





How Redpanda Cloud Topics rethinks Kafka compaction
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct
A case study in keeping Redpanda topic names from drifting with contracts








This blog is a guest post from Jonah Gray, a veteran software engineer and the founder and CEO of OmniNode.
I spent 16 years as an iOS developer, Objective-C through Swift—then the nerves in my hands gave out due to neuropathy. I went from occasional numbness in my hands to a condition I couldn’t work around.
My job demanded eight to ten hours of precise keyboard work per day, but my body couldn’t deliver. I tried ergonomic keyboards, shorter sessions, and even voice dictation, though nothing worked.
Then AI code generation tools grew popular, and I found a solution for some of my work. But writing code only makes up about a third of what software engineering actually involves. So I looked at how I could use AI to automate the rest of the workflow.
This is the story of how my search for another way to write software became the genesis of OmniNode, how Redpanda helped us scale our event catalog, and how we used contracts to ensure topic naming consistency.
Using AI code generation tools meant I could describe what I wanted—the architecture, the patterns, the constraints—and let an agent produce the implementation. For the first time in months, I could ship features without exacerbating my neuropathy.
That solved the issue of writing code, but I still had plenty of tasks that required sitting at a keyboard and working manually. I still had to read pull requests, review diffs, trace failures from a log line through three services to find wrong config values, and follow renames across a codebase to confirm nothing had broken.
All of that work still hurt.
So I started automating the rest of the workflow. I built agents to:
Soon I had dozens of agents, and that’s when my next issue appeared: coordinating across agents.
All of the agents I’d built were independently fast but chaotic. They would step on each other’s changes, duplicate work, claim incomplete tasks were finished, or merge code that broke another agent’s in-flight branch.
The entire workflow was unreliable without a way to route tasks, track task status, verify results, and enforce ordering.
I built a system to handle that coordination, purely because it was the only way I could keep shipping software. While I only set out to solve my own problems, the system ended up addressing a question that many companies were asking:
How do you make AI-driven development trustworthy when you’re running it at scale across multiple repositories, and with agents that need to coordinate through shared infrastructure?
That system (and question) laid the foundation for what eventually became OmniNode.
Today OmniNode is a contract-driven runtime for AI agent orchestration. It coordinates fleets of agents that build, test, review, and deploy software across multiple repositories simultaneously.
Every unit of work in the system is a node, and every node ships with a contract that declares exactly what the node consumes and produces, what events it listens to, and what topics it publishes on the bus. The runtime uses those contracts to provision infrastructure, route tasks, validate completions, and enforce ordering across agents that would otherwise have no idea what each other is doing.
The event bus is the spine of the whole system. Instead of agents calling each other directly, they publish events when work is done and subscribe to events that trigger their next step. Each agent knows only its own inputs and outputs, while the bus handles the rest.
The workflow is as follows:
I look at a single question, answered thousands of times a day: What’s the cheapest model that can do this task?
Most agent work doesn’t need a frontier model. Classification, code generation, refactoring, and summarization—a local model running on hardware I already own handles them fine. The expensive cloud models are a fallback for the hard cases, not the default. So every task gets classified and routed to the cheapest model that can actually do it, and the result gets checked before it counts as done.
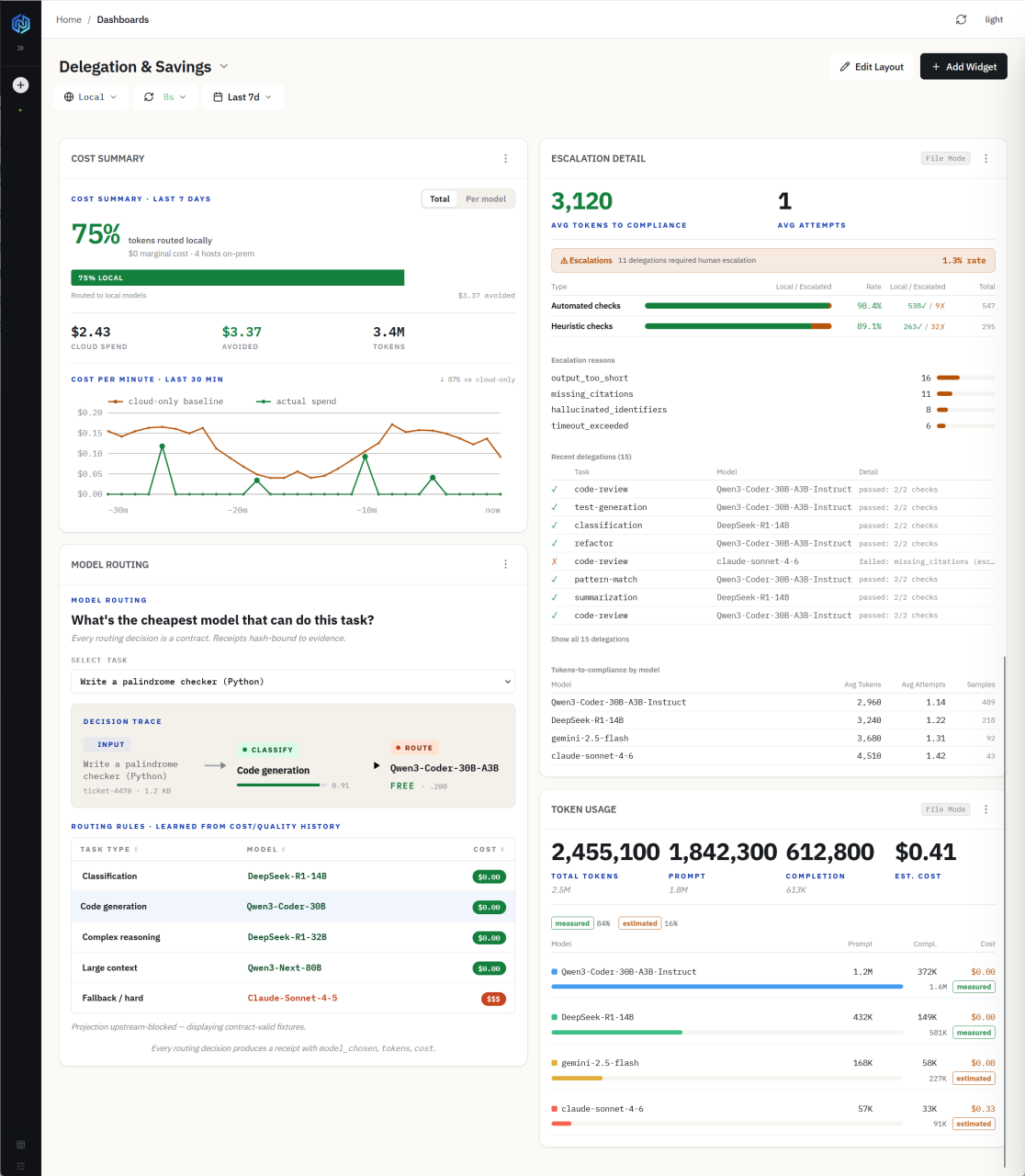
Over the last seven days, that meant 75% of tokens never left the building. They were routed to four on-prem hosts at zero marginal cost and roughly $3.37 in cloud spend was avoided, compared to $2.43 actually spent. At a larger scale, that ratio is the whole business case. But cheap routing only works if you can trust it, and that is where the contracts come back in.
Every routing decision produces a receipt: which model was chosen, how many tokens it took, what it cost, and whether the output passed its compliance checks. When a local model can’t meet the bar (output is too short, missing citations, or hallucinated identifiers), the task automatically escalates to a stronger model.
Last week, that happened on 1.3% of delegations, and the receipt shows exactly why each one escalated. The point is that the same discipline that keeps topic names from drifting—one canonical source, validated, with no second hidden copy—is what lets me hand work to the cheapest model without hoping it went well. The decision is a contract. The receipt is the evidence. Neither lives in someone’s head.
Originally, we used Redis Streams for the message bus.
We had abstracted the broker behind a transport layer, published with XADD, consumed with XREADGROUP, and kept topic names in Python constants near the code that used them. Apache Kafka was explicitly deferred in the roadmap because the system was still small.
Then the system grew from 5 repositories to 12, and the event catalog surpassed 100 event types. We outgrew Redis Streams not because of throughput, but because coordination itself became difficult.
What we needed:
We decided to move to Redpanda, giving us Kafka-API compatibility in a single binary.
The migration itself was straightforward because the transport abstraction had already decoupled our publishing and subscribing logic from the broker.
The challenge we didn’t expect was topic identity. In our architecture, the topic name was the only thing connecting one agent’s output to another agent’s input.
With Redis Streams, topics were usually owned end-to-end by a single developer. With 100 Kafka-shaped topics spread across independent repositories, the topic name became the critical coordination surface.
We found out the hard way that using different names would lead to broken pipelines. In one example, we had an agent confuse a hyphen with an underscore.
A producer published to:
onex.evt.router.routing-complete.v1
But the consumer subscribed to:
onex.evt.router.routing_complete.v1
Both services started cleanly, both topic names were accepted, and nothing failed—yet the routing pipeline silently stopped working.
The same class of bug kept reappearing:
Every instance had the same shape, where both names were well-formed and both operations succeeded. The silence was the failure mode.
We realized this was a naming problem before it was a schema problem.
Every node in OmniNode ships a contract.yaml.
The contract owns the node’s bus surface.
event_bus:
subscribe_topics:
- "onex.cmd.router.route-request.v1"
- "onex.evt.router.scoring-decision.v1"
publish_topics:
- "onex.evt.router.routing-complete.v1"
- "onex.evt.router.routing-failed.v1"Topic names follow this shape:
onex.{kind}.{producer}.{event}.v{N}
A regex validates the structure, and a StrEnum backs the canonical registry.
The regex catches malformed names, while the enum catches names that are syntactically valid but not canonical.
Most importantly, the contract becomes the only reviewed location where wire-format topic names live. There is no second operator-maintained registry, separate constant list hidden inside the runtime, or manually synchronized provisioning config.
If a node wants the system to provision and validate a topic, it must put the topic name in its contract.
Why does this constraint matter? Well, in the Redis Streams era, topic names lived wherever a developer put them. That included constants near publishers, strings inside consumer configs, and sometimes a shared module if someone remembered.
Once the topic count crossed into the hundreds, those scattered definitions became the root cause of nearly every silent wiring failure we hit.
The implementation itself is intentionally small.
A ContractTopicExtractor discovers approved packages, loads each contract.yaml, and returns the union of declared topics.
That extractor runs in 3 independent places.
CI invokes the extractor and creates the declared topics against the broker.
If a developer adds a new node but forgets to declare a required topic, the smoke tests fail before the change merges.
This is the earliest enforcement point: the contracts are validated against a real broker before the runtime ever starts.
When the runtime starts, the provisioner invokes the same extractor.
There is no fallback constant list or duplicated topic configuration. If the contracts are silent, the provisioner is silent.
The runtime only knows about the topics that the contracts declare.
After provisioning, a startup validator queries the broker and compares the existing topics against the extractor output.
If a declared topic is missing, say because topic creation partially failed during startup, the validator re-invokes provisioning.
This is the cheapest recovery path in the system.
With multiple independent passes, a topic name can only be wrong in the contract. While the processes and lifecycle stages may differ, there is only one parser. Ultimately, being disciplined matters more than the infrastructure.
The runtime provisioner has a deliberately narrow scope: it creates missing topics.
new_topic = NewTopic(
name=spec.suffix,
num_partitions=partitions,
replication_factor=spec.replication_factor,
)
await admin.create_topics([new_topic])Provisioning is async, best-effort, and non-blocking.
If a topic already exists, the provisioner leaves it alone. It does not:
If a topic was originally created with 6 partitions and the contract later requests 12, the provisioner will not notice.
That boundary is intentional. Creation is contract-owned; reconciliation is a different problem. The interesting work happens before provisioning starts, inside the extraction and validation path.
We chose Redpanda because it made broker enforcement affordable to run everywhere. The contract discipline only works if the broker exists everywhere that code executes:
If the broker is operationally heavy, teams eventually stop running it locally. They fake the bus, mock topic creation, or maintain a second development path that doesn’t actually validate topic identity.
In our setup, the broker boots in a single container, fits comfortably into an 8 GB development profile, and uses the same compose file everywhere. The same admin client works in CI, on a laptop, and in the runtime environment.
This results in a developer-scale topology that is:
Although Redis Streams was never the problem and handled our original message patterns well, the coordination requirements that drove us to Redpanda also made topic identity the load-bearing surface. Redpanda gave us the Apache Kafka® API while avoiding a high operational cost profile.
Our next obvious gap is configuration drift. Right now the system catches naming drift but doesn’t reconcile partition count drift, replication-factor drift, or retention-policy drift.
The next step is straightforward:
In OmniNode, we try to make the infrastructure state projectable from canonical inputs. The contract describes what should exist, while the broker reports what does exist. A materialized projection over both turns drift detection into a query instead of a script. That reconciliation layer is not built yet.
A year ago, our topic names lived in Python constants, and one developer could recall the entire list. But that process stopped working around the fiftieth topic. Today we’ve replaced it with contract discipline. The contract owns the names, the extractor owns the parse, and three independent call sites consume the parse. The broker stays boring on purpose.
Now we’ve closed the gap between what the code thinks exists and what the broker actually has. My recommendation for other users: before your next Redpanda topic ships, ask which file owns its name. If the answer is more than one, you’ve found yourself a bug.
Curious about Redpanda? Get started for free, or join the Redpanda Community on Slack to chat.
Fewer wasted CPU cycles and lower storage costs while keeping compaction correct

A detailed look at the bug we found and the compaction algorithm that solved it

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.