

Kafka Headers—Use cases, best practices, and alternatives











Kafka headers
A Kafka header is a messaging mechanism that allows developers to attach metadata to messages separate from the message payload. It represents a structured and efficient way of storing context about messages. You can use it to improve message processing and routing in Apache Kafka-based applications.
This blog explores use cases, implementation strategies, and best practices to leverage Kafka headers. We also discuss integration with Kafka Streams and alternatives if you want to avoid using them.
Summary of key concepts in Kafka headers
Understanding Kafka headers
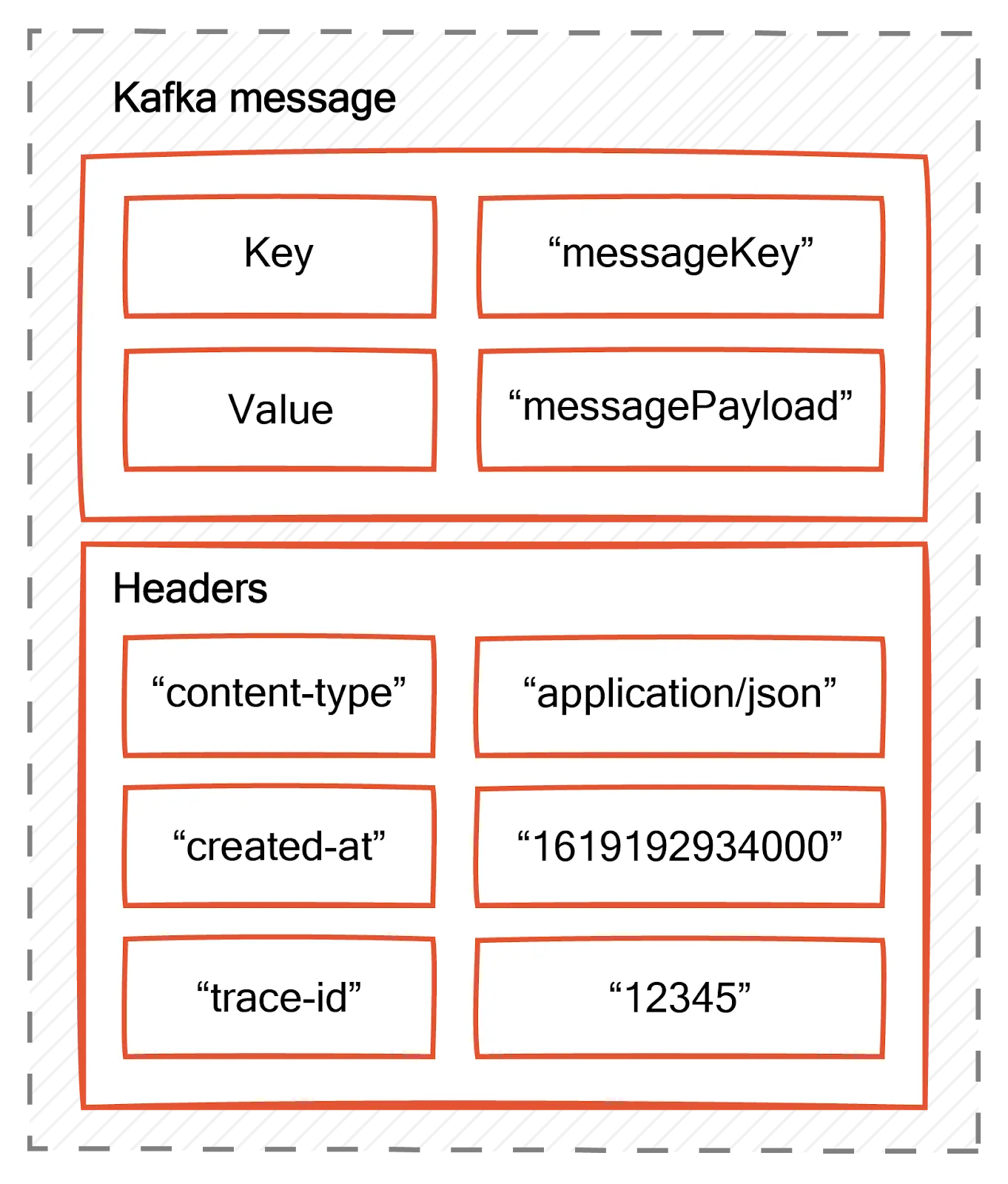
Kafka headers are key-value pairs that you add to Kafka messages. The headers can transport any metadata necessary for consumers to handle messages appropriately.
Consider a Kafka message with a JSON payload that represents an e-commerce order. You can use headers to add more information related to this message, such as:
content-type: Specifies the format of the message payload.created-at: Specifies message creation time.trace-id: A globally unique identifier that allows the message to be traced as it flows through the system.
The code below shows how you can do this on the producer side.
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("content-type", "application/json".getBytes());
record.headers().add("created-at", Long.toString(System.currentTimeMillis()).getBytes());
record.headers().add("trace-id", "12345".getBytes());
producer.send(record);The headers are now available on the consumer side. The code below prints the header values, but you can process them as needed.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
for (Header header : headers) {
System.out.println("Key: " + header.key() + ", Value: " + new String(header.value()));
}
}It is important to note that every key within your headers must be unique to avoid ambiguity and prevent conflicts during message processing. Duplicate keys can result in data overrides, loss, and inaccurate data.
Headers headers = new RecordHeaders();
headers.add("key1", "value1".getBytes());
headers.add("key2", "value2".getBytes());
// Adding a duplicate key overwrites the previous value
headers.add("key1", "newValue".getBytes()); // Overwrites "value1" with "newValue"In the above example, adding a duplicate key, such as key1, overrides the previous value. Keys in a record must maintain uniqueness to ensure clear and non-redundant data.
Serialization
Serialization involves converting the header value into a format suitable for transmission or storage. Kafka header values are stored as byte arrays (byte[]). Serialization converts data types like string to a byte array with UTF-8 encoding.
String value = "application/json";
byte[] serializedValue = value.getBytes(StandardCharsets.UTF_8);
record.headers().add("content-type", serializedValue);Similarly, you can serialize a long value, like a timestamp, into bytes using a ByteBuffer.
long timestamp = System.currentTimeMillis();
ByteBuffer buffer = ByteBuffer.allocate(Long.BYTES);
buffer.putLong(timestamp);
byte[] serializedValue = buffer.array();
record.headers().add("created-at", serializedValue);Deserialization
Deserialization converts the byte array back to its original format. For example, you can convert a byte array back into a string using UTF-8 decoding.
byte[] serializedValue = headers.lastHeader("content-type").value();
String value = new String(serializedValue, StandardCharsets.UTF_8);Similarly, you can use ByteBuffer to convert the array back to its long value.
byte[] serializedValue = headers.lastHeader("created-at").value();
ByteBuffer buffer = ByteBuffer.wrap(serializedValue);
long timestamp = buffer.getLong();Tools and libraries
Apache Avro™ is a popular serialization framework that supports rich data structures and schemas. Google Protocol Buffers (Protobuf) is another language-neutral, platform-neutral extensible mechanism. You can also use libraries like Jackson's ObjectMapper to serialize and deserialize JSON objects.
// Serialize using Avro
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<GenericRecord> writer = new SpecificDatumWriter<>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(record, encoder);
encoder.flush();
out.close();
byte[] serializedValue = out.toByteArray();
record.headers().add("avro-header", serializedValue);
// Deserialize using Avro
DatumReader<GenericRecord> reader = new SpecificDatumReader<>(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(serializedValue, null);
GenericRecord result = reader.read(null, decoder);Kafka header use cases
Headers can be used for message routing, prioritization, tracing, and more. Below are common use cases.
Message routing
Headers allow producers to specify precisely where a message should be sent. It increases effectiveness and efficiency in message delivery.
For example, consider the following code snippet:
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("route-to", "consumer-group-1".getBytes());
producer.send(record);In this example, the route-to header declares that the message should be delivered only to consumer-group-1.
Consumer
The consumer checks the route-to header and processes the message only if it is intended for consumer-group-1.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header routeToHeader = headers.lastHeader("route-to");
if (routeToHeader != null) {
String routeTo = new String(routeToHeader.value(), StandardCharsets.UTF_8);
if ("consumer-group-1".equals(routeTo)) {
// Process message intended for consumer-group-1
}
}
}Metadata storage
You can use headers to store your metadata, such as timestamps, content types, and versioning. Storing metadata separately from the payload makes it easy to process and enhances readability.
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("content-type", "application/json".getBytes());
record.headers().add("created-at", Long.toString(System.currentTimeMillis()).getBytes());
producer.send(record);In the code above, content-type represents message format, and created-at represents when the message was created. The information represents important metadata without cluttering the payload.
Consumer
Now consumers can parse the metadata from the headers, such as content type and creation time, to process the message accordingly.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header contentTypeHeader = headers.lastHeader("content-type");
Header createdAtHeader = headers.lastHeader("created-at");
if (contentTypeHeader != null) {
String contentType = new String(contentTypeHeader.value(), StandardCharsets.UTF_8);
// Use contentType for processing
}
if (createdAtHeader != null) {
long createdAt = ByteBuffer.wrap(createdAtHeader.value()).getLong();
// Use createdAt for processing
}
}Tracing and logging
You can include trace IDs and debugging information in headers to enhance observability. Your header data helps you monitor and debug message flows.
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("trace-id", "12345".getBytes());
producer.send(record);The trace-id header allows you to trace the message journey through the system for performance monitoring and debugging.
Consumer
Consumer can use trace-id for debugging as shown.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header traceIdHeader = headers.lastHeader("trace-id");
if (traceIdHeader != null) {
String traceId = new String(traceIdHeader.value(), StandardCharsets.UTF_8);
// Use traceId for monitoring and debugging
}
}Custom consumer processing
Headers enable consumers to make dynamic decisions about processing logic. They allow message handling to be flexible and adaptive.
Producer
You can set up the producer code below to categorize records by type. You can write different conditions that identify the records and change the type names as needed.
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("type", "typeA".getBytes());
producer.send(record);Consumer
The consumer reads the type header to dynamically decide whether to process the message as Type A or Type B.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header typeHeader = headers.lastHeader("type");
if (typeHeader != null) {
String type = new String(typeHeader.value(), StandardCharsets.UTF_8);
if ("typeA".equals(type)) {
// Process as Type A
} else if ("typeB".equals(type)) {
// Process as Type B
}
}
}Security and authentication
Your Kafka headers can include security tokens, which hold authentication information for secure message delivery without exposing sensitive data in the payload.
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("auth-token", "secureToken123".getBytes());
producer.send(record);Consumer
Consumers can use the auth-token header for message authentication before processing. It ensures that only valid consumers process the message.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header authTokenHeader = headers.lastHeader("auth-token");
if (authTokenHeader != null) {
String authToken = new String(authTokenHeader.value(), StandardCharsets.UTF_8);
if (isValidAuthToken(authToken)) {
// Process the message
}
}
}
private boolean isValidAuthToken(String authToken) {
// Validate the authentication token
return "secureToken123".equals(authToken);
}Priority and routing
Priority levels within headers facilitate advanced routing strategies for quality of service (QoS) management, ensuring that high-priority messages get the first turn.
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("priority", "high".getBytes());
producer.send(record);In the code example above, the priority header specifies the message urgency (HIGH, for instance), so the brokers and consumers prioritize its processing over other tasks.
Consumer
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header priorityHeader = headers.lastHeader("priority");
if (priorityHeader != null) {
String priority = new String(priorityHeader.value(), StandardCharsets.UTF_8);
if ("high".equals(priority)) {
// Prioritize processing of high-priority messages
}
}
}The consumer reads the priority header to determine the urgency of the message and ensures that high-priority messages are processed first.
Interoperability
Another header use case is carrying versioning information to facilitate backward and forward compatibility across different systems. This ensures smooth integration in heterogeneous environments.
Producer
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("version", "1.0".getBytes());
producer.send(record)In the code example above, the version header carries the versioning information.
Consumer
Consumers can process the messages based on their versions to ensure compatibility with other downstream system versions.
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header versionHeader = headers.lastHeader("version");
if (versionHeader != null) {
String version = new String(versionHeader.value(), StandardCharsets.UTF_8);
// Process the message based on its version
}
}Stream processing within Kafka
Kafka Streams is a stream-processing library that allows developers to build real-time applications and microservices. Kafka headers can enhance stream processing logic.
The Kafka Streams ProcessorContext class provides methods to access record metadata, including headers.
Example: Accessing Headers in a Kafka Streams Processor
import org.apache.kafka.streams.processor.AbstractProcessor;
import org.apache.kafka.streams.processor.ProcessorContext;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
public class HeaderAccessProcessor extends AbstractProcessor<String, String> {
@Override
public void process(String key, String value) {
ProcessorContext context = context();
Headers headers = context.headers();
Header header = headers.lastHeader("content-type");
if (header != null) {
String contentType = new String(header.value());
System.out.println("Content-Type: " + contentType);
}
// Process the message further
context.forward(key, value);
}
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "header-access-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
StreamsBuilder builder = new StreamsBuilder();
builder.stream("input-topic")
.process(() -> new HeaderAccessProcessor());
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}In this example, HeaderAccessProcessor accesses the content-type header value and prints it. You can also set, add, or modify headers and then dispatch the message for further processing stages.
Best practices for using Kafka headers
Correct header usage optimizes system performance. Let's take a look at some best practices.
Minimize header overheads
Light headers minimize overheads associated with message transmission and processing. They reduce the load on network and storage resources and ensure speed and efficiency.
Keep only what is strictly necessary in your headers. Use small, meaningful keys that reduce header size. For example, instead of using a long key, you may use an abbreviation, as below—ct, instead of content-type.
record.headers().add("ct", "application/json".getBytes());Optimizing the value size through encoding or abbreviations further reduces header size. For example:
record.headers().add("priority", "h".getBytes());h is for high priority, so it becomes compact.
Name keys consistently
Use uniform naming conventions to prevent key conflicts and clarify what each header represents. Keep keys short but descriptive and define rules around using symbols like _ and -. A standard naming convention supports debugging and maintenance and facilitates new developer onboarding for your team.
Validate header data
Header data validation ensures data integrity and prevents errors during message processing. Consumers should check that all required headers are present before processing any message.
Headers headers = record.headers();
if (headers.lastHeader("content-type") == null) {
throw new IllegalArgumentException("Missing required header: content-type");
}You can also validate header values to be in the expected format or data range.
String contentType = new String(headers.lastHeader("content-type").value());
if (!"application/json".equals(contentType) && !"application/xml".equals(contentType)) {
throw new IllegalArgumentException("Invalid content-type: " + contentType);
}Finally, you should introduce mechanisms for handling or logging invalid header data without crashing the system. This includes catching exceptions and then processing or skipping the message based on the severity of the error. For example:
try {
String createdAt = new String(headers.lastHeader("created-at").value());
Long.parseLong(createdAt); // Validate if created-at is a valid timestamp
} catch (NumberFormatException e) {
// Log the error and decide whether to process the message or skip it
logger.error("Malformed header data: created-at", e);
}Kafka header alternatives
Kafka headers may not be the best solution for every use case.
Embed metadata in the message payload
You can embed metadata directly within the message payload using structured formats like JSON, Avro, Protocol Buffers, or Thrift—for example, a JSON message containing a "metadata" field beside the actual message.
{
"metadata": {
"key1": "value1",
"key2": "value2"
},
"data": {
"actual": "message content"
}
}Embedding metadata is simple but increases the message payload size consumers must parse and process. Any changes in the payload format also require updating all producers and consumers.
You might want to use this approach for small, self-contained applications where payload data volume is low, and setup scenarios involving additional infrastructure are undesirable.
Separate metadata topic
You correlate messages between the main topic and a separate metadata topic using a common key. The main message payload remains light and logically separates metadata from the main flow. However, consumers must now handle subscriptions and correlate messages between two topics. This introduces complexity and latency due to consumer message synchronization.
You can consider the approach when metadata is high in volume or changes frequently. It is also helpful for multi-stage processing pipelines where different stages may want access to metadata independently.
Kafka Streams state store
If your application already uses Kafka Streams, you might want to integrate metadata management with processing logic. A Kafka Streams state store can maintain metadata and enrich messages during processing. Since it is co-located with stream processing, it offers fast and efficient metadata access.
This approach is also helpful in stateful stream processing, where metadata and message data are transformed together. For example, a user profile stored in the state store enriches user activities in one Kafka topic. A user activity tracking system also processes the user profile in real time.
The only downside is handling the state store size; scaling requires extra management effort.
Conclusion
Kafka headers have several use cases, but debugging them is a challenge. Redpanda Console is a web UI console that you can use to gain visibility into your messages, debug them in real time, and manage your configurations.
For example, you can filter the data stream for messages that match a particular user ID, timestamp, range of value, or key within the message headers or payload. Beyond messages, you can manage your entire Kafka ecosystem from a single place. Check out Redpanda to learn how it can make streaming data incredibly simple.