




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Learn the fundamentals of schema registry for Kafka and how Redpanda schema registry makes it all much simpler








Redpanda provides a simpler, integrated way to store and manage event schemas in Kafka. It eliminates the need for Zookeeper® and the JVM, autotunes itself for modern hardware, and ships in a single binary. This design makes Redpanda lighter, faster, and simpler, offering lower latencies and reduced cloud spend without sacrificing data reliability or durability.
In Kafka, a serializer converts a business object in memory into a byte array to save or transmit it easier. A Kafka producer client invokes a serializer before a message is written to the network. Conversely, a deserializer constructs a business object from a byte array, and a Kafka consumer client invokes a deserializer right after it reads a message from the network. These processes use the schema to influence the shape of data.
A schema is the logical description of how data is organized. It serves as human-readable documentation for data, enabling you to understand the data, verify that the data conforms to an API, generate serializers for the data, and evolve that API with predefined levels of compatibility.
When a schema registry is involved, the serializer embeds the schemaID into each message. The serializer first checks whether the schemaID for the given subject exists in the local schema cache. If it isn’t in the cache, the serializer registers the schema in the schema registry and collects the resulting schemaID in the response. The serializer then adds padding to the beginning of the message, containing a magic byte and the schemaID, before serializing the message and returning the byte sequence to the producer.
A schema registry provides a central repository for schemas, allowing producers and consumers to seamlessly send and receive data between them. It maintains a history of schemas and supports a schema evolution strategy, so you can plan how future applications will maintain compatibility with a certain schema—even if you add or remove fields later.
A schema registry is necessary because it allows the serializer to share the writer's schema with the deserializer. It provides read and write APIs to register, discover and retrieve schemas during the serialization and deserialization process. This central location for schemas is independent of producers and consumers, making it easier to manage schemas as they evolve and the number of consumers increases.
In a nutshell, a schema can be considered as human-readable documentation for data. It’s the logical description of how the data is organized, which enables you to "understand" the data, verify the data conforms to an API, generate serializers for the data, and evolve that API with predefined levels of compatibility.
A schema registry provides a central repository for those schemas, allowing producers and consumers to seamlessly send and receive data between them. If you’re familiar with Apache Kafka®, then you might have encountered a Kafka-compatible schema registry—a separate component that you deploy outside of your Kafka cluster, since Kafka itself doesn’t have one built-in. But understanding how a schema registry works, the terminology involved, and how to use one effectively can present a steep learning curve.
In this series, we’ll walk you through schema registry for Kafka, how it all works, and introduce you to Redpanda schema registry as a simpler, integrated way to store and manage event schemas in Kafka.
Although before getting into why you’d need a schema registry, you should first understand a few fundamental concepts: message serialization and deserialization.
In the Kafka client API model, a message (a record) is the smallest data exchange unit. A message contains a key and a value, carrying arbitrary information related to business use cases.
A serializer converts a business object in memory into a byte array to save or transmit it easier, so a Kafka producer client invokes a serializer before a message is written to the network. On the other hand, a deserializer reverses the process by constructing a business object from a byte array, and so a Kafka consumer client invokes a deserializer right after it reads a message from the network.
Since a schema defines the structure of the data format, serializers and deserializers use the schema to influence the shape of data during the serialization/deserialization process. In the context of Kafka APIs, serializers and deserializers are a part of the language-specific SDK, and support data formats including Apache Avro™, JSON Schema, and Google’s Protobuf. (For Kafka, Avro is by far the most popular choice for data serialization.)
The following figure sums it all up:
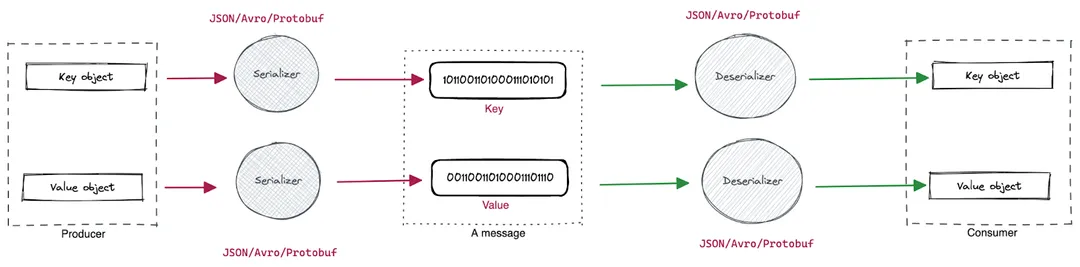
When there's a message, the serializer does its job based on the schema specified. This schema is often called the writer's schema. When the message gets deserialized, the deserializer always needs a schema to continue, and it’s called the reader's schema.
Now, the question is how the serializer shares the writer's schema with the deserializer. Well, there are two ways:
But what if we keep the schemas in a central location, independent of producers and consumers? Also, providing them with read and write APIs to register, discover and retrieve schemas during the serialization and deserialization? This is why schema registry exists.
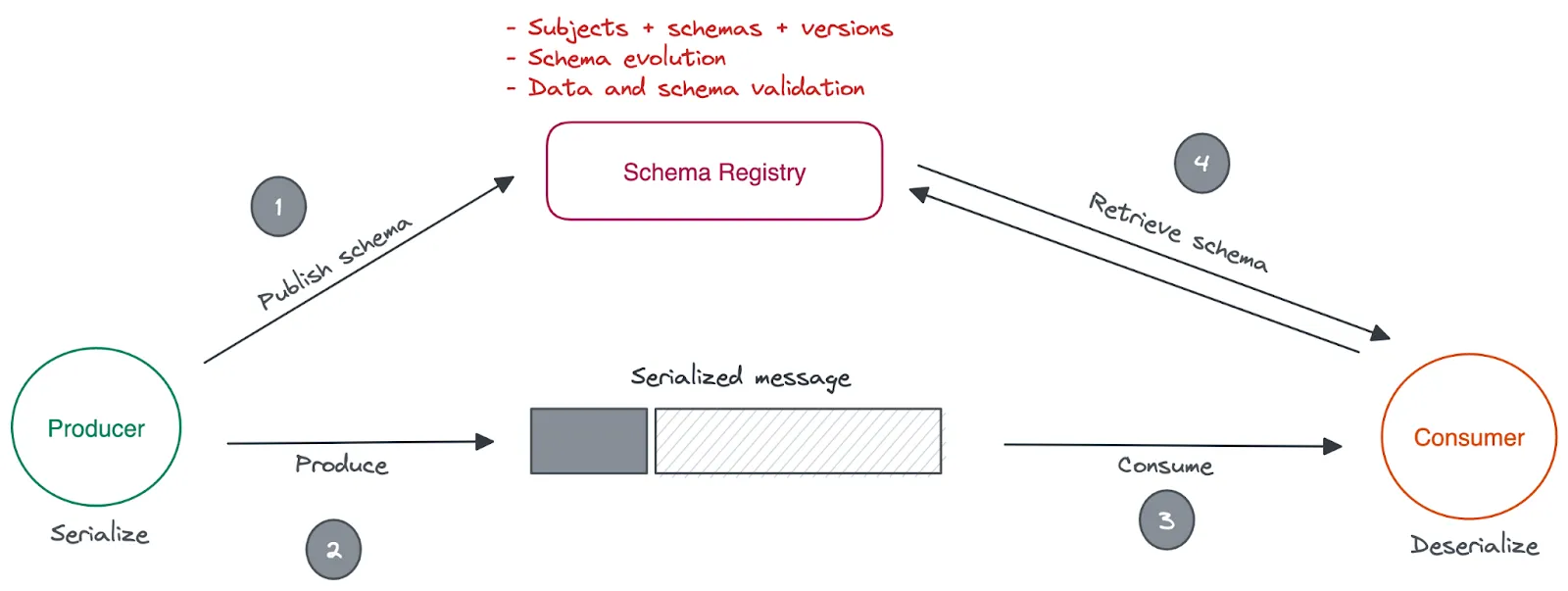
Kafka only transfers data in byte format. In fact, it doesn’t know what kind of data it’s sending or receiving. But producers and consumers need to know what type of data they’re handling so they can process it correctly. When a producer sends a message to a Kafka cluster, the data can be in any format the producer chooses. So every time you change the schema for messages, every related consumer and producer needs to know.
A schema registry makes this easy by providing a central repository that consumers and producers can access to find out the schema of a given message. The schema registry also maintains a history of schemas and supports a schema evolution strategy, so you can plan how future applications will maintain compatibility with a certain schema—even if you add or remove fields later.
A schema registry maintains a hierarchy of information for keeping track of subjects, schemas, and their versions.
When a new schema is registered with the schema registry, it’s always associated with a subject, representing a unique namespace within the registry. Multiple versions of the same schema can be registered under the same subject, and a unique schema ID identifies each version. The subject name is used to organize schemas and ensure a unique identifier for each schema within the registry.
For example, once you publish the initial version of the schema, the registry returns schemaID=1. Then create another version for the schema, and the registry returns schemaID=2. Likewise, the schemaID monotonically increases as the version is increased.
The serialization process is quite different when a schema registry is involved. In short, the serializer embeds the schemaID into each message, allowing the deserializer to use it while retrieving the schema from the registry during deserialization.
Let’s zoom into the end-to-end serialization and deserialization process in a Kafka-compatible API client.
First, the producer hands over the message to the respective key/value serializer. Then the serializer needs to figure out which schema version it should use for serialization. For that, the serializer first checks whether the schemaID for the given subject exists in the local schema cache. At this point, the serializer can derive the subject name based on several strategies, such as the topic name. However, you can explicitly set the subject name if needed.
If the schemaID isn’t in the cache, the serializer registers the schema in the schema registry and collects the resulting schemaID in the response. Usually, the serializer does that automatically.
In either case, the serializer should have the schemaID by now and proceeds with adding padding to the beginning of the message, containing:

Finally, the serializer serializes the message and returns the byte sequence to the producer.
Basically, the consumer fetches messages from Redpanda and hands them over to the deserializer. The deserializer first checks the existence of the magic byte and rejects the message if it doesn't.
The deserializer then reads the schemaID and checks whether the related schema exists in its local cache. If that exists, deserialization happens with that schema. Otherwise, the deserializer retrieves the schema from the registry based on the schemaID. Once the schema is in place, the deserializer proceeds with the deserialization.
Redpanda is a Kafka API-compatible streaming data platform that eliminates Zookeeper® and the JVM, autotunes itself for modern hardware, and ships in a single binary to give you 10x lower latencies and cut your cloud spend—without sacrificing your data’s reliability or durability.
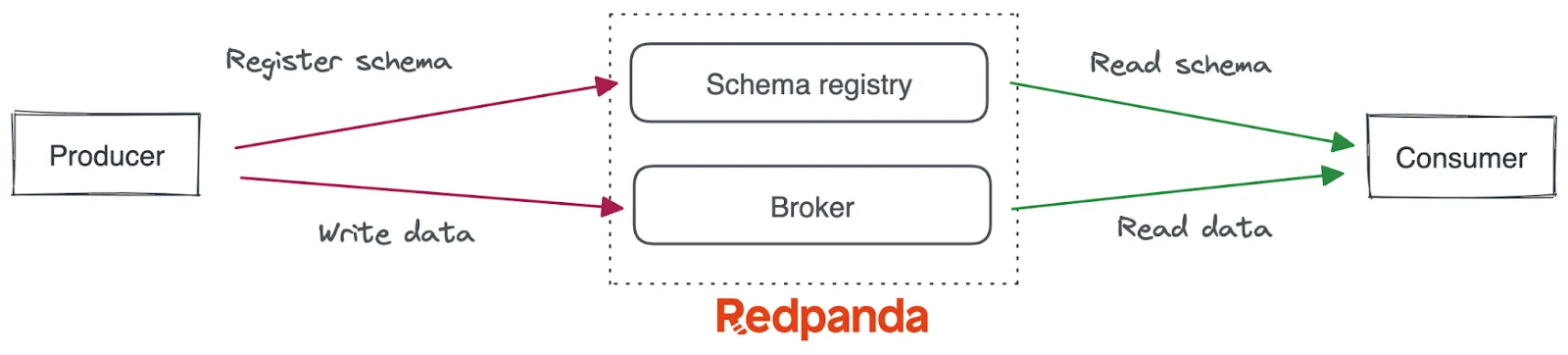
Essentially, Redpanda is designed from the ground up to be lighter, faster, and simpler to operate. In keeping with that mission, we built the schema registry directly into Redpanda. This means there are no new binaries to install, no new services to deploy and maintain, and the default configuration just works. In other words, Redpanda stores your schemas on the same Raft-based storage engine and exposes RESTful interfaces on every broker to manipulate the schemas programmatically.
While there are several Kafka API-compatible schema registry implementations available, you need to install and manage them separately as well as the Kafka deployment. Redpanda cuts your efforts by embedding its schema registry within the broker distribution itself. Plus, since Redpanda is fully compatible with Kafka client APIs, you can use existing Kafka serializers and deserializers with Redpanda without a single code change.
The diagram below shows how it all works together.
Want to see it in action? Let's jump right in and start Redpanda using Docker on Linux:
docker network create redpanda-sr
docker volume create redpanda-sr
docker run \
--pull=always \
--name=redpanda-sr \
--net=redpanda-sr \
-v "redpanda-sr:/var/lib/redpanda/data" \
-p 8081:8081 \
-p 8082:8082 \
-p 9092:9092 \
--detach \
docker.vectorized.io/vectorized/redpanda start \
--overprovisioned \
--smp 1 \
--memory 1G \
--reserve-memory 0M \
--node-id 0 \
--check=false \
--pandaproxy-addr 0.0.0.0:8082 \
--advertise-pandaproxy-addr 127.0.0.1:8082 \
--kafka-addr 0.0.0.0:9092 \
--advertise-kafka-addr redpanda-sr:9092That will bring up a single node Redpanda cluster, along with the schema registry.
Registry API endpoints are documented with Swagger at http://localhost:8081/v1 or on SwaggerHub. You can use a programmatic client application or CURL commands to interact with the registry.
In this first post, you learned the importance of having a schema registry in a streaming data architecture and some inner workings of message serialization and deserialization within the scope of a Kafka client application. Moreover, we explored the basics of the Redpanda schema registry and how it supports modern architectures like serverless Kafka.
In our next post, we’ll walk you through how you can use Redpanda’s built-in schema registry to produce and consume Avro messages—in just five steps. Make sure to subscribe to our blog so you don’t miss a post!
To learn more about Redpanda, check out our documentation and browse the Redpanda blog for tutorials and guides on how to easily integrate with Redpanda. For a more hands-on approach, take Redpanda's free Community edition for a spin.
If you get stuck, have a question, or just want to chat with our engineers and fellow Redpanda users, join our Redpanda Community on Slack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

