




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Learn how to integrate Delta Lake with Redpanda using Spark Streaming in a data-compliant eCommerce use case scenario.









Delta Lake tables can help meet compliance needs as they store full table history, including deleted records. This feature is particularly useful for compliance regulations that require you to keep track of deleted data.
You can load data into Delta Lake tables from a Redpanda topic using Spark Structured Streaming. The Delta Lake transaction log guarantees exactly-once processing, even when other streams or batch queries are running concurrently against the table. By default, streams run in append mode, adding new records to the table.
Dealing with continuous data streams can be challenging due to the continual volume, velocity, and veracity of the incoming data. These challenges require a sophisticated data streaming and storage infrastructure to meet business requirements, especially when dealing with personally identifiable information (PII) and meeting regulatory compliance requirements like GDPR.
To build an eCommerce clickstream app using Redpanda and Delta Lake, you need the following: the code from the GitHub repository, Redpanda downloaded and set up in your environment, Python version >= 3.7, and Delta Lake 1.2.1. If you're using PySpark, it requires Java version 7 or later.
Stringent privacy and compliance regulations like GDPR have forced developers to rethink how they build apps that store and access personal information. For instance, if your application deals with personally identifiable information (PII) such as user IPs, auditing activity is a must-have requirement to meet many regulatory compliance requirements.
In dealing with continuous data streams, these actions can be challenging due to the continual volume, velocity, and veracity of the incoming data, requiring sophisticated data streaming and storage infrastructure to meet these business requirements.
Redpanda is an Apache KafkaⓇ API-compatible, ZookeeperⓇ-free, JVM-free, and source-available streaming data platform for developers, purpose-built to deliver speed, accuracy, and safety for streaming data. It can be combined with an open format storage layer like Delta Lake to remove malformed data during ingestion, audit and purge relevant data for compliance, and track changes in streaming and batch processing scenarios.
In this post, we will show you how Delta Lake and Redpanda can be used to improve the compliance of an eCommerce app that streams in clickstream user data.
Imagine that you’re building an eCommerce store app that needs to ensure great user conversion rates and optimize the user experience. One way to accomplish this is to continually analyze users' clickstream data, which are a sequence of streaming user actions on a website or mobile app. Often, an in-browser JavaScript-based tracker is used to track user actions (including searches, impressions, and purchases), and the captured data is sent to a server for analytics to drive other systems such as recommendation engines and market basket analytics.
In this tutorial, we’re using a sample eCommerce clickstream app to stream data with Redpanda and store it into Delta Lake after it is processed using Apache SparkⓇ. By combining Redpanda, Delta Lake, and Spark in our stack, we can easily manage continuous streams of eCommerce clickstream data and audit the data in Delta Lake tables to meet the compliance requirements.
Here is the high-level architectural diagram of your application:

Now, let us look at the prerequisites to get started.
You can find the code to build the eCommerce clickstream app in this GitHub repository. Please go through the README instructions to get the code up and running in your environment.
Redpanda can be downloaded here. Redpanda currently supports Docker, macOS, and Linux environments. In this document, we will be running in a Ubuntu 20.02 environment.
Note: If you are running in a macOS/Docker environment, please note down the IP addresses of the brokers, which you can find after the installation. It will be similar to the image below.
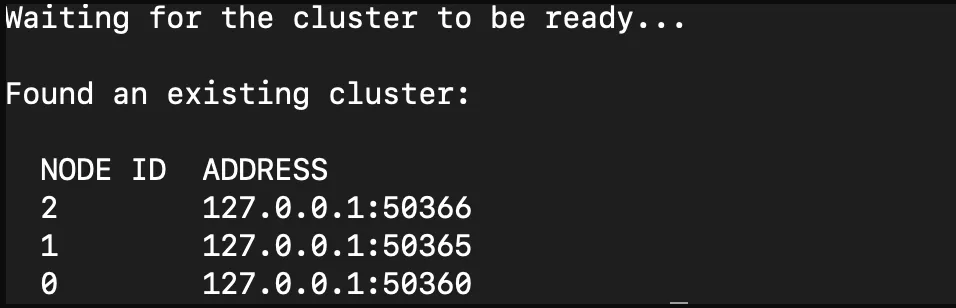
We will use PySpark and associated Kafka libraries to create structured streams of data written to Delta Lake. For this, you’ll need python versions >= 3.8. You can download Python 3.8 here.
The clickstream data will be stored in a Delta Lake table. This tutorial uses version 1.2.1 of Delta Lake. You can read more about getting started with Delta Lake here.
To create a structured data stream that will be stored in a Delta Lake table, we will use PySpark. PySpark requires Java version 7 or later. To set up Java in an Ubuntu 20.04 environment, click here.
Let us now proceed to build the eCommerce app.
The schema we are using is modeled after a fictitious eCommerce clickstream application. In Redpanda, data is read from multiple sources and organized into topics. In this example, our topic is called ecommerce_click_data, which models various clickstream events generated by users on an eCommerce app. The full topic schema consists of the following fields:

The producer logic for our application can be found in the redpanda_producer.py file. Running the producer code will accomplish the following:
ecommerce_click_data topicecommerce_click_data topicOnce the script runs successfully, you should see messages produced on the topics.

You can also check the output of the individual producers using Redpanda’s CLI tool, rpk. Run the following command:
rpk topic consume ecommerce_click_data
Note: If you are running Redpanda in a MacOS/Docker environment, you will need to tweak the command by adding the--brokersflag. So the new command would be:rpk topic consume ecommerce_click_data --brokers <IP:PORT>
You will see the output below. The data inserted by the script will be under the value field of each message.
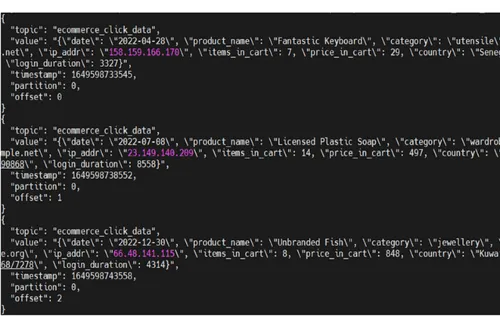
While the producer streams data into a Redpanda topic, you can write data into a Delta table using Spark Structured Streaming. The Delta Lake transaction log guarantees exactly-once processing, even when other streams or batch queries are running concurrently against the table. By default, streams run in append mode, adding new records to the table.
For this, we will use the load_data.py script from our GitHub demo repo.
Running the load_data python script code will accomplish the following:
Let us look at these steps in a bit more detail.
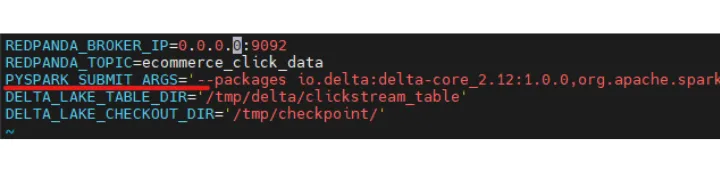
Using PySpark, generate a Spark session with the correct packages and add the corresponding additional Delta Lake dependencies. You can find the packages used in the PYSPARK_SUBMIT_ARGS variable inside the .env file.
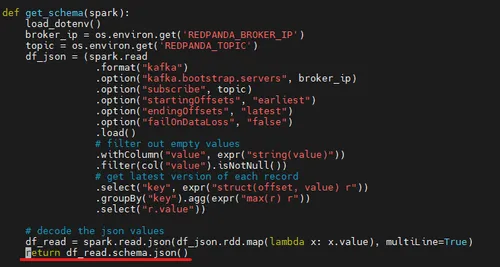
With the Spark session, obtain the schema of the topic. You can find this logic in the get_schema() function inside get_schema_json.py file.
Using the JSON schema, use the capabilities of Spark Structured Streaming. The process is similar to getting the schema; the only difference would be to use readStream. The get_table_df() function found in the get_schema_json.py file responds with a data frame object that contains the clickstream topic data.
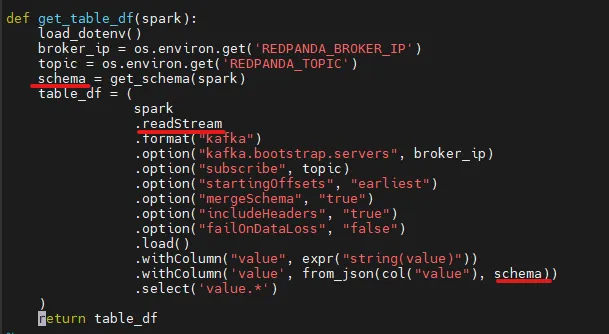
To create the Delta tables, the paths are configurable and can be modified as per your preference by editing the .env file. In addition, Delta Lake automatically generates checkpoint files after every 10 comments. These files save the entire state of the table at the point in time - in native Parquet format that is quick and easy for Spark to read.
By default, in our tutorial, the Delta table and checkpoint file paths are:

The functions used to create the Delta Lake table and append the data from the data frame can be found in the handle_delta_tables.py file.
Note: Before executing the script, please ensure that the folders mentioned in the .env file are empty.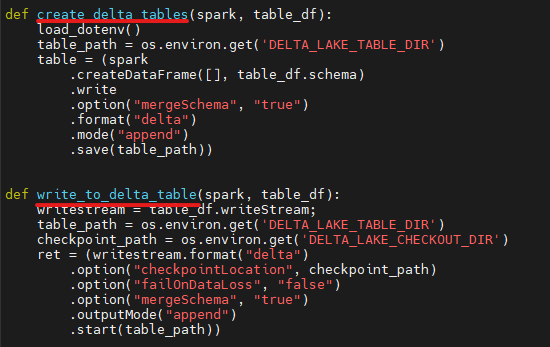
After running the load_data python script, you should see the following output:

To view the data in the Delta Lake table, run the view_data.py script:python view_data.py
The result from Delta Lake should be like the screenshot below.
Note: The values might differ since we are using random stream values in our tutorial.
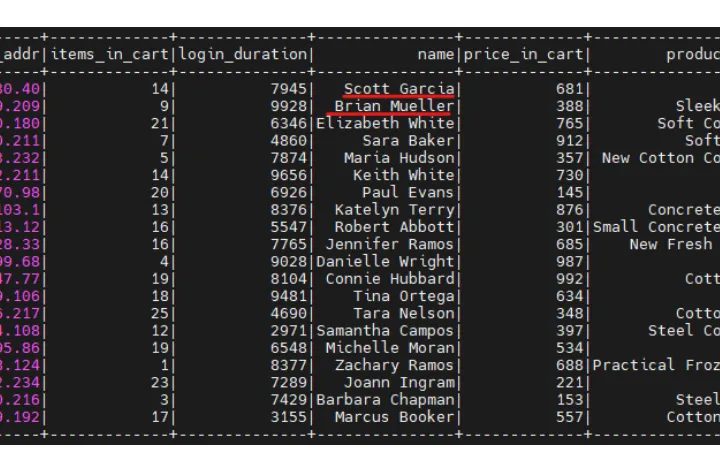
Several compliance regulations require you to keep track of deleted data. Delta Lake tables store full table history, including deleted records, which helps meet compliance needs.
We will use the delete_entry.py python script to delete some named records. The names to be deleted can be specified in the names_to_be_deleted.txt file.
After running the python script, the records corresponding to the names will be deleted. In this example, we have deleted the records corresponding to ‘Scott Garcia’ and ‘Brian Mueller’.
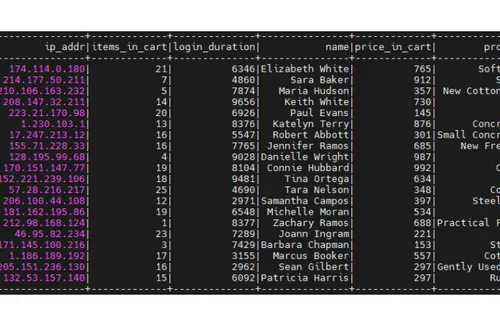
Delta Lake maintains full-history events about any operation done on the Delta table. This includes operations such as deleting a record. You can obtain the full history by running the script full_table_history.py.
The output should be similar to the screenshot below:

Notice that the history captures two delete events and several other streaming updates. This is shown in the operations column of the table.
After each event, the version number of the Delta table is incremented. The version number is shown in the version column of the table. This is useful if the compliance auditor wants you to roll the table data back to a specific version.
Running the restore_to_version.py script will prompt you for a version number and rollback the Delta Lake table to that version number. For example, rolling back to version 25 was able to bring back the rows corresponding to ‘Scott Garcia’ and ‘Brian Mueller’.

Redpanda’s integration with Delta Lake allows you to reliably meet compliance standards like GDPR and CCPA. You can easily access any of the past transactions on your data lake, get support for ACID transactions, and enforce schema validation on data streams.
In addition to data privacy compliance, you can use the combination of Redpanda and Delta Lake for many other use cases like real-time business intelligence on your data to get immediate insights, unifying batch and real-time operations, and much more.
In today's tutorial, we focused on eCommerce clickstream use cases, but the underlying technologies can be used for various other scenarios, including across industrial automation, financial services, and e-commerce industries, to provide faster, more powerful, and cost-effective real-time analytics. As a reminder, you can find the code for this tutorial in this GitHub repo.
Interact with Redpanda’s developers directly in the Redpanda Community on Slack, or contribute to Redpanda’s source-available GitHub repo here. To learn more about everything you can do with Redpanda, check out our documentation here.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

