





Agentic AI needs governance it can't ignore
Everyone is building agents. The Out-of-Band Policy Engine (OBPE) is how you govern them
.png)
What happened, how we handled it, and what we learned during the global GCP outage on June 12th








Redpanda Cloud clusters in GCP remained stable during the outage due to their design for the SLA offered and a cell-based architecture. This architecture reduces the impact radius of failures and improves security, making it a product principle for Redpanda.
Redpanda Cloud's resilience during the GCP outage was due to its cell-based architecture, which co-locates all services needed to write and read data, manage topics, ACLs, and other Kafka entities, and its design for the SLA offered. Other factors include enforcing a replication factor of at least 3 on all topics, storing primary data on local NVMe disks, having redundant services, and continuously chaos-testing and load-testing Redpanda Cloud tiers' configurations.
Safety and reliability measures for modern computer systems include closing feedback control loops, phasing change rollouts, shedding load, applying backpressure, randomizing retries, and defining incident response processes. These measures help manage the non-linear nature of complex systems, where changes in output are not proportional to changes in input.
On June 12th, 2025, Google Cloud Platform (GCP) experienced a global outage due to an automated quota update to their API management system. This outage affected many critical services and companies, some of which are known for their impressive engineering culture and long-standing availability record.
After launching Redpanda Cloud, it took two years to offer a 99.99% availability SLA. The Multi-AZ Redpanda Cloud clusters in GCP were designed to support an availability SLO of at least 99.999%. In practice, even higher measurements are observed.
On Jun 12th, 2025, Google Cloud Platform (GCP) experienced an unfortunate global outage triggered by an automated quota update to their API management system.
What was a major outage for a large part of the internet was just another normal day for Redpanda Cloud customers. While GCP dealt with the widespread disruption that impacted many critical services, Redpanda Cloud clusters in GCP remained stable, thanks to being purposely designed for the SLA we offer, along with a cell-based architecture that we also made a product principle. But behind the scenes, it was far from quiet.
This post provides a brief timeline of events from our own experience, our response, previously untold details about Redpanda Cloud, and closing thoughts on safety and reliability practices in our industry.
Modern computer systems are complex systems — and complex systems are characterized by their non-linear nature, which means that observed changes in an output are not proportional to the change in the input. This concept is also known in chaos theory as the butterfly effect, or in systems thinking, with the expression, “The whole is greater than the sum of its parts”.
When this mathematical fact is acknowledged, safety and reliabiilty measures are put in place, such as closing feedback control loops, phasing change rollouts, shedding load, applying backpressure, randomizing retries, and defining incident response processes, among others.
GCP’s seemingly innocuous automated quota update triggered a butterfly effect that no human could have predicted, affecting several companies — some known for their impressive engineering culture and considered internet pillars for their long-standing availability record.
Our Google Cloud Technical Account Manager (TAM) notified us about the outage:
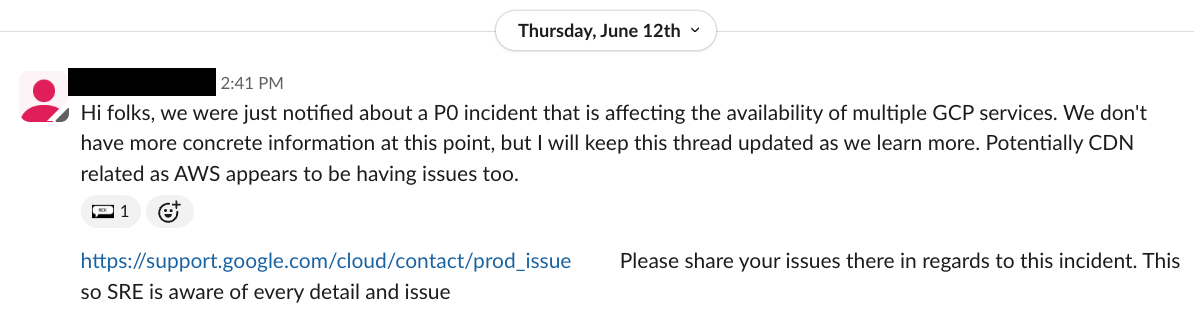
We began to assess the impact on our Redpanda Cloud GCP customers, including whether we had received any support tickets.
We noticed our monitoring was running in a degraded state. Despite self-hosting our observability data and stack, we still use a third-party provider for dashboarding and alerting needs. This provider was partially affected. We could still monitor metrics, but we were not getting alert notifications.
We deemed the loss of alert notifications not critical since we were still able to assess the impact through other means, such as querying our self-managed metrics and logging stack.
At this point, it was clear that multiple GCP services were experiencing a global outage, despite not having received support tickets from our customers or being paged by Redpanda Cloud alerts. So, in preparation for the worst, we preemptively created a low-severity incident to coordinate the response to multiple potential incidents.
We were notified by the vendor we use for managing cloud marketplaces that they were having issues. They were affected by the Cloudflare outage, which we later learned was connected to the GCP outage. Having this service degraded was not critical to us, so we put it on the waiting list.
Google identified the triggering cause and applied mitigations. At this point, there was no evidence that Redpanda Cloud customers were being negatively impacted.

We began receiving delayed alert notifications, mostly related to an increase in tiered storage errors, which is not Redpanda’s primary storage. We didn’t get high disk utilization alerts, which we typically receive when the tiered storage subsystem has been experiencing issues for an extended period (days).
Additionally, as a reliability measure, we leave disk space unused and used-but-reclaimable (for caching), which we can reclaim if the situation warrants it. This outage was not that situation.
We proactively started reaching out to customers with the highest tiered storage error rates to ensure we were not missing anything, and also to show our support, as is customary. We fully manage these BYOC clusters on behalf of our customers and have complete visibility — we know the answers to the questions, but we ask anyway. These are complex systems, after all.
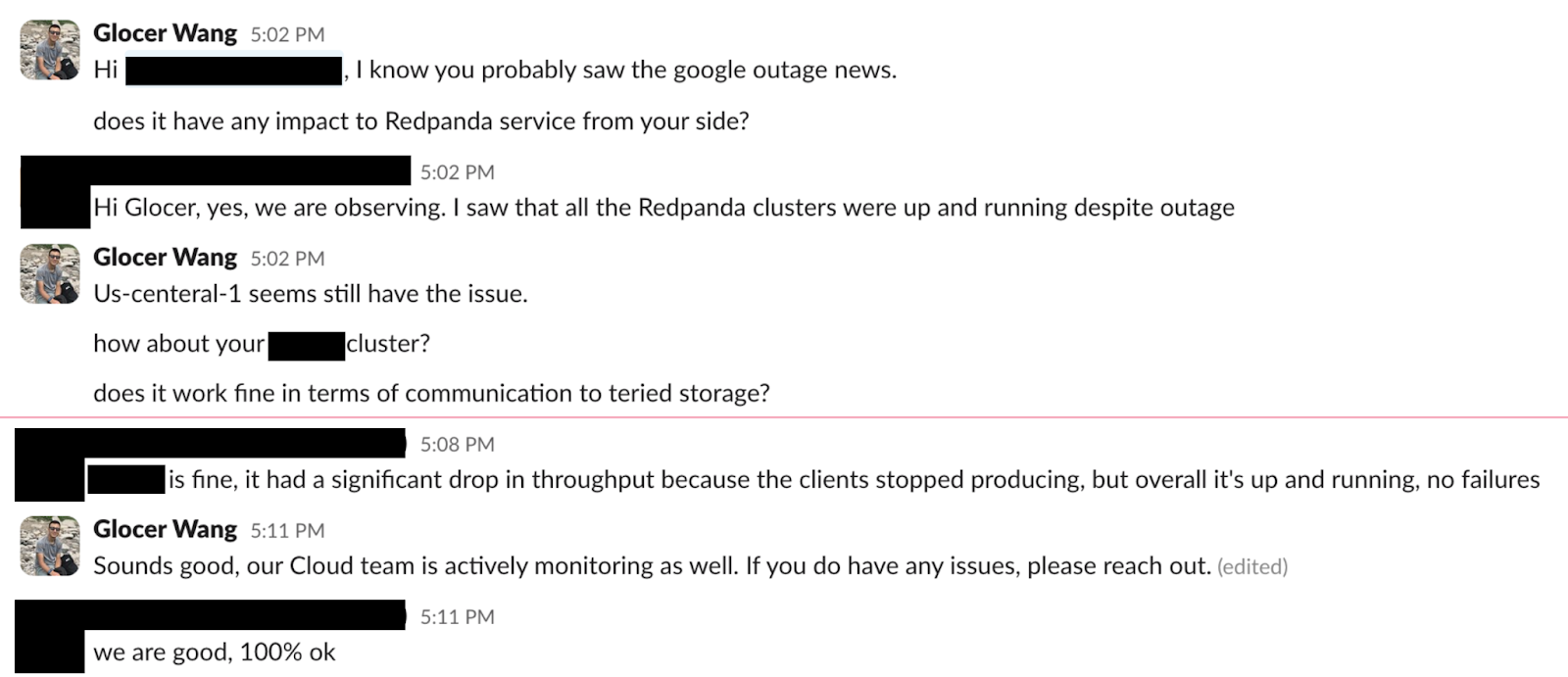
After closely monitoring our GCP data streaming fleet for some time, we considered the incident mitigated—with the severity unchanged (SEV4), and no evidence of negative customer impact. We noticed an increase in error rate for API calls against GCS, with minimal latency impact in some cases. However, hundreds of GCP clusters were up and healthy.
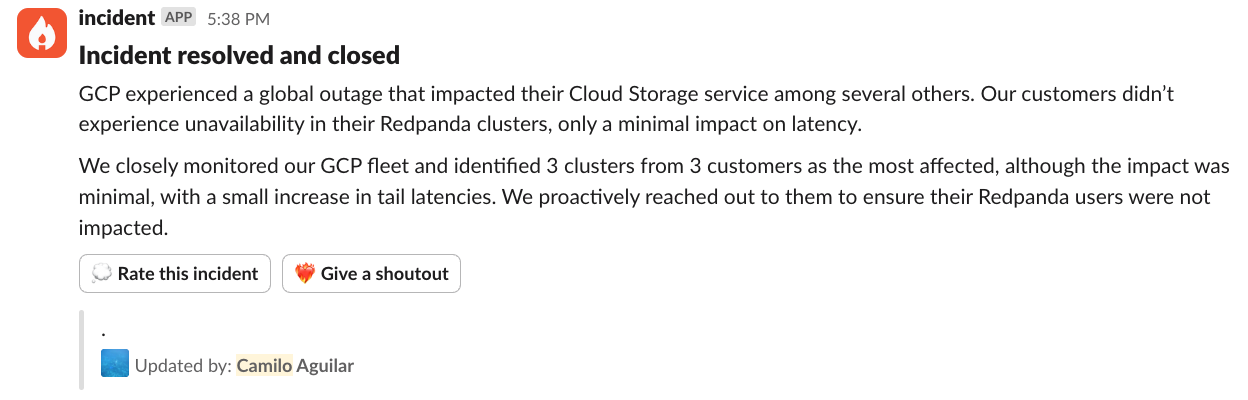
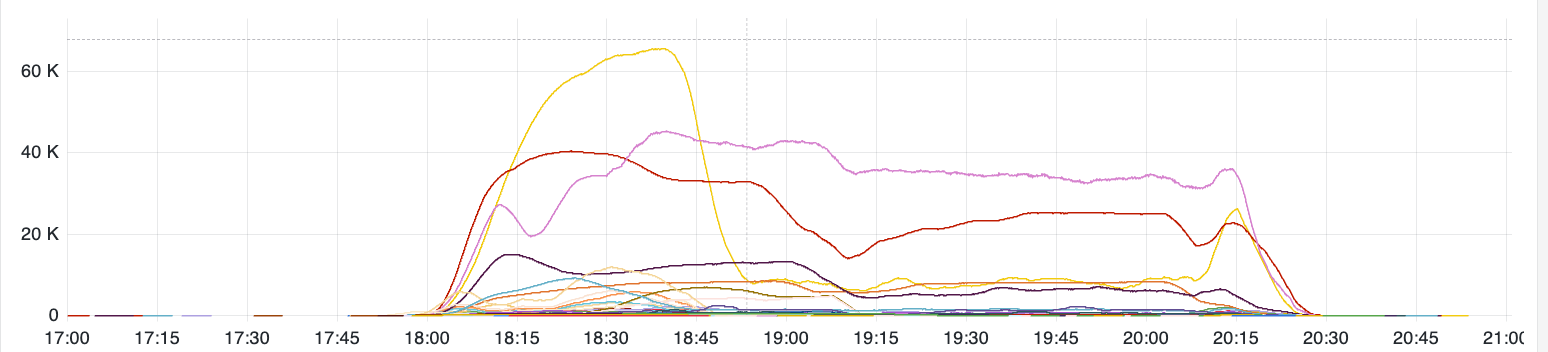
Acknowledging the risk of hindsight bias, the following factors contributed to the GCP outage having no negative impact on our Redpanda Cloud GCP customers.
Redpanda Cloud clusters do not externalize their metadata or any other critical services. All the services needed to write and read data, manage topics, ACLs, and other Kafka entities are co-located, with Redpanda core leading the way with its single-binary architecture. This follows a well-known architectural pattern aimed at reducing the impact radius of failures, which also improves security.
We have taken this pattern further and made it a product principle. In contrast, other products boasting centralized metadata and a diskless architecture likely experienced the full weight of this global outage.
After launching Redpanda Cloud, it took us two years to offer a 99.99% availability SLA. Responsibly offering 1 extra 9 of SLA takes a significant amount of investment and effort. Multi-AZ Redpanda Cloud clusters in GCP were designed to support an availability SLO of at least 99.999%. In practice, we observe even higher measurements.
This is possible thanks to multiple factors:
* Except when Private Service Connect (PSC) is enabled, in this case, the PSC becomes part of the critical path for reading and writing data to Redpanda.
For cloud services such as Redpanda Cloud, which operates across the three major cloud providers and has numerous engineers continuously modifying the system, it is challenging to emerge unharmed from a global outage like this without some degree of fortune – although we learned later that one cluster was badly affected, keep on reading for the details.
Understandably, GCP customers were experiencing significant internal chaos and struggling to assess the full impact when we reached out. For some of them, GCP's Pub/Sub served as the data source for their Redpanda BYOC clusters, so they needed to recover that first. While this meant Redpanda's operational status was less critical in those cases, it was still one less element for them to worry about.
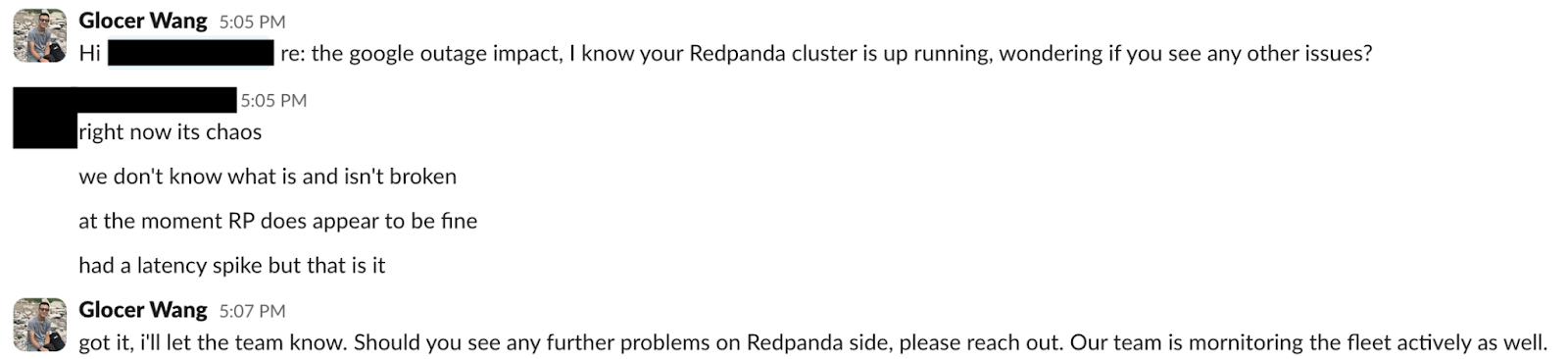
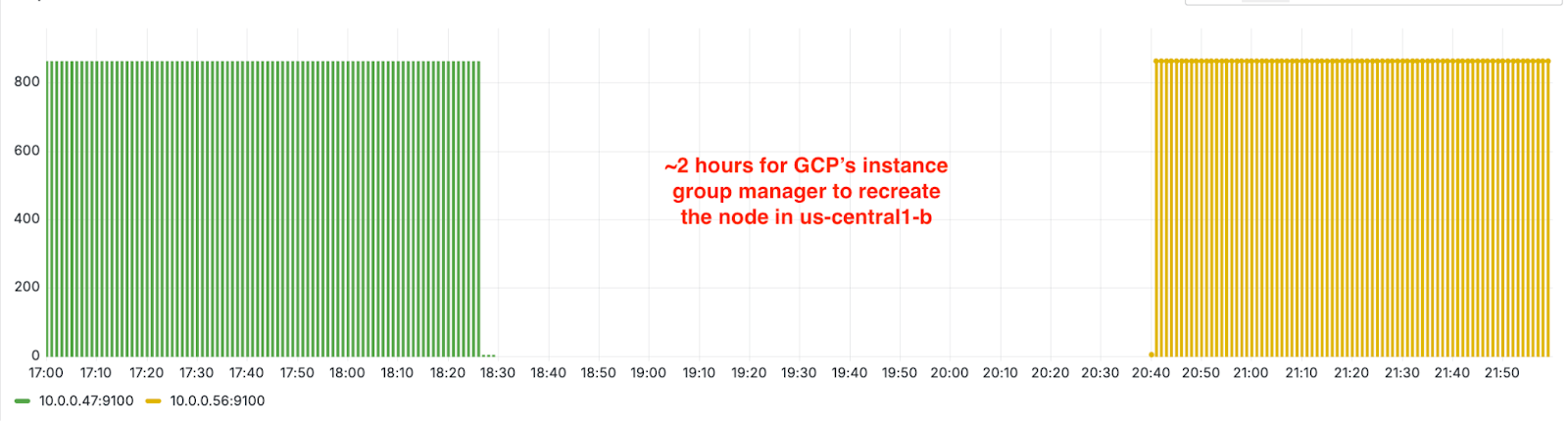
As I was wrapping up this post, another incident had unfolded and was being mitigated. During its incident analysis, we found evidence that the GCP outage was a contributing factor in losing one node and having no replacement coming back. However, this event was isolated to us-central-1 and an uncommon interaction between internal infrastructure components of the cluster.
Out of hundreds of clusters, we were lucky that only one cluster was affected. It took GCP around two hours to launch the replacement node, roughly the duration of the outage in us-central-1, the region in which this cluster was located. Fortunately for the customer, the affected cluster was not a production but a staging cluster. Their production Redpanda cluster was unaffected.

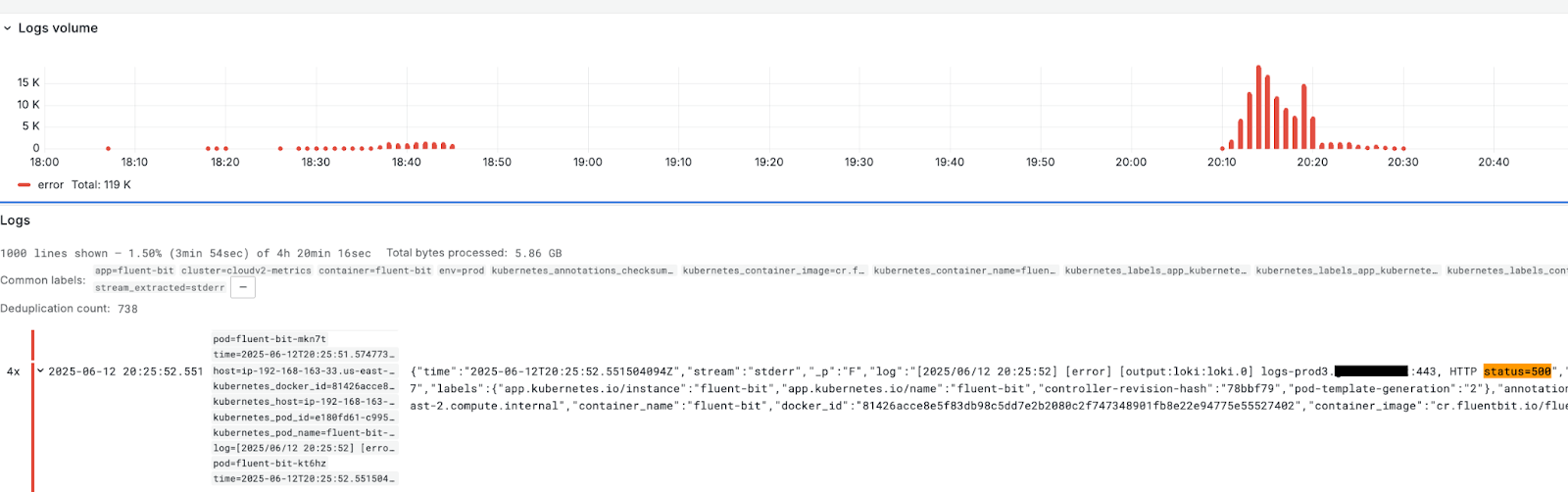
We moved to a self-managed observability stack last year, primarily due to increased scale and cost, and were only using a third-party service for dashboarding and alerting needs. Had we kept our entire observability stack on that service, we would have lost all our fleet-wide log searching capabilities, forcing us to fail over to another vendor with exponentially bigger cost ramifications given our scale.
In other words, this graph would have been filled with many more red bars and tears:
As an industry, it seems we keep having to relearn hard lessons from the past. Not too long ago, we were all in awe at the global Crowdstrike outage, where similar controls were missing to enable safer global rollouts, affecting millions of Windows computers, and resulting in hundreds of millions of dollars in damages to their customers.
With the resurgence of AI, systems will inevitably get even more complex. So, it seems valuable and timely to reconsider our current mindset, and I cannot think of anything better than a systems thinking mindset, especially when engineering our socio-technical systems, which should also result in increased adoption of control theory in our change management tools.
Time will tell, perhaps all the above will be left to AI agents to control, perhaps not, for the foreseeable future, it seems we have no AI replacement, so we better hone our systems thinking skills.
In the meantime, you can get started with Redpanda Cloud for free or get in touch for a demo. For any other questions, drop us a note in Slack.
Everyone is building agents. The Out-of-Band Policy Engine (OBPE) is how you govern them

You can't scale what you can't trust. A governance layer fixes that.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.