





What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one

Practical strategies to optimize your streaming infrastructure








Burning through your Snowflake credits faster than expected? Have thousands of small files in your Apache Iceberg™ tables causing query delays and increasing storage expenses? Welcome to the club.
Real-time data has become a spiraling, uncontrollable cost for many organizations. The problem isn't just the volume of data you're ingesting. It's how you're doing it.
Traditional streaming architectures create unnecessary complexity, infrastructure overhead, and hidden costs that compound over time. This guide will show you how to build cost-efficient real-time ingestion pipelines that deliver the performance you need without breaking the bank.
But first, let's dig into the root causes driving up your streaming costs.
Your streaming costs aren't only about the volume of data you're dealing with but also architectural inefficiencies that have compounding impacts across your entire pipeline.
Traditional streaming platforms like Apache Kafka® require brokers along with coordination services, schema registries, connectors, and monitoring tools to operate in production. "Legacy" Kafka deployments relied on ZooKeeper clusters for coordination (although modern Kafka 3.6+ can run in **KRaft mode** without ZooKeeper), plus schema registries, connect clusters, and monitoring infrastructure. The diagram below illustrates the complexity of a typical Kafka deployment:

Each component demands its own compute resources, storage, and high availability setup. For example, when you're streaming into Snowflake and Iceberg, you're typically running message brokers with 3–5 nodes for fault tolerance, and ZooKeeper ensembles for coordination might need another 3–5 nodes. You would need to add Kafka Connect workers for Snowflake and Iceberg ingestion, schema registry clusters for data governance, and comprehensive monitoring infrastructure across all these components.
This architectural complexity means you're paying for compute and storage across multiple systems, even during low-traffic periods. This cost then multiplies exponentially as you scale. Each new data source or destination often requires additional connector resources and coordination overhead.
Streaming data arrives continuously in small increments and can lead to what's known as the "small file problem," where continuous streams generate an avalanche of small files over time.
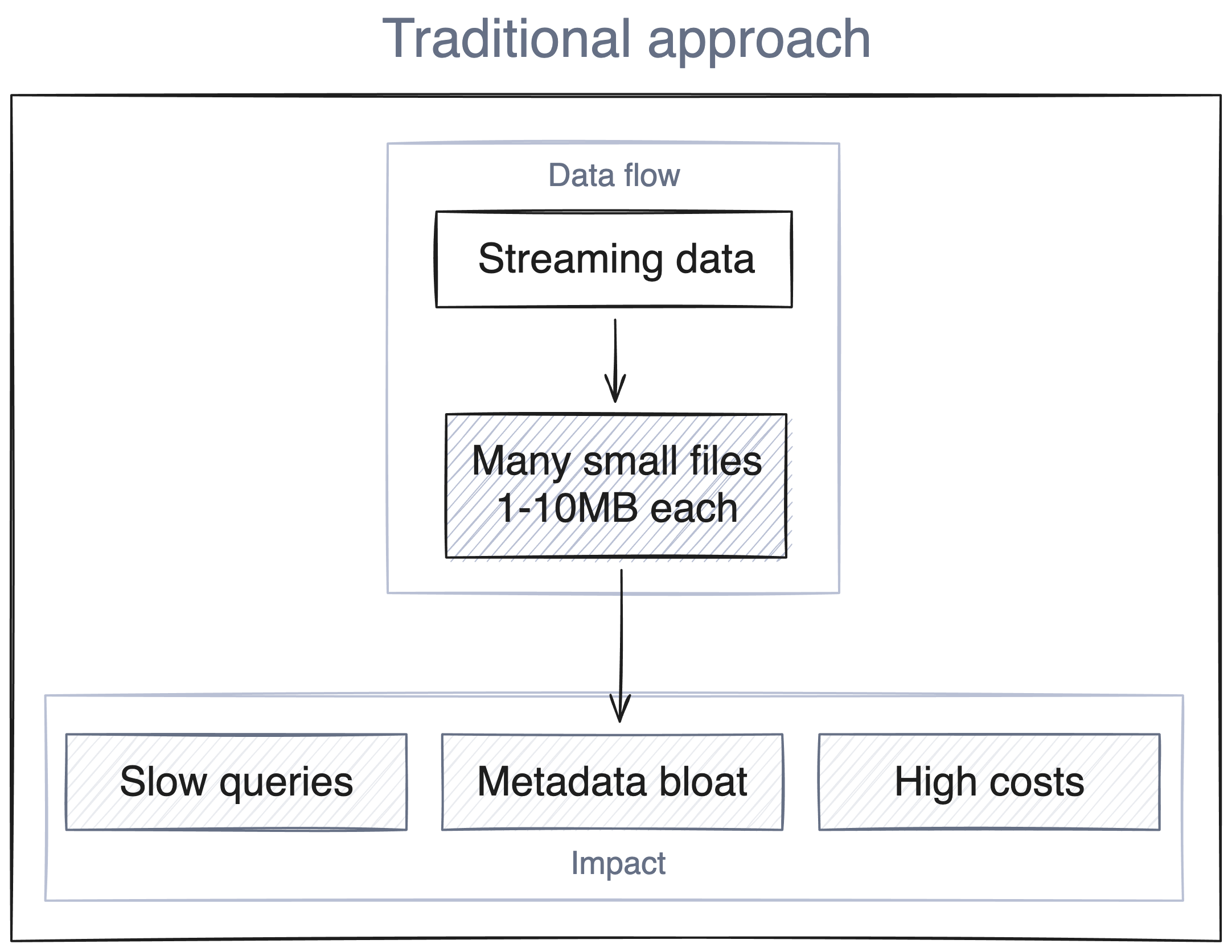
In Iceberg tables, this causes:
Beyond infrastructure complexity, traditional streaming architectures rely on inefficient data processing patterns. Most streaming architectures push raw, unfiltered data through multiple processing layers:
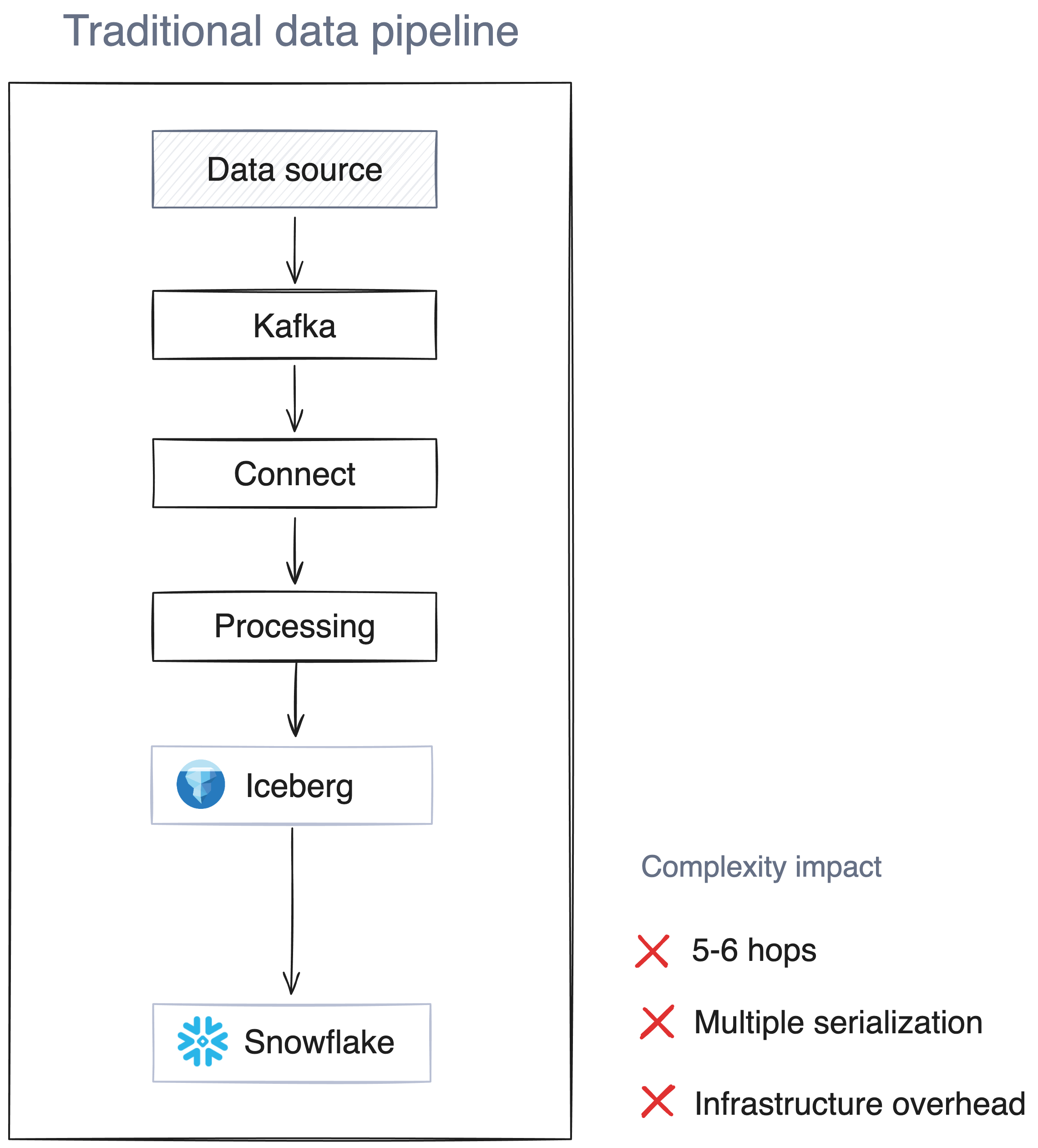
Each hop adds latency, infrastructure costs, and potential failure points. When processing happens late in the pipeline, you're paying to move and store data that may never be used, because it’s ultimately filtered out or heavily transformed.
To reduce your real-time data ingestion costs, you need to take a systematic approach that addresses the root causes discussed above. Your cost optimization framework should consider the following:
The most effective cost optimization happens closest to your data sources. This means implementing intelligent filtering and preprocessing before data enters your streaming pipeline. These three approaches can help you optimize on the source side:
How you format and compress your data has a big impact on storage, transfer, and compute costs throughout your pipeline. Focus on optimizing these three key areas:
Your partitioning strategy can make a huge difference in query costs and performance for both Snowflake and Iceberg. Here are three ways that smart partitioning and file management can help reduce your compute costs:
date and region if your queries frequently filter on both. Iceberg's hidden partitioning feature automatically rewrites queries to use the correct partition columns, so users can filter on fields like date or region without knowing the partition structure.Without proper visibility into key metrics, you can't measure performance or identify opportunities for optimization. You need comprehensive monitoring across your streaming pipeline, focusing on the metrics that directly impact costs:
Beyond operational metrics, you also need a detailed understanding of spending patterns to optimize resource allocation. You should know exactly where your money is going:
While the optimization strategies above are effective, they still require managing complex multi-component architectures. Traditional Kafka deployments for streaming into Iceberg often involve schema registries, Kafka Connect, and processing frameworks like Flink or Apache Spark, each adding cost, latency, and operational overhead.
Your streaming platform choice directly impacts costs, complexity, and scalability. Consider using a lightweight, cost-efficient platform, such as Redpanda, that offers low-latency streaming without Kafka's complexity.
Redpanda tackles the infrastructure multiplication problem by bundling everything into a single binary that replaces multiple Kafka ecosystem components. It handles schema management internally and supports Iceberg Topics for writing data straight to Iceberg tables, without Kafka Connect, Spark, or Flink. This approach simplifies operations, shrinks your infrastructure footprint, and improves performance.
Redpanda can write directly to Iceberg tables, dramatically simplifying the data pipeline, whereas rraditional streaming architectures require multiple hops to get data from producers to Iceberg/Snowflake. To put it simply:
Traditional path: Producer → Kafka → Kafka Connect → Processing Engine → Iceberg → Snowflake
Redpanda path: Producer → Redpanda Iceberg Topics → Iceberg → Snowflake
This direct integration eliminates infrastructure costs and complexity while providing several key operational advantages that address the problems identified earlier:
iceberg_catalog_commit_interval_ms). To maintain long-term table health, you can configure Iceberg to run periodic compaction and can reduce the number of small files by more than 40% depending on the ingestion pattern.For more complex integration scenarios, Redpanda Connect provides a lightweight alternative to traditional ETL tools. Unlike heavy frameworks that require dedicated cluster management, Redpanda Connect runs as lightweight processes that can transform data in flight, apply filtering, enrichment, and format conversion without separate processing clusters. It can route to multiple destinations simultaneously, sending data to both Snowflake and Iceberg with different transformations as needed. The system also handles back-pressure intelligently, automatically adjusting ingestion rates based on downstream capacity to prevent bottlenecks.
The complex nature of traditional Kafka ecosystems leads to escalating costs that grow exponentially during scaling operations. To minimize your streaming expenses, you need to do more than optimize individual components; you need a complete reevaluation of your entire system architecture. The combination of source-side intelligence with format optimization, compression management, strategic file management and platform selection leads to significant cost savings. Start with these strategies and consider how a consolidated streaming platform like Redpanda could help you build something more sustainable and cost-effective.
Ready to see how much you can save on your streaming infrastructure? Try out our Price Estimator to calculate your monthly costs.
What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.