




Adaptive write request scheduling in Redpanda's Cloud Topics
Solving a Kafka problem to balance batching efficiency against latency and cost
Join our quest for a radically simpler architecture for data processing—powered by Wasm.









Today, we’re thrilled to announce the availability of the Redpanda Data Transforms Sandbox, powered by WebAssembly (Wasm)!
The introduction of Data Transforms marks a paradigm shift in how you use Redpanda—from the infrastructure for blazing fast and cost-efficient data streaming, to an integrated platform that also runs common data processing tasks for end-to-end streaming pipelines. So, naturally, we’re proud to share this preview of the tech and welcome you—our developer community—to help us shape the future of this capability.
In this post, we’ll share some of the thinking behind it, what’s in the new developer sandbox, and how you can get involved.
The Data Transforms Sandbox marks an important milestone in a significant R&D effort by Redpanda, in collaboration with the Wasm community. We’ve been following the Wasm ecosystem closely for years and have explored various approaches to integrating Wasm engines as the tools and developer communities surrounding various implementations have matured.
Our primary goal is to get the developer experience right. That means partnering with users like you for detailed feedback on the feel of the API, development lifecycle, language support, SDK packaging, modular reuse of compiled transforms (even across different hardware types), and so on. In short, we want to know how Redpanda Data Transforms, its APIs, and its tooling can evolve to help you build richer, more valuable streaming data pipelines.
This approach will help us create clean and stable APIs early, to support long-term use of (forwards compatible) data transforms in production, and help us prioritize how we expand the envelope of what’s possible with transforms, delivering the most value with the best developer experience.
A little more on the “why” of what we’re doing with Data Transforms.
Low-cost data streaming enables you to capture and store more event data than ever before, creating competitive pressures to extract more value from that data, and in more places. This creates a natural systems integration challenge along with it, because in a world with more devices generating data streams (producers) and more disparate and legacy systems, tapping into these event streams (consumers), the raw data is often not in shape for downstream consumers to readily accept.
This forces too many streaming pipelines to send event data across the network over to a separate infrastructure (a cluster of stream processors or just a Python job somewhere) to do the dirty work of prepping that data for consumers, only for it to come right back into the broker for delivery.
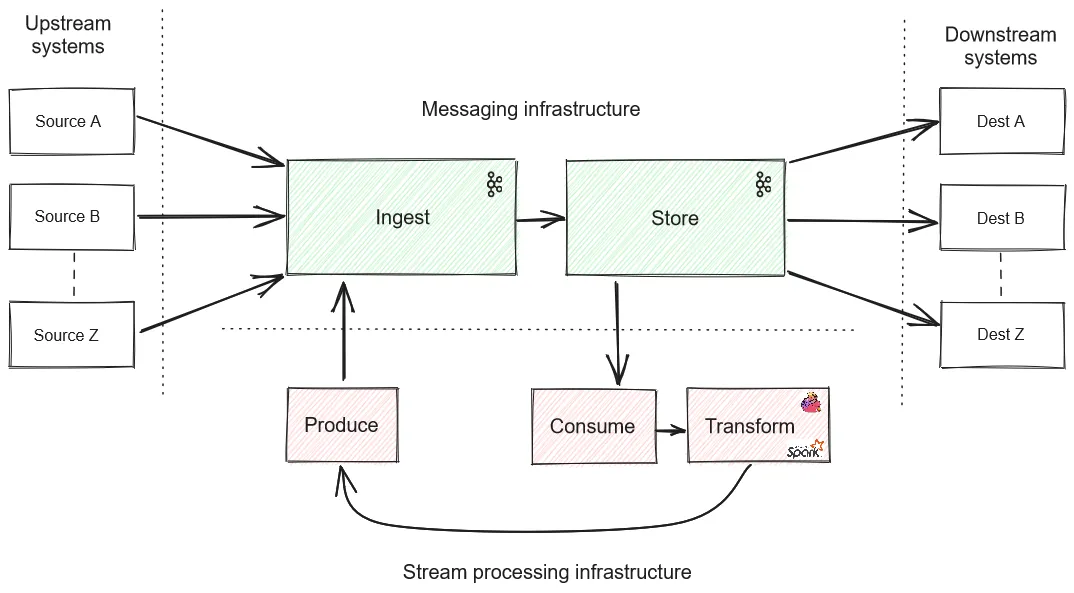
Simple tasks like cleansing, scrubbing, filtering, and transcoding should be simple, yet we stand up, learn, and deploy whole new technologies to do them. Furthermore, we incur serious performance and cost penalties for doing so, not to mention all the associated context switching, cross-team coordination, waiting for the software development life cycle (SDLC), and deployment friction associated with adding a separate infrastructure technology to the mix.
These sophisticated stream processing technologies also consume lots of hardware resources, and may even be overqualified for the job. Especially for the simplest of operations, this makes no sense for the developers, the admins, the end consumers waiting for good data, or the folks writing checks for infrastructure software.
Instead, we propose a much simpler architecture that follows an 80/20 rule of data pipelines, with a radically more efficient approach to doing it. That is, to bring many simple processing tasks in-broker, allow streaming engineers to deliver 80%+ of their data processing tasks without any “data ping-pong,” and do it all within a single platform—with Redpanda’s trademark simplicity, performance, and reliability.
The result should be data that's correct, complete, clean, and consumer-appropriate while relieving the data preparation burden from downstream applications, many of which do not have the flexibility to adapt themselves to invalid data or new data formats.
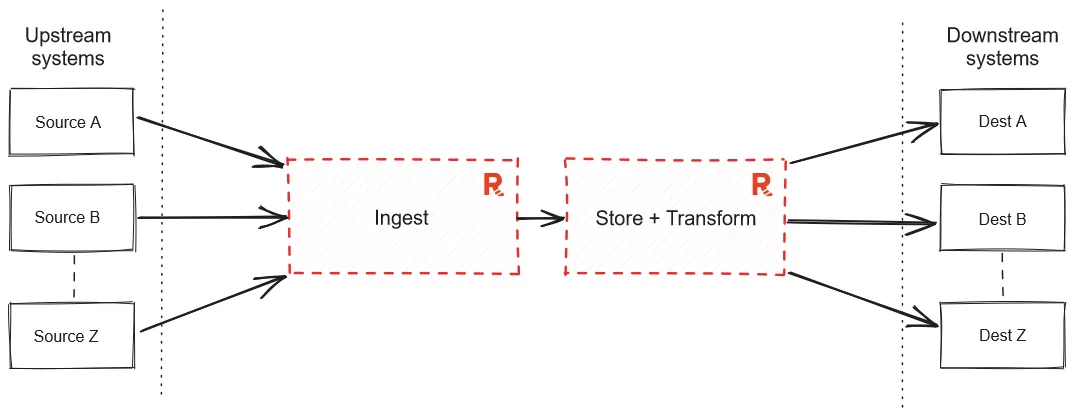
That said, we also need to be pragmatic about the best use cases for Redpanda Data Transforms as it exists today, within a coherent UX, and a reliable and performant operator experience. We don’t claim to want to do everything with Data Transforms, like multi-way joins or iterative ML algorithms running in our message brokers—whose primary job is low latency delivery.
Okay, so what’s in the box? The Data Transforms Sandbox is just that, a sandbox. It’s not intended for production deployments yet, but rather for exploring Data Transforms and mocking up (and dreaming up) the pipelines you’ll want to deploy when we integrate transforms into the upcoming releases of Redpanda Platform (and ultimately Redpanda Cloud).
The sandbox contains a Go-based SDK seamlessly integrated within rpk, our CLI experience, and a single Redpanda broker (Docker container) that can deploy and run your transform functions on topics you create inside the fully-contained sandbox. You’ll also find tutorials and example functions there to get you up and running with your first transform in under a minute. Using Init/build/deploy, it only takes three steps! And, of course, we have comprehensive API documentation and our trusty Redpanda Community on Slack in case you get stuck.
[CTA_MODULE]
We’ll be adding more function types, more language support, and other features over time to help you build more complex functions, seamlessly interact with different data formats, and produce richer and more valuable data products within a familiar and GitOps-friendly toolchain.
If the first act for messaging infrastructure (what we used to call ‘M-O-M’) was decoupling disparate systems for transaction processing, and the second act was turning data streams into the lifeblood of the world’s critical real-time applications, the inclusion of inline transformations powered by Wasm marks the third act.
In this third act, we now have the computing power to “shift left” many data preparation tasks directly into real-time data streams — streams that were previously just raw sources for downstream data engineering workloads — and still deliver curated data products to both operational and analytical applications in milliseconds (as fast as data arrives).
At Redpanda, we believe Data Transforms will sharpen your ability to react to events, shorten the engineering cycle for creating new and valuable data products, and empower your organization to move faster and be more responsive than ever.
So, we’re inviting you to try the developer sandbox and tell us what you think in our Redpanda Community on Slack. If you’re looking for a more technical deep dive into both Wasm and Redpanda Data Transforms, check out the replay of our recent Linux Foundation Webinar.
Happy streaming!
Solving a Kafka problem to balance batching efficiency against latency and cost

Now deployable on Amazon Web Services (AWS)

A case study in keeping Redpanda topic names from drifting with contracts
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.