




Drag, drop, done: a visual composer for Redpanda Connect
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Everything you need to know about Redpanda Tiered Storage: remote, read-only replica topics








Tiered Storage, announced in 2021, is a core part of Redpanda’s data streaming platform that underpins the Agentic Data Plane.
Our first step in bringing it to life was to develop archival storage. This subsystem uploads data to the cloud (so named because cloud storage was then primarily used for backups). The data in cloud storage includes topic and partition manifests, making it self-sufficient and portable.
NOTE: Redpanda communicates via the S3 API, and although many cloud storage providers support this protocol, we only officially support AWS S3, GCP Cloud Storage, and Azure Blob Storage. For development, you can also use MinIO.
We then built topic recovery, the feature that allows us to restore local topics from cloud storage. After that, we launched Tiered Storage, giving Redpanda users a way to save on storage costs by offloading log segments to cloud storage.
Together, all of these standalone features combine in v22.2 to enable Remote Read Replicas.
Remote Read Replicas (RRR) are clusters for which particular topics are read-only, because they originate in a different cluster. These Redpanda clusters are useful for serving additional consumers without increasing the load on a production cluster. When a user has a topic with archival storage enabled, they can create a separate cluster for consumers and populate its topics via cloud storage. (Check out the documentation for Remote Read Replicas.)
Tip: If you’re using AWS, enable transfer acceleration on your buckets to replicate the archived data as quickly as possible.
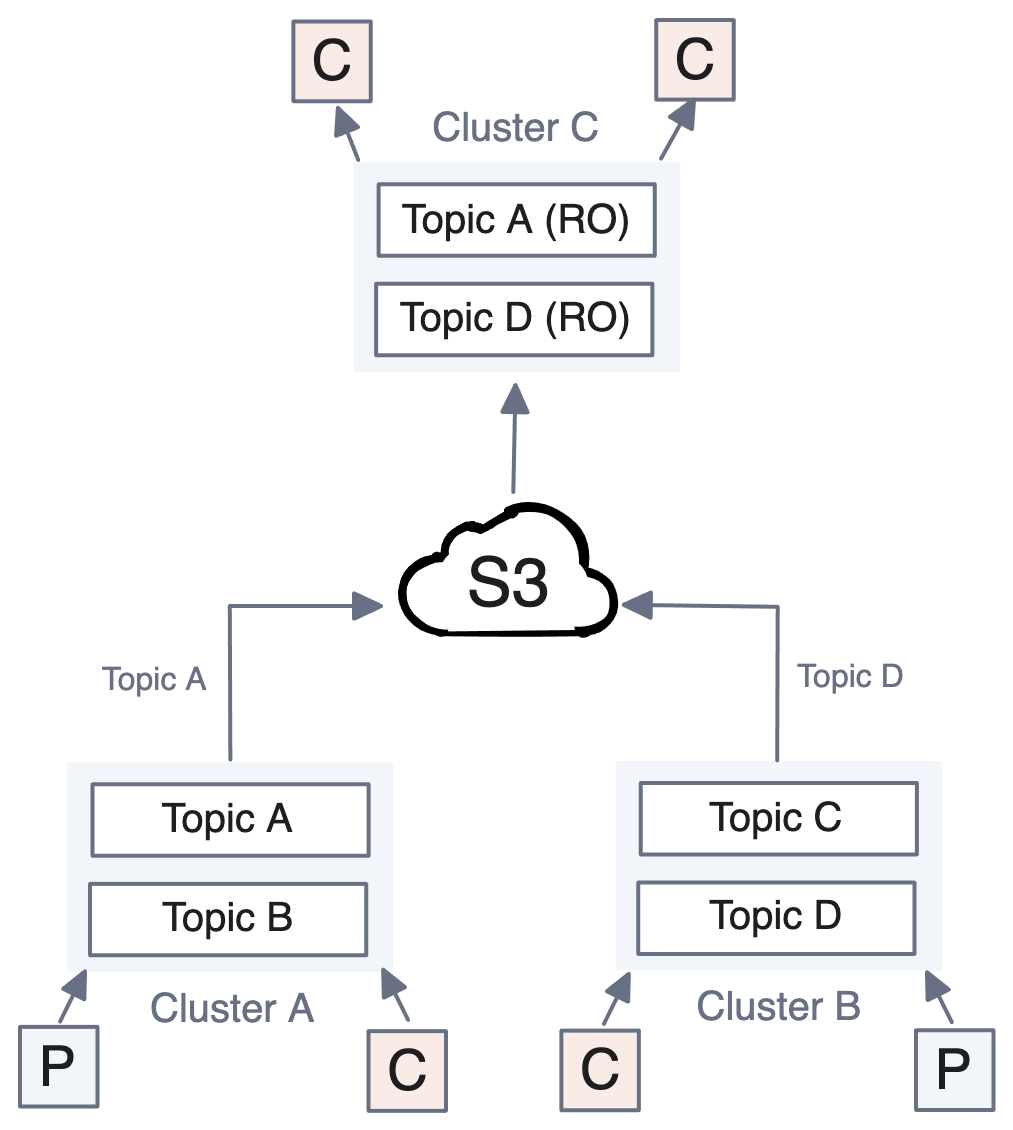
As you can cherry-pick which topics are enabled for RRR, read replicas afford unparalleled flexibility in cluster size for read-only workloads, regardless of the size of the data set.
Pretty neat. But how does it work?
Tiered Storage does the heavy lifting for RRR. It already handles moving the data from local to cloud storage, and the data in the cloud already contains everything necessary to restore it into a cluster.
Building a system to safely restore it to multiple clusters simultaneously was a logical next step, so we configured Tiered Storage to choose between serving local or remote data. For RRR, it always uses remote data.
Here’s the best way to use the data you already have in cloud storage: make it available for your consumers, wherever they are, without creating an operational impact on the production cluster.
It’s fast, reliable, and safe — just how we like it.
We did this by adding the configuration for an RRR topic and propagating it to the storage level. When a client creates an RRR topic, it tells the local cluster where to pull the data from, and this information is then sent to all nodes and written to the controller log as part of the topic creation.
When we change the format of data that Redpanda writes to the controller log, we always consider compatibility across upgrades. Redpanda v22.2 supports the older log format, but v22.1 does not support the new format. We proactively prevent compatibility issues through Redpanda’s feature manager, which ensures that no new features are enabled until all nodes are running a version that supports them.
When we explained the architecture for Tiered Storage, we showed that the scheduler_service creates an ntp_archiver for each partition.
In the origin cluster, the ntp_archiver sits in the write path and understands how to communicate with cloud storage to upload log segments and metadata.
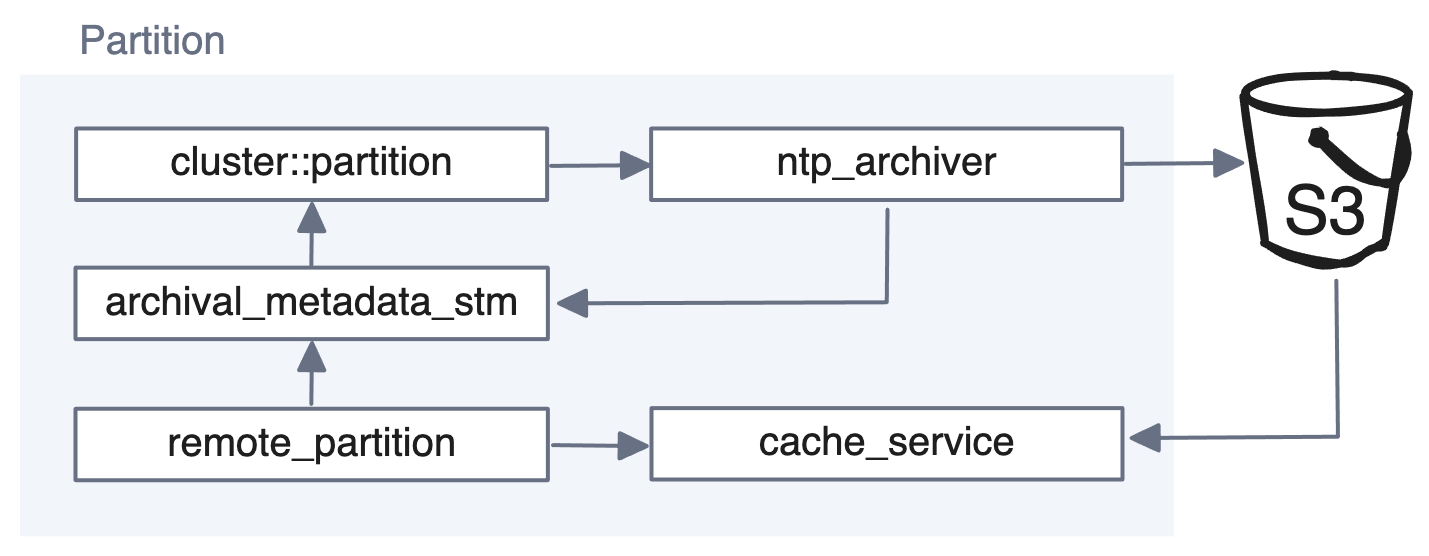
Since it already knows how to talk to the cloud, this was the best place to expand its functionality. We gave ntp_archiver additional powers so it can monitor changes in remote partition manifests, download log segments, and truncate the partition manifest if it detects that event data has been deleted from the object store.
When ntp_archiver in a remote cluster detects that the object store has new log segments, it fetches them and forwards them to archival_metadata_stm, and from there they’re added to the partition.
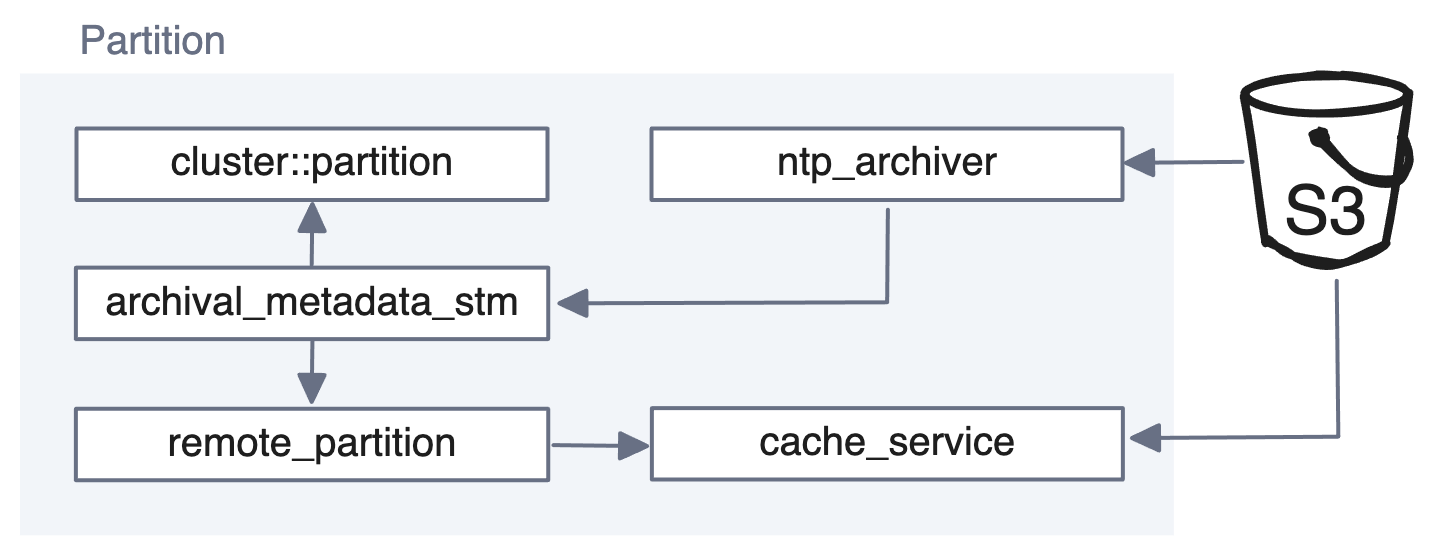
You might be asking, “How does ntp_archiver know whether it should upload data to the cloud or watch the cloud for changes and download the data?”
This logic sits within the scheduler_service, which knows from the partition configuration if it’s part of a read replica.
When an operator sets the redpanda.remote.readreplica flag while creating a topic, the metadata flows all the way from create_request to create_topic_command to topic_properties, is replicated across the cluster, and becomes part of the partition configuration that scheduler_service uses to control the behavior of ntp_archiver.
RRR topics are topics “decorated” with additional metadata, so you must start with a cluster and a topic that will serve as the origin of the data. This origin topic needs to be configured with archival storage, which you can enable in one of the following ways:
cloud_storage_enable_remote_write in the cluster configuration, then all topics will upload data to the cloud.redpanda.remote.write in the topic configuration, then only the topics with this setting will archive data to the cloud.Whichever one you choose, you also have to set the following cluster properties for both the originating and the RRR clusters:
cloud_storage_enabledcloud_storage_regioncloud_storage_bucketcloud_storage_access_keycloud_storage_secret_keycloud_storage_api_endpointFuture releases will also include support for IAM roles and rotating credentials.
Once you’ve set all of these on the origin cluster, topic data will be uploaded to cloud storage and will be ready for consumption by remote clusters.
Because the non-originating cluster reads the topic data and metadata from the same cloud storage bucket where the originating cluster placed it, it should be in the same region as the originating cluster. While there are clouds where object storage buckets can span multiple regions (theoretically allowing the second Redpanda cluster to be in that other region while still reading from the same bucket). Although this is not tested, and not every cloud supports it.
The remote cluster must have cloud_storage_enable set in a cluster configuration file, and you’ll also have to provide information about the cloud provider, topic name, and the necessary credentials to access the storage. Our documentation provides all the necessary information to set this up.
When you create a topic in Redpanda, you also specify the number of partitions the topic will have. Partitions allow you to balance the load when using a consumer group with a topic. Each of the partitions is a separate directory, and because the data is already spread out across these partitions, it’s not possible to change the number of partitions after you’ve created the topic.
Redpanda also needs to know the initial_revision_id of the original topic when it creates topics in the remote cluster, as it uses this value as part of the data directory path to identify partitions.
Every time someone creates or deletes a topic, Redpanda increments revision_id. Segment paths in cloud storage must be stable for Redpanda to read data written in earlier revisions, so the archival storage feature uses initial_revision_id for the path. This is the value of revision_id from when the partition was created.
For Redpanda to locate the RRR's data in the cloud, three parameters must match between the original topic and the read replica: topic name, replication factor, and initial revision ID.
The magic happens when you create an RRR topic in the remote cluster. You only need to configure it to have the same topic name and point to a bucket. Redpanda will then configure the replication factor and initial_revision_id for you based on the information in the cloud.
Creating an RRR topic is almost identical to creating a normal topic, except you add a configuration that tells Redpanda which bucket has the archived data.
rpk topic create <topic name> -c redpanda.remote.readreplica={bucket name}
NOTE: The topic name in the remote cluster must match the topic name in the origin cluster.
Redpanda will begin to pull from cloud storage to populate the topic data, and all of your consumers can read from the remote cluster as if they were reading from the origin cluster.
The best part? You don’t need to change anything in your code for this to work.
Back when muscle cars were in vogue, giving an engine more fuel wasn’t enough to make a car go faster. Combustion engines burn fuel with air, and feeding the engine more air (and giving it more room to exhaust the gasses) makes it more powerful and more efficient. Fuel is important, but air is even more important.
Cloud computing works in a similar way. You can spend more money (fuel) on bigger systems (engines), or you can spend less money on smaller, optimized systems and use software (air) that makes them more efficient.
The Remote Read Replicas feature in v22.2 is just one of the ways that Redpanda helps you do more with fewer resources. Features like this open the door for new ways to process data, like using remote clusters for offline training of machine learning models, building an edge streaming CDN, or doing software development with real data from a MinIO cluster in your office.
We’re always exploring ways to expand this feature for our customers, and we’d love to hear how you want to use it. The best way to tell us is by joining the discussion on GitHub in the Redpanda repository. Or hop into our Redpanda Community on Slack.
Boxes and arrows for people who move billions of events a day. No per-row invoice required.

Solving a Kafka problem to balance batching efficiency against latency and cost
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.
