

Timer in Kafka Streams—implementation guide











Kafka timer
Kafka Streams is a client library for real-time stream processing on top of Apache Kafka®. It simplifies real-time processing by providing high-level abstractions for various operations such as filtering, aggregating, and joining data.
Timers in Kafka Streams allow for the execution of time-based logic, which is crucial for applications needing scheduled actions like session timeouts and delayed messaging. You can manage the state, perform delayed actions, and handle windowed aggregations.
Timers are essential for developers looking to implement real-time data processing with time-sensitive requirements. This article explores implementation details, use cases, and best practices for timers in Kafka Streams.
Before digging into this chapter, check out our previous chapter on Kafka Streams.
Summary of key concepts
The need for Kafka timer mechanisms
Pre-determined or predefined time triggers, (i.e.,Kafka timer mechanisms), are crucial in many aspects of stream processing.
State management
Kafka timer mechanisms support the expiry and cleanup of state stores. In Kafka Streams, state stores maintain intermediate processing results, essential for operations like aggregations and joins.
For example, you aggregate sale values over a specific period by adding data transactions as they arrive. However, state stores can grow indefinitely if not appropriately managed, leading to increased storage costs and potential performance degradation.
Kafka timer mechanisms allow you to maintain the optimal performance of your state store and prevent the application from consuming unnecessary resources. You define time-based retention policies to automatically remove outdated or irrelevant state data.
Delayed messaging
Kafka timer mechanisms facilitate delayed messaging to manage time-sensitive tasks and handle messages at the appropriate time. Delayed messaging refers to deferring actions until a specified time. Examples include reminder systems that notify users at a later time or delay queues that hold messages for a certain period before processing them. Delayed messaging enhances the functionality and flexibility of stream processing applications for diverse business requirements.
Windowed aggregations
Kafka timer mechanisms also facilitate windowed aggregations. You can segment data streams into fixed-size or variable-size time windows and perform aggregations within these windows.
- Tumbling windows divide the data stream into non-overlapping intervals while hopping windows allow for overlapping intervals.
- Session windows are dynamic and close when a period of inactivity is detected.
- Windowed aggregations are particularly useful for use cases such as calculating rolling averages, detecting trends, and generating time-based reports.
Implementing timers in Kafka Streams
Kafka Streams implements timers using the below concepts.
Event time and processing time
Event time is a timestamp embedded within the event record when the event occurs at the source. It’s essential for scenarios where the accuracy of event order and time-based calculations (e.g., windowed aggregations) are critical. Event time ensures that even if events arrive out of order, they’re processed based on their original creation time.
Event time is already present in the data record before it reaches Kafka Streams. Below is a code example for extracting the data. It uses a custom TimestampExtractor to parse and return the event time from each record. This code should be added to your main Kafka Streams application file, typically named StreamsApp.java.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream("input-topic", Consumed.with(Serdes.String(), Serdes.String(), new TimeExtractor(), Topology.AutoOffsetReset.EARLIEST));
public class TimeExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record, long previousTimestamp) {
// Extract timestamp from record (assuming the timestamp is embedded in the value)
return Long.parseLong(record.value().toString().split(",")[1]);
}
}In contrast to event time, processing time is the timestamp Kafka Streams records when it processes the event data. It is important for applications where low latency is more critical than precise event timing. You process records as they arrive without considering their creation time.
Event time provides more accurate and consistent results for time-based operations, especially when dealing with late-arriving data. However, it may introduce complexity in handling out-of-order events. In contrast, processing time is more straightforward and faster to implement but can lead to inaccuracies in time-based aggregations if events arrive late.
Windowed operations
Windowed operations are central to time-based processing in Kafka Streams. They enable the grouping of records into windows for aggregation purposes. As discussed previously, you can have three types of windows.
- Fixed-size, non-overlapping time intervals—tumbling windows
- Fixed-size windows that overlap—hopping windows.
- Dynamic windows that group events based on periods of inactivity—session windows.
Hopping windows provide more granular insights. Session windows are useful for user session tracking, where user activities span across multiple sessions and also the activity patterns determine the window duration.
Code examples
The code below creates a tumbling window of 5 minutes and counts the occurrences of records within each window. The result is stored in a KTable, and you can use it for further processing or output.
TimeWindows tumblingWindow = TimeWindows.of(Duration.ofMinutes(5));
KTable<Windowed<String>, Long> tumblingCounts = stream
.groupByKey()
.windowedBy(tumblingWindow)
.count(Materialized.as("tumbling-counts"));The code below creates a hopping window of 5 minutes with an advance interval of 1 minute and counts the occurrences of records within each window. The result is stored in a KTable.
TimeWindows hoppingWindow = TimeWindows.of(Duration.ofMinutes(5)).advanceBy(Duration.ofMinutes(1));
KTable<Windowed<String>, Long> hoppingCounts = stream
.groupByKey()
.windowedBy(hoppingWindow)
.count(Materialized.as("hopping-counts"));The code below creates session windows with 30-minute inactivity and 5-minute grace periods, counting the records occurrences within each session window. The result is stored in a KTable.
SessionWindows sessionWindow = SessionWindows.with(Duration.ofMinutes(30)).grace(Duration.ofMinutes(5));
KTable<Windowed<String>, Long> sessionCounts = stream
.groupByKey()
.windowedBy(sessionWindow)
.count(Materialized.as("session-counts"));Punctuation
Punctuation in Kafka Streams is a mechanism that triggers time-based operations at regular intervals. A periodic callback runs at specified intervals within a stream processing topology. It allows you to run custom logic periodically—for example, state cleanup, aggregations, or emitting results at regular intervals.
The code below demonstrates how to set up punctuation in Kafka Streams. It schedules a punctuation callback to run every 5 minutes, but you can customize it to run any required logic at regular intervals.
stream.transform(() -> new Transformer<String, String, KeyValue<String, String>>() {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
// Schedule punctuation every 5 minutes
this.context.schedule(Duration.ofMinutes(5), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
// Custom logic to execute periodically
System.out.println("Punctuation triggered at: " + timestamp);
});
}
@Override
public KeyValue<String, String> transform(String key, String value) {
// Transformation logic
return new KeyValue<>(key, value);
}
@Override
public void close() {}
}, "source");Practical use cases of Kafka timer mechanisms
So, how can you use all the above concepts for real-world use cases? Let’s explore some examples below.
Session management
Session management is a common use case for timers in Kafka Streams, particularly for applications that track user activity. Implementing session timeouts and cleanup strategies ensures inactive sessions do not consume unnecessary resources.
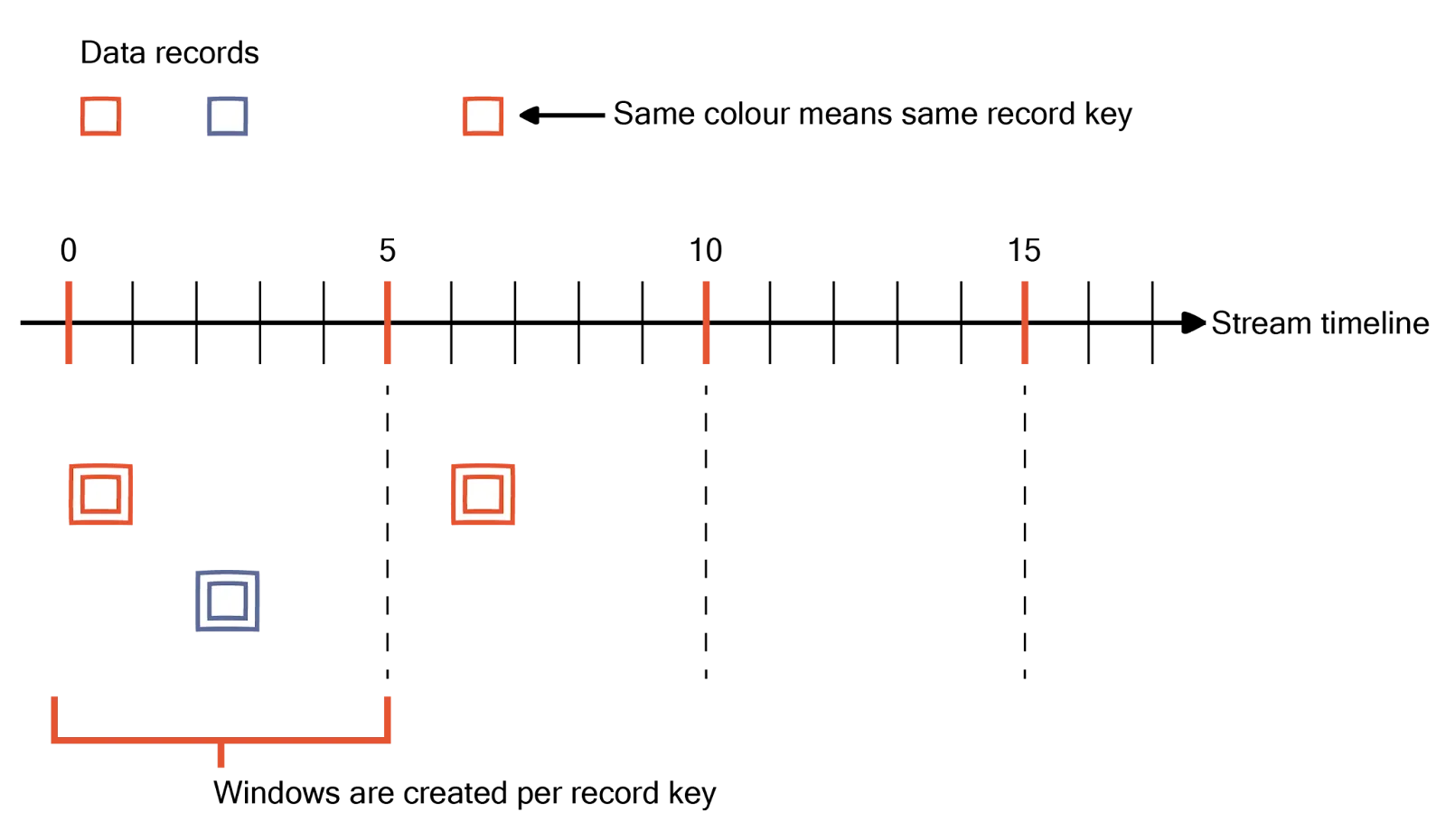
For example, you can use session windows to group events based on periods of activity and inactivity. The session window closes when inactivity exceeds a specified threshold, triggering timeout logic. You can regularly clean up state stores to remove expired session data and free up resources.
The below code example demonstrates how to use Kafka Streams to group user activity records into session windows based on periods of inactivity. The session windows aggregate the number of activities per user and allow for late-arriving events with a grace period. Finally, it processes the aggregated results, printing the session details for each user. This is particularly useful for tracking user sessions in web analytics or user behavior monitoring applications.
KStream<String, String> userActivityStream = builder.stream("user-activity");
KTable<Windowed<String>, Long> sessionCounts = userActivityStream
.groupByKey()
.windowedBy(SessionWindows.with(Duration.ofMinutes(30)).grace(Duration.ofMinutes(5)))
.count(Materialized.as("session-counts"));
sessionCounts.toStream().foreach((windowedKey, count) -> {
String userId = windowedKey.key();
long sessionEnd = windowedKey.window().end();
System.out.printf("User %s session ended at %d with %d activities%n", userId, sessionEnd, count);
});Delayed actions
Delayed actions are helpful for scenarios where events need to be processed after a certain delay. This can include sending reminders, deferring tasks, or implementing delay queues. You can:
- Use the punctuation mechanism to schedule and execute delayed actions at regular intervals.
- Maintain state to keep track of events that need to be processed after a delay.
The code example below demonstrates how to implement delayed actions. You set up a transformation on a stream, store timestamps of processed records in a state store, and schedule a periodic callback to check and run delayed actions. The periodic callback runs every 10 minutes and performs actions on records that have been delayed for at least 10 minutes. This approach helps implement functionalities like delayed messaging, reminder systems, or any scenario where actions must be deferred for a specified duration.
KStream<String, String> inputStream = builder.stream("input-topic");
inputStream.transform(() -> new Transformer<String, String, KeyValue<String, String>>() {
private ProcessorContext context;
private KeyValueStore<String, Long> stateStore;
@Override
public void init(ProcessorContext context) {
this.context = context;
this.stateStore = (KeyValueStore<String, Long>) context.getStateStore("delayed-actions-store");
this.context.schedule(Duration.ofMinutes(10), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
stateStore.all().forEachRemaining(entry -> {
long storedTimestamp = entry.value;
if (timestamp >= storedTimestamp + 600000) { // 10 minutes delay
System.out.printf("Executing delayed action for key %s at %d%n", entry.key, timestamp);
stateStore.delete(entry.key);
}
});
});
}
@Override
public KeyValue<String, String> transform(String key, String value) {
long currentTimestamp = context.timestamp();
stateStore.put(key, currentTimestamp);
return new KeyValue<>(key, value);
}
@Override
public void close() {}
}, "delayed-actions-store");Stateful processing
Stateful processing with time-based triggers allows applications to perform certain computations or state changes periodically or after specific intervals. You can:
- Use windowed operations to aggregate and process data within specific time windows.
- Regularly update and manage state stores to reflect time-based changes.
The code below demonstrates how Kafka Streams can aggregate sales data by region using hourly tumbling windows. The steps include:
- Define the stream.
- Group and window the data.
- Perform the aggregation.
- Process the results.
The tumbling windows aggregate sales data in fixed, non-overlapping one-hour intervals. They provide an hourly view of sales performance by region. This approach is useful for generating time-based reports and real-time analytics.
KStream<String, Long> salesStream = builder.stream("sales-topic", Consumed.with(Serdes.String(), Serdes.Long()));
KTable<Windowed<String>, Long> salesByRegion = salesStream
.groupBy((key, value) -> key, Grouped.with(Serdes.String(), Serdes.Long()))
.windowedBy(TimeWindows.of(Duration.ofHours(1)))
.reduce(Long::sum, Materialized.as("sales-by-region"));
salesByRegion.toStream().foreach((windowedKey, totalSales) -> {
String region = windowedKey.key();
long windowEnd = windowedKey.window().end();
System.out.printf("Total sales for region %s at %d: %d%n", region, windowEnd, totalSales);
});Best practices and tips
We give more implementation tips below.
Define retention policies for your state store
Use metrics provided by Kafka Streams to track state store size and performance and set up alerts for unusual patterns. Define retention policies to automatically delete old data from state stores. This helps to free up storage and keep the state store size manageable. Example:
Materialized<String, Long, KeyValueStore<Bytes, byte[]>> materialized = Materialized.<String, Long>as("state-store")
.withRetention(Duration.ofDays(7)); // Retain data for 7 daysYou can also use log compaction for state stores to keep only the latest value for each key, reducing the storage footprint. You can enable compaction in the Kafka topic configuration. You can configure state store retention as follows.
KTable<String, Long> aggregatedTable = inputTable
.groupBy((key, value) -> key)
.aggregate(
() -> 0L,
(aggKey, newValue, aggValue) -> aggValue + newValue,
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("aggregated-state-store")
.withRetention(Duration.ofHours(24)) // Retain data for 24 hours
);Optimize punctuation intervals
Choose appropriate punctuation intervals for efficient and timely event processing. You must balance frequency and overhead. More frequent punctuation intervals ensure timely processing but increase overheads. Less frequent intervals reduce overhead but may delay processing.
Shorter intervals are preferred for tasks that require real-time responsiveness. Longer intervals may be more efficient for less time-sensitive tasks. Experiment with different intervals to find the optimal balance for your use case. Continuously monitor the performance impact of punctuation intervals and adjust them based on observed behavior and system load.
Monitor your timed events
Utilize the built-in metrics provided by Kafka Streams to monitor the performance and health of your application. Key metrics include processing rate, state store size, latency, and punctuation intervals.
Implement comprehensive logging to capture the flow of events and state changes within your application. You can use log levels to differentiate between informational logs, warnings, and errors. Set up alerts based on key metrics and log patterns to notify you of potential issues before they impact the application.
Integrate distributed tracing tools to trace the path of events through your Kafka Streams application and identify bottlenecks in the event processing pipeline.
The code snippet below sets up a Kafka Streams application with custom metrics reporting. By adding a custom metrics reporter class (com.example.CustomMetricsReporter), you can extend the default metrics to suit your monitoring needs.
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-monitoring");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
KafkaStreams streams = new KafkaStreams(builder.build(), props);
// Add a custom metrics reporter
props.put(StreamsConfig.METRIC_REPORTER_CLASSES_CONFIG, "com.example.CustomMetricsReporter");
streams.start();Conclusion
In today's fast-paced digital landscape, real-time data processing is crucial for applications like monitoring financial transactions and analyzing user behavior. You require systems that can capture and process events as they occur. Kafka Streams integrates with Kafka but introduces complexities in cluster management at scale. It also does not offer the same level of sophistication as other stream processing alternatives.
For example, Apache Flink® is another powerful stream-processing framework that offers extensive capabilities for handling timed events. It offers precise control over how events are processed based on their timestamps. Due to sophisticated windowing and watermarking mechanisms, Flink excels at handling late data and out-of-order events. You can define complex event-time-based windows and apply functions to these windows with minimal effort.
You can combine Redpanda for data ingestion and Flink for time-based processing to get a more scalable and high-performing solution. Redpanda also provides built-in data transforms so you can apply routine processing logic without requiring any additional libraries or infrastructure. To get started with Flink, enroll in our free Flink Deep Dive course!