BigQuery will use the Iceberg metadata file to understand the table structure and data file locations in GCS and retrieve the data for your queries.
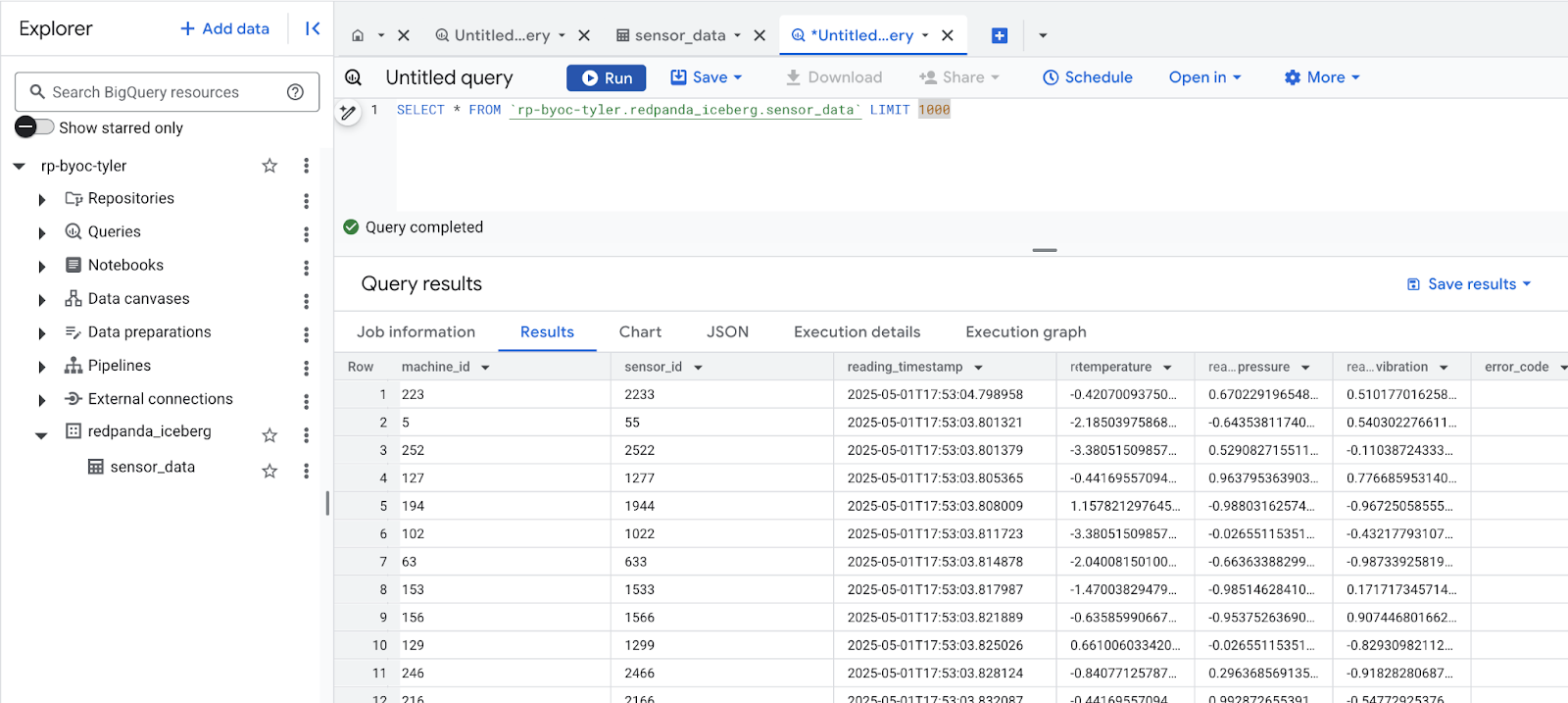
And you’re done! Remember to update the external table definition in BigQuery if the location of the latest metadata file changes or you want to query a newer snapshot of the table data.
Just in case, here are all the resources you need for setup:
Next, explore our docs on the automatic dead letter queue, or add custom partitioning to your Iceberg data.
Whether you’re building a real-time data lake or enabling time-travel queries on fresh data, Iceberg Topics on Redpanda BYOC makes it unbelievably easy. To see it for yourself, grab a free trial of Redpanda BYOC.
Querying your data while it’s still streaming has never been simpler.
Before you go, we thought you’d like to know that Redpanda BYOC now supports double the partition limits across most tiers, thanks to improved partition memory efficiency.
For example, the number of supported partitions in Tier 1 went from 1,000 to 2,000, and Tier 5 went from 22,800 to 45,600. Note that existing clusters may not yet support these partition counts if they haven’t been upgraded to 25.1. This enhancement delivers the scalability today’s data-driven teams demand, with full control over your infrastructure and zero operational burden.
What does this mean for your workloads?
Okay, now you can go. If you have questions, swing by the Redpanda Community.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

