

Kafka Connectors—Overview, use cases, and best practices











Kafka connectors
Apache Kafka® has a pluggable architecture that makes it easy to build complex pipelines with no code using Kafka Connect. The term “Kafka connectors” refers to various Kafka Connect plugins you can use to move large data sets in and out of Kafka. You can simply plug existing connectors into different databases or file systems and customize them to suit specific requirements. This simplifies the process of streaming data from various data sources into Kafka and from Kafka to a wide range of targets.
This chapter explores Kafka connector concepts, configurations, and use cases.
Summary of key Kafka connector concepts
Types of Kafka connectors
At its core, Kafka Connect is a runtime that runs and manages data pipelines involving Kafka. Kafka connectors are the plugins you use in Kafka Connect to establish a connection to an external data source. You can customize the connectors to your specific needs.
Source connectors
Source Connectors poll data from external sources such as databases, message queues, or other applications. For instance, a Source Connector for a MySQL database reads changes in the database table and converts them into Connect Records, which are then sent to the Kafka cluster.
Sink connectors
Sink Connectors save data to the destination or sink, such as Hadoop Distributed File System (HDFS), Amazon Simple Storage Service (S3), or Elasticsearch. For example, a Sink Connector for Elasticsearch takes Connect Records from Kafka and writes them into Elasticsearch in the required format.

Kafka Connect provides a framework and a code execution runtime to implement and operate source and sink connectors.
Code example to set up a new connector
Consider we have an Orders table for an eCommerce company, with 5 columns as shown.
Say we want to set up a MySQL JDBC source connector so that when you add a new row to the orders table, the connector captures the change and produces a message. The message contains the new row data serialized as the following JSON object.
{
"order_id": 12,
"customer_id": 93,
"product_id": 105,
"quantity" : 2
"order_date": "2023-04-11"
}A connector file mysql-order-connector.json looks something like below.
{
"name": "jdbc-source-connector",
"config": {
"Connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/ecommerce",
"connection.user": "root",
"connection.password": "admin",
"mode": "incrementing",
"tasks.max": 3, // Maximum number of tasks the connector can create
"topic.prefix": "topic-", // Prefix to add to topic created by the connector
"table.whitelist": "orders", // Whitelist of tables to include in the connector's scope
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
// Converter class for the key serialization - format of key data be converted
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
// Converter class for the value serialization - format of value data be converted
}
}You can pass the connector to the worker we created in the previous section about Kafka workers. The worker is running on REST port 8083.
$ curl -X POST -H "Content-Type: application/json" --data @mysql-order-connector.json http://localhost:8083/connectorsThe connector also creates a topic called topic-orders. You can run the code below to check your topics.
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --listNow, you can use the consumer client to listen to the messages under topic-orders
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-orders --from-beginningKafka Cloud Tasks
A task is a connector instance that performs the data transfer. Each task in a connector handles a data subset, and multiple tasks can run in parallel.
Tasks do not retain their state internally. Instead, the state of each task is maintained within dedicated topics in Kafka.
- ‘
config.storage.topic’ stores the connectors and task configurations - ‘
status.storage.topic’ stores the connector status and tasks.
The corresponding connector manages both topics. You can initiate, halt, or restart tasks as needed, ensuring a robust and scalable data pipeline architecture.
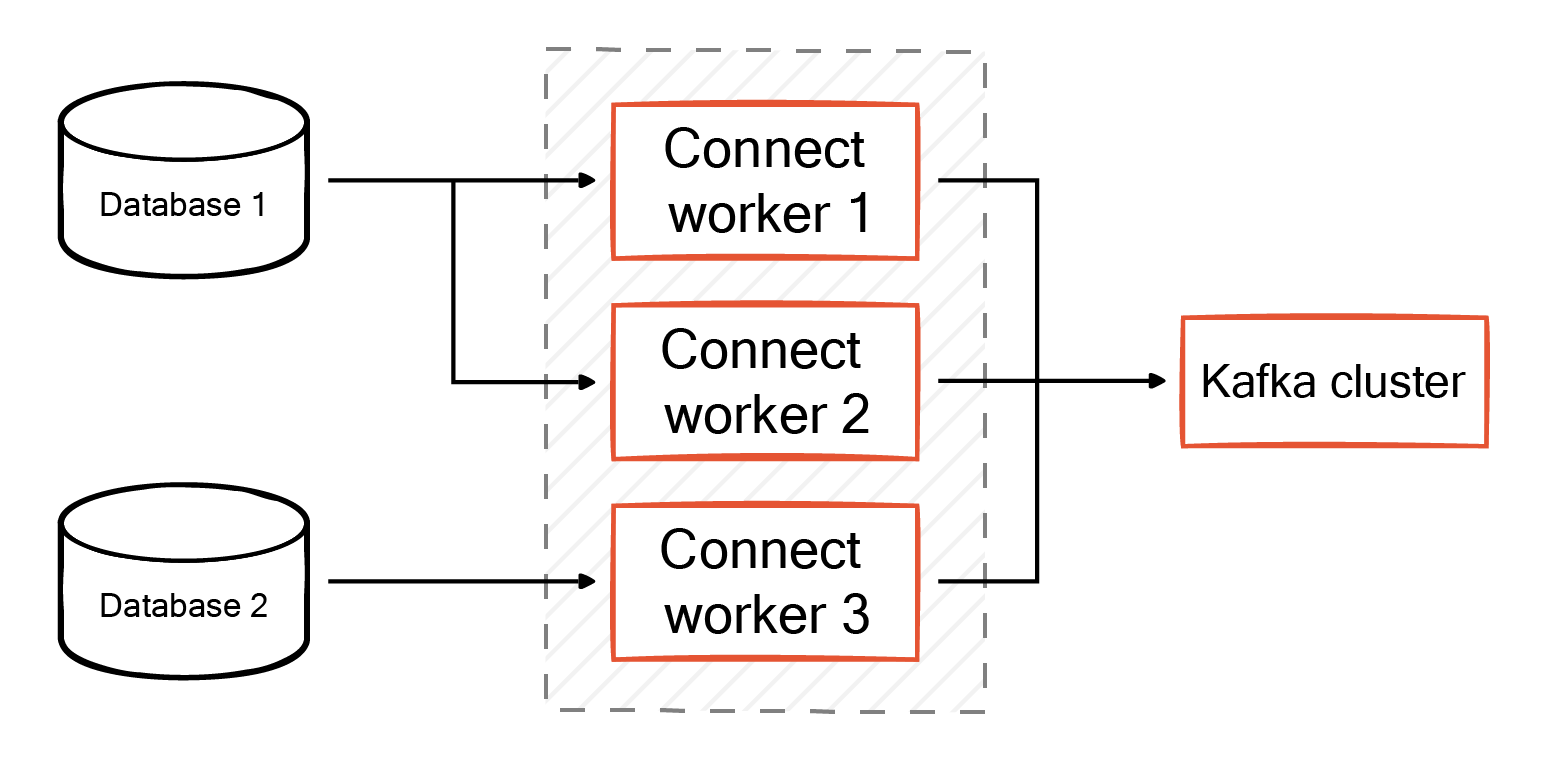
Kafka Cloud Workers
Workers are the processes on which connectors run. You can configure Kafka Connect as a standalone or distributed system. In a standalone system, there is only one worker, while in a distributed system, there are multiple workers. The workers evenly distribute all connectors and their tasks among themselves, ensuring each worker handles a comparable workload.
Worker rebalancing also occurs when connectors adjust the number of tasks they require or when you update configurations. If one worker fails unexpectedly, another worker takes over the task of the failed worker.
Kafka Cloud Converters
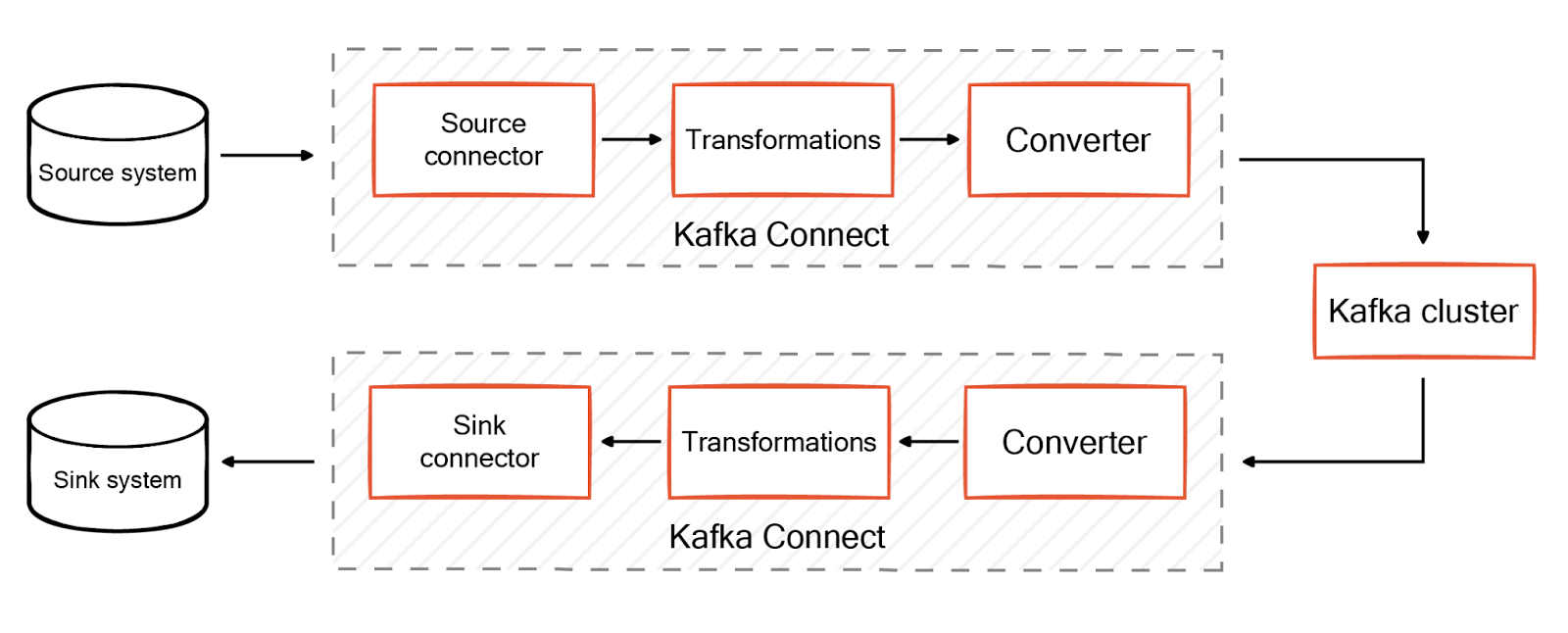
Connectors work with converter components to ensure compatibility between Kafka's internal data format and external systems. Messages must be transformed into byte arrays before ingestion to Kafka and re-transformed for the target data system. For source connectors, converters serialize the Kafka message before writing to a cluster. For sink connectors, converters deserialize the byte stream from Kafka before passing the message to the connector.

Kafka Connect provides default converters like JSON. You can also create custom converters to accommodate diverse data formats.
Kafka Cloud Transformers
Transformers, or Single Message Transformations (SMTs), are optional components that transform messages as they move through Kafka Connect. Different connectors running in the same Kafka Connect cluster can have different transformations. You can use transformations to change data types, add field names, or modify topic names. It is also possible to chain multiple transformations in a specific order to perform several modifications.
For source connectors, transformations are invoked after the connector and before the converter. For sink connectors, transformations are invoked after the converter and before the connector.
Kafka Cloud Predicates
Predicates allow you to use transformations based on certain conditions. They allow you to define rules determining whether a message should proceed through the pipeline or be filtered out. Some transformations, such as filters, are always intended to be used with a predicate.
Below is an example of a JDBC Source connector that copies data from the database to the Kafka cluster. Here are the transformers:
InsertFieldadds a field calledtopicwith a static valuejdbc-mytopicto each record.MaskFieldmasks thepasswordfield in each record.- Predicate
filterInActivefilters out records from topics matching the pattern “.*Inactive.*”.
{
"name": "jdbc-source-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydatabase",
"connection.user": "myuser",
"connection.password": "mypassword",
"topic.prefix": "jdbc-",
"poll.interval.ms": 1000,
"tasks.max": 1,
"transforms": "InsertField,MaskField",
"transforms.InsertField.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.InsertField.static.field": "topic",
"transforms.InsertField.static.value": "jdbc-mytopic",
"transforms.MaskField.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.MaskField.fields": "password",
"predicates": "filterInActive",
"predicates.filterInActive.type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches",
"predicates.filterInActive.pattern": ".*Inactive.*"
}
}How to configure Kafka Cloud connectors
You need to define configurations to run supported connectors. Some configuration options are set in the worker properties you provide when you start Kafka Connect and apply by default to all connectors; others are specified in the individual connector configurations.
For example, to use the FileStreamSinkConnector to stream the contents of a topic called topic-to-export to a file called /tmp/sink.out, you create a file named sink-config.json that contains the desired configuration for the connector.
{
"name": "file-sink",
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"tasks.max": "1",
"topics": "topic-to-export",
"file": "/tmp/sink.out",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}If you want to add transformations, you also have to declare them in the connector configurations The connector then applies the transformations to the messages it handles.
Once you have updated the configurations, start Kafka Connect by navigating to the directory containing your Kafka distribution and running the following command.
./bin/connect-distributed.sh ./config/connect-distributed.propertiesUse cases for Kafka cloud connectors
Capturing data changes
You can use connectors to capture data modifications in databases such as MySQL, PostgreSQL, or MongoDB in scenarios where maintaining up-to-date copies is essential for analytics. Connectors configured for specific databases ensure efficient and reliable change replication. You can also synchronize changes across multiple systems and facilitate near-real-time data processing and analysis.
Building data lakes
Connectors can transfer open-source data into specialized data lakes or archive it to cost-effective storage solutions. This is useful when dealing with large data volumes or when you want to retain data over extended periods for compliance or auditing. In machine learning/AI, you can avoid synthetic data generation and make actual event streams accessible for model training.
Aggregating logs
Consolidating data such as logs, metrics, and events from all applications simplifies management. Without Kafka connectors, integrating observability data across multiple systems would require significant effort in development and deployment. It would necessitate updates across various points in the software when modifying data structures or destinations. Kafka connectors reduce the complexity of data collection. You can leverage many pre-built data connectors without custom coding.
Mirroring clusters with MirrorMaker and Kafka
The action of copying data between two Kafka clusters is called mirroring. Kafka MirrorMaker 2 is a tool that enables data replication between Kafka clusters. It utilizes the Kafka Connect framework for efficient data mirroring.
MirrorSourceConnector
The MirrorSourceConnector in MirrorMaker 2 replicates topic data across Kafka clusters while preserving each record's original partition assignment. It mirrors topic configurations, including partition counts and ACLs, and periodically synchronizes them. Additionally, the connector establishes an offset-syncs topic that maps offsets between source and target clusters.
MirrorCheckpointConnector
The MirrorCheckpointConnector replicates consumer group offsets from a source Kafka cluster to a target cluster. It identifies consumer groups on the source cluster, retrieves their committed offsets, and uses the offset-syncs topic to accurately translate offsets for the target cluster. It stores the translated offsets as checkpoints in a compacted topic with a single partition on the target cluster.
MirrorHeartBeatConnector
The MirrorHeartbeatConnector regularly generates compact heartbeat records. These records contain source and target cluster identifiers as keys and timestamps as values. They are stored in a dedicated heartbeats topic with a single partition. The presence of the heartbeats records serves as a reliable indicator of the mirroring process's operational status, even in the absence of other data traffic.
Best practices when using Kafka Cloud connectors
Deploy Kafka Connect in distributed mode for scalability and fault tolerance. This allows you to scale out by adding more workers as needed.
Incorporate a schema registry in Kafka Connect for schema management across systems. This will maintain consistency and reduce the risk of data corruption or schema conflicts.
Set up Kafka monitoring and alerting for Kafka Connect clusters. To detect issues early, you can monitor metrics such as throughput, latency, error rates, and connector status. You can also implement a dead letter queue (DLQ) for messages that fail processing.
Conclusion
Kafka and its connectors are one among several options for building data pipelines. Kafka is a decade-old solution that comes with several complexities in configuration and management. As your data grows, configurations become complex, requiring ongoing maintenance and fine-tuning. For example, if a task fails, you must manually restart tasks that fail by using the Kafka Connect REST API.
Redpanda Connect is an alternative solution for building data pipelines with Redpanda, a modern data ingestion platform built from the ground up that keeps developers in mind. It provides several advanced features that utilize cloud infrastructure and cutting-edge technologies to drive cost efficiencies. Redpanda Connect features 200+ certified and enterprise-ready pre-built connectors. You can deploy it as a static Go binary without any external dependencies. It is available in both enterprise and community editions.