




AI agent governance at scale: the four pillars every enterprise needs
Enterprise agents need governance infrastructure, not just better models
To power AI at scale, organizations must adapt to the evolving role of the modern data warehouse









Artificial intelligence (AI) is transforming nearly every aspect of our digital lives. Now, organizations are either evaluating, rolling out, or optimizing AI at some scale. The AI wave is poised to rival or even surpass the mobile revolution in impact, with every organization needing to determine how it can benefit from or enable AI for others.
Regardless of where you currently fall in this journey, here are two truths you should know: AI needs context to be useful, and the state of the art for AI is rapidly evolving.
The data warehouse is the linchpin for the first truth—it’s where organizational data sprawl converges, making it the perfect central source of truth for AI agents. In light of the second truth, we also need that platform to be agile and capable of keeping pace with innovation.
As NVIDIA CEO Jensen Huang stated at last year's Snowflake Summit, AI allows for extracting more at each phase of the data flywheel.
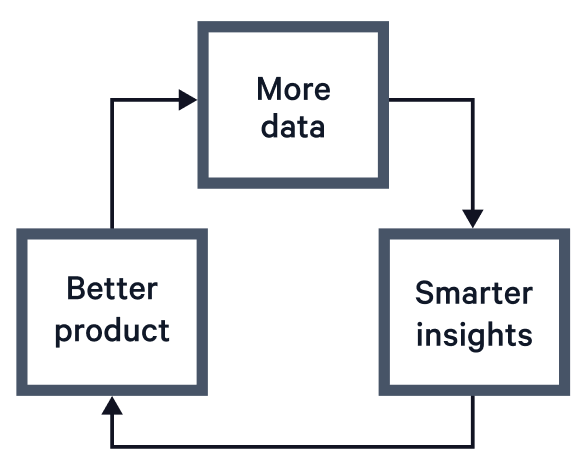
At its core, the flywheel is that people using your products will generate usage data. More usage data will allow you to derive better insights into how people are benefiting from your products. In turn, you can better improve the product, ultimately deriving more consumption (and more data). Let's break down how AI improves your ability to execute each of these phases:
AI can enhance the data analysis process in several ways. It can automate the boilerplate of writing dashboards and SQL queries. It can process reports of unstructured data (bug reports, user feedback, and support questions) to identify common trends and patterns. You can use embeddings to cluster information at large scale and identify gaps in user journeys, as well as missed opportunities.
AI can be integrated into a product suite in many ways: enabling real-time personalization or recommendations, giving users the ability to automate tasks, or using models to summarize historical activity and trends. The important part when integrating AI into a product is to add guardrails, measure performanc,e and give you and your users the confidence that the agent's automations are working as intended. Lastly, product and development teams can integrate AI into their workflows to ship and test new features faster, allowing them to move timelines up instead of back.
AI-enhanced products have numerous opportunities to capture and measure engagement by analyzing the prompts sent to chatbots or using AI to reason about data that would have been too tedious to analyze manually. Additionally, features like AI-based automation enable power users to engage more deeply with your product and derive even greater value. Models are also able to clean and extract structure from previously unusable data lake sources, giving you even more data to work with.
One does not simply slap a chatbot onto an existing product and call it AI-enhanced. It takes thought and care to see where you can apply the most value while avoiding risks associated with this new and non-deterministic technology.
The key thing to remember is that these models are stateless and have no context about what task you're attempting to prompt them to complete. You must provide them with all the information and instructions needed to complete their task. That context must be both accurate and current—stale information undermines performance, leads to drift and introduces risk in decision‑making.
For example, a sales development representative would need to know about new features that have been launched or the pain points a prospective customer might be experiencing. An AI working on behalf of your support team needs to be able to identify other recent issues, recommend workarounds for common problems, and quickly surface relevant historical information about a customer and their usage of the product.
To enable these agents, you need the following:
With more recent AI advancements, the window between insight and action is shrinking. You want to be able to invoke an agent to act on an event as it happens, not when the next job runs. When combined with the rapid innovation of AI capabilities, you need a data platform that is flexible enough to accommodate new features and requirements.

Building a data platform varies greatly depending on your technology stack, infrastructure provider and industry. However, they all share common patterns, and one in particular is pivotal to iterating quickly: streaming.
Data streaming is the continuous, incremental flow of data emitted to a message bus or write ahead log (WAL). The primary advantage of adopting a streaming engine is that it enables you to decouple the producers (applications generating events) and the consumers (the receivers of records in the log). This enables dynamically adding or removing sources easily, taking advantage of your data in real time, surfacing the latest information to your applications and triggering agents when the event first takes place.
Take a full-text or a vector search engine as an example. In these engines, indexing data causes rebuilding of various structures on disk (especially in vector databases, which need a large language model to compute embeddings for each piece of text). This makes batching operations coming from a single source much more effective. Plus, the replayability from a long-lived stream is appealing for testing out different embedding models or different chunking techniques in your retrieval augmented generation (RAG) pipelines.
Traditionally, this wouldn't be feasible, but modern streaming engines can leverage tiered storage to offload cold data to object storage, meaning that you can keep full replayability without needing to plumb another data path. All of these auxiliary systems can become materialized views of the raw event stream.
A good example is using change data capture (CDC) to stream database changes into your streaming engine. This enables reactive consumers and keeps auxiliary systems (like full-text search or analytics databases) in sync without complicating your application logic.
While CDC streams can strain databases (e.g., by delaying WAL cleanup) a single stream feeding a fan-out system simplifies architecture and improves reliability. It avoids complex capacity planning and makes it easy to add features or reactivity to your application layer. For instance, triggering an agent when a user downgrades their plan can be done via the CDC stream on the user_plans table, without redesigning the application layer to support such reactivity.
Just as streaming was central to the operational use cases above, these same events can be materialized in your data warehouse, providing you with fresh and up-to-date information for your analytical queries. The direct event data can be converted into open formats like Apache Iceberg™ (some streaming engines can do this directly, such as Redpanda's Iceberg Topics) or stream it into proprietary formats (such as Snowpipe Streaming in Snowflake®). Alternatively, streams can be joined and processed in real time so data lands in any form to maximize its queryability, without expensive batch jobs that constantly reprocess the entire dataset.
Open formats like Iceberg give you freedom and flexibility to choose from a number of different query engines. For example, say you're a Google Cloud Platform (GCP) user but use Snowflake as your data warehouse for business analysts and AI teams.
Leveraging Apache Iceberg means that you can keep Snowflake as your primary data warehouse, but also enable BigQuery and all the integrations available for model serving and training without having to store your data twice. This happens without comprising functionality in either platform, as Iceberg comes with a full ACID transactional model, well-defined schema evolution policies, time-traveling queries and fine-grained access controls through a catalog like Apache Polaris. Proprietary systems manage both the data and the metadata for the data warehouse.
However, with Iceberg, you have the option to keep the metadata in proprietary systems or choose an open standard, such as the Apache Iceberg REST catalog, for metadata management.
Streaming also enables transforming and joining your data as it's already in motion, saving you from costly reprocessing of data in large batch jobs. For example, if you have compliance or masking requirements before data lands in long-term storage in the analytical plane of your data platform, you can do a small stateless transformation of your data as it lands in the data warehouse.
Using a streaming engine as the power grid of your data platform unlocks a great deal of flexibility and responsiveness to take advantage of your data in real time. When you have a loosely coupled system that is moving fast, there are a few best practices to keep in mind to keep your systems robust and reliable.
First of all, it's important to have a schema registry so when new applications are set up to read from your data streams, they can seamlessly handle the evolution of the schema safely. These schemas become the contract between teams, just like how HTTP-based services have API contracts.
When streaming data to the data warehouse, keeping your schemas synced between your schema registry and query engine catalog ensures that both batch and streaming systems work with a consistent view of the data. Hooking up schema changes and publications as part of your CI/CD pipelines and infrastructure-as-code (IaC) can also help catch issues in your engineering teams earlier during development, rather than in staging or production environments.
As your organization grows and teams make changes, having mechanisms for lineage can help track down issues quickly or understand where data is coming from. Using best practices, such as Open Telemetry tracing standard conventions and propagating the tracing using record headers, is particularly helpful as organizations adopt Open Telemetry for all their observability data.
While event-driven architectures unlock adaptable, resilient and responsive platforms, they can be seen as expensive. You can keep costs low by leveraging features like tiered storage to offload cold storage, compression to reduce storage size and bandwidth, efficient formats like Google Protocol Buffers or Apache Avro, and tuning batching to keep the streaming system fast and performant. As with any system, start with good observability and monitor usage as the platform and usage scale.
While the best practices around security and these new AI applications are evolving all the time, the fundamentals for data platforms, such as role-based access control, fine-grained access control lists (ACLs) and the principle of least privilege, apply to both streaming and batch datasets. Take advantage of standards like OpenID Connect for authentication and audit logging to monitor access in a uniform manner across all systems.
Lastly, real-time streaming data platforms enable emerging trends like AI operations (AIOps) to allow data systems to monitor, optimize and react to changes in real time. Without streaming, you'll be forced to set up a periodic job, increasing the iteration cycle and reducing the amount of training data for AI agents to handle operational tasks in the platform.
As technology advances, the gap between insight and action is shrinking. Automated systems can produce and process data instantaneously, and AI is unlocking this in previously impossible areas.
Streaming serves as the backbone for a data platform, enabling all these real-time use cases, and it will become increasingly important as AI is further democratized through open-source models and the cost of adopting these powerful AI models decreases.
As organizations seek to increase autonomy for their IT systems, it's essential to ensure that your data platform is designed to respond in real-time and keep pace with the rapid pace of innovation.
If it isn’t and you’re in the market for a real-time data platform that can power your AI projects, learn what Redpanda can do for you. If you have questions, jump into the Community Slack and ask our team.
Originally posted on The New Stack
Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?

How we turned opaque agent behavior into governed, provable workflows
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.