

Kafka architecture—a deep dive











Kafka architecture
Apache Kafka® is an open-source distributed event streaming platform that many companies use for high-performance data pipelines and streaming analytics. It is often described as a “distributed commit log” — an architecture system designed to provide a durable record of all events so that you can replay them to build a system's state consistently. It supports mission-critical use cases with guaranteed message ordering, zero message loss, and exact-once processing.
This article examines Kafka's architecture, discusses its basic building blocks, and explores the system's design principles.

Summary of key Kafka architecture concepts
Kafka's architecture consists of several key components, each playing a crucial role in its functionality.
Kafka architecture components
Key components in Kafka architecture are given below:
Broker
A single Kafka server is called a broker. The Kafka broker receives messages from producers, assigns offsets, such as Kafka Address to them, and writes them to disk storage. It also services consumers by responding to fetch requests for partitions and responding to published messages. Depending on the specific hardware and other configurations, a single broker can easily handle thousands of partitions and millions of messages per second.
Kafka brokers operate as part of a cluster. Within a cluster of brokers, one broker functions as the cluster controller and is elected automatically from the live members of the cluster. The controller is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures.

Message
A message (also called an event) is a unit of data written to or read from Kafka. Every message in Apache Kafka is a key-value pair. These are serialized to a byte array before being written to disk.
Keys
Keys are used to route messages to the right partition in a topic. Keys are usually strings or integers pointing to a particular system entity, such as a specific user, order, or device. They don’t need to be unique for every message. Keys can also be null—Kafka writes messages with null keys to any randomly available partition.
Values
The message value contains details about the event that happened. This could be as simple as a string or a complete object with many nested properties or just left empty.
By default, messages have a timestamp that records when the message was created. Messages can also optionally have headers, key-value pairs of strings containing metadata, such as where the event originated from or where you want it routed.
Topic
Messages in Apache Kafka are categorized into topics. A topic is simply an ordered sequence of events called an event log. You can store different kinds of events under different topics. For example, a notification topic can store all events wherein an application sends a notification (SMS, email, push notification, etc.).
Multiple applications can write to and read from the same topic. An application might also read messages from one topic, filter or transform the data, and then write the result to another topic. Topics are append-only. Messages in a topic are immutable. Once they're written to a topic, you can't change them. When you write a message to a topic, it's appended to the end of the log.

Unlike messaging queues, reading a message from a topic doesn't delete it. Messages can be read as often as needed by multiple different applications. The data written to topics is durable and retained on the disk for seven days by default. However, this behavior can be configured.
Partition
Topics are additionally divided into partitions. Regarding the “commit log” description, a partition is a single log. Messages are written to it in an append-only fashion and read in order from beginning to end.
When a topic is created, we specify the number of partitions it should have. The partitions are themselves numbered, starting at 0. When a new event is written to a topic, it's appended to one of its partitions.

Adding partitions to a topic helps improve redundancy and scalability. Each partition can be hosted on a different broker, which means that a single topic can be scaled horizontally across multiple servers to provide performance far beyond the ability of a single server. Additionally, partitions can be replicated, so different servers will store a copy of the same partition in case one fails.
Partition offset
Each message in a partition is assigned a monotonically incrementing integer called an offset. Offsets start at 0 and are incremented every time Kafka writes a message to a partition, so each message in a given partition has a unique offset.
If a message has no key, it will be evenly distributed among partitions in a round-robin manner: partition 0, then partition 1, then partition 2, and so on. This way, all partitions get an even share of the data. The key is run through a hashing function, which turns it into an integer. This output is then used to select a partition. Hence, messages with the same key will always be sent to the same partition and in the same order. This means that Kafka architecture guarantees order within a partition but not across partitions.
Offsets are not reused, even when older messages get deleted. They continue incrementally, giving each new message in the partition a unique ID. When data is read from a partition, it is read in order from the lowest existing offset upwards.
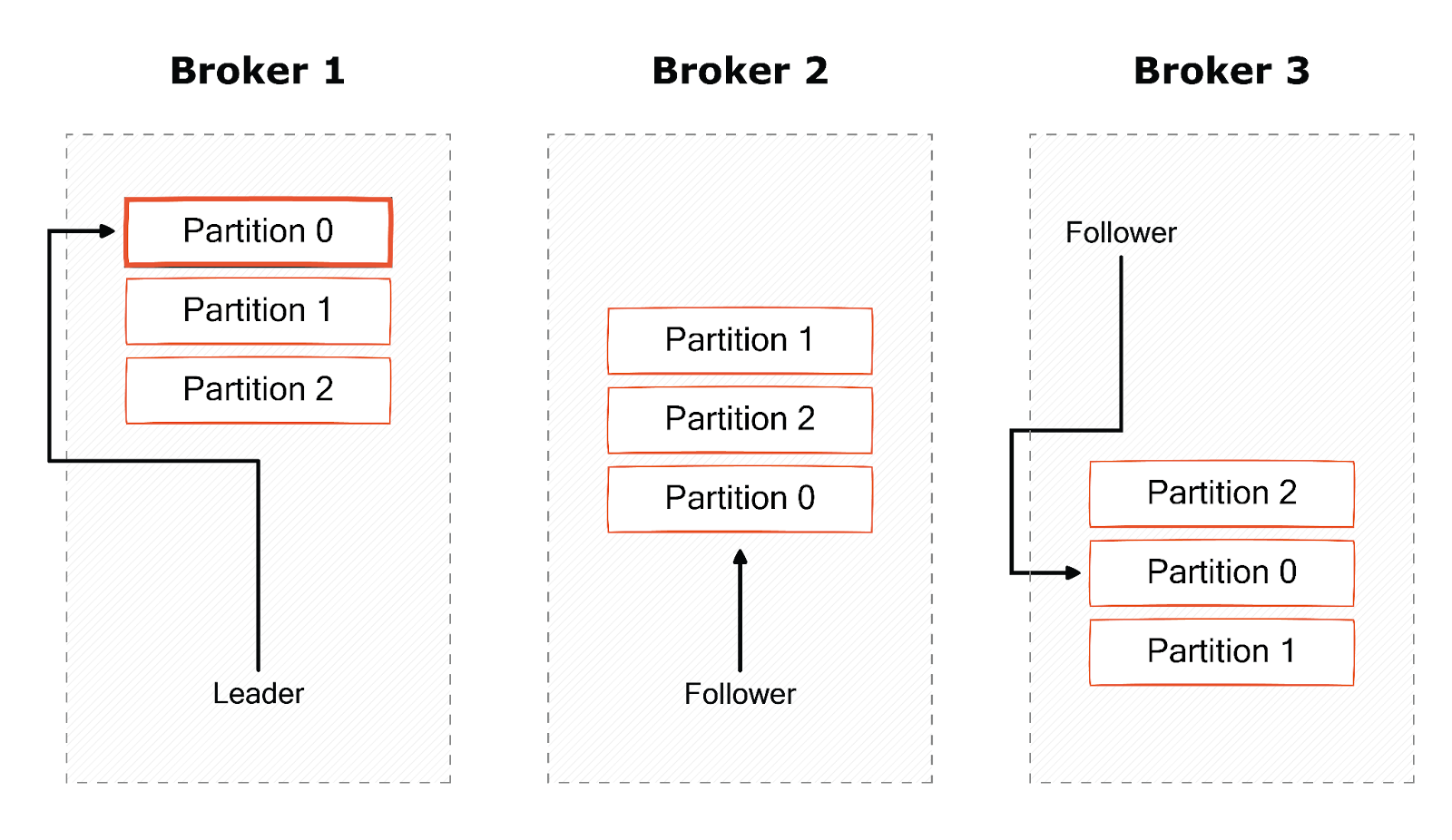
Partition replication—leaders and followers
Kafka topics are essentially “stored” in brokers. A single broker in the cluster owns a single topic partition, and that broker is called the partition leader. Topics can have a replication factor of >1, which determines how many brokers the data of the topic (and, in essence, a partition) is replicated over. A replicated partition is assigned to other brokers, called followers of the partition. Replication provides redundancy of messages in the partition, such that one of the followers can take over leadership if there is a broker failure.
Reading from and writing data to the Kafka architecture
A system that uses Kafka has producers and consumers.
Producers
Producers are client applications that write messages to Kafka topics. They use the Kafka client library to help manage writing messages in Kafka.
Producers take a key-value pair, generate a Kafka message, and then serialize it into binary for transmission across the network. They implement strategies that decide which partition a particular message should be sent to.
Consumers
Consumers are client applications that read messages from topics in a Kafka cluster. Consumers subscribe to one or more topics and read the messages in the order they were produced for each partition. The reading of messages works in a polling fashion, meaning consumers periodically request partitions to send them data at regular intervals.
Messages are read in order within a partition, from the lowest available offset to the highest. But suppose a consumer reads data from several partitions in the same topic. In that case, the message order between these partitions is not guaranteed.
For example, a consumer might read messages from partition 0, then partition 2, then partition 1, then back to partition 0. The messages from partition 0 will be read in order, but there might be messages from the other partitions mixed among them.
A consumer keeps track of which messages it has already consumed by keeping track of the offset of messages. By storing the next possible offset for each partition, a consumer can stop and restart it without losing its place.
When a consumer reads a message, it does not delete it. The message is still available to be read by any other consumer who needs to access it. It's normal for multiple consumers to read from the same topic if they each have uses for the data. By default, when a consumer starts up, it will read from the current offset in a partition.
All producers must connect to the topic leader to publish messages, but consumers may fetch from either the leader or one of the followers.
Consumer groups
The problem with having a single consumer is that as we increase the number of partitions and produce more messages, the consumer starts getting overwhelmed, and processing throughput decreases. To tackle this issue, consumers generally work as part of a group, with one or more consumers working together to consume a topic. In this way, consumers can horizontally scale to consume topics with many partitions. If a single consumer fails, the remaining group members reassign the partitions consumed to take over for the missing member.

The number of partitions in a topic helps decide the maximum number of consumers in a group. So, if there’s a topic with five partitions, you can create up to five instances of the same consumer in a consumer group. If you add a 6th consumer, the extra consumer remains idle.
Upon adding a consumer instance to a consumer group, Kafka automatically redistributes the partitions among the consumers in a rebalancing process. Each partition is only assigned to one consumer in a group, but a consumer can read from multiple partitions. Also, multiple different consumer groups (meaning different applications) can read from the same topic at the same time.
Example
Producers are decoupled from consumers, which read from Kafka. They don't know each other, and their speed doesn't affect each other. Producers aren't concerned if consumers fail; the same is true for consumers.
Let’s look at a simple producer and consumer Java application using the standard Apache Kafka client.
import java.util.Properties;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
public class TestProducer {
public static void main(String[] args) {
// Producer configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create producer
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Define topic and data
String topic = "test-topic";
String data = "Simple string message from the producer!";
// Send message
producer.send(new ProducerRecord<>(topic, data));
// Flush data
producer.flush();
// Close producer
producer.close();
}
}import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class TestConsumer {
public static void main(String[] args) {
// Consumer configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Create consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Subscribe to topic
consumer.subscribe(Arrays.asList("test-topic"));
// Continuously poll for messages
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: key = %s, value = %s\n", record.key(), record.value());
}
}
// Close consumer
consumer.close();
}
}The consumer will be up and running as a daemon application consuming messages from the specified topic.
Schema Registry
Schema Registry provides a centralized repository for managing and validating schemas for topic message data, and for serialization and deserialization of the data over the network. Once registered, the architecture of the schema can be shared and reused across different systems and applications. When an application sends data to a message broker, the schema for the data is included in the message header. The Schema Registry ensures that the schema is valid and compatible with the expected schema for the topic. It provides the following services:
- Allows producers and consumers to communicate over a well-defined data contract in the form of a schema
- Controls schema evolution with clear and explicit compatibility rules
- Optimizes the payload over the wire by passing a schema ID instead of an entire schema definition

Zookeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Initially, Kafka was using Zookeeper to manage the brokers in a cluster. Zookeeper kept track of things like:
- Which brokers are part of a Kafka cluster
- Which broker is the leader for a given partition
- How topics and records are configured, such as the number of partitions and the location of replicas Consumer groups and their members
- Access Control Lists – who is allowed to write to and read from each topic
Recently, a proposal has been accepted to remove Zookeeper and have Kafka manage itself (Controllers: KIP-500), but this is not yet widely used in production.
Security in Kafka architecture
Apache Kafka comes bundled with a Simple Authentication and Security Layer (SASL) framework that provides authentication and security services. This allows brokers to authenticate clients (producers, consumers, and other Kafka components) before allowing them to access the Kafka cluster. It ensures that only authorized users or applications can interact with Kafka. SASL enables secure communication between Kafka brokers and clients by providing mechanisms for encryption and data integrity.
Kafka also provides the ability to exercise granular control over access to objects and operations within the cluster through the use of Kafka Access Control Lists (ACLs) and several interfaces (command line, API, etc.). ACLs combine with the security layer to ensure that only authorized parties have the privileges and permissions required to access particular data or carry out particular operations.
ACLs are useful in several scenarios, such as:
- Allow only certain users or client applications to produce or consume messages from specific topics.
- Prevent unauthorized users or client applications from creating or deleting new topics.
- Ensure that only certain users or client applications can view the list of topics or consumer groups in the Kafka cluster.
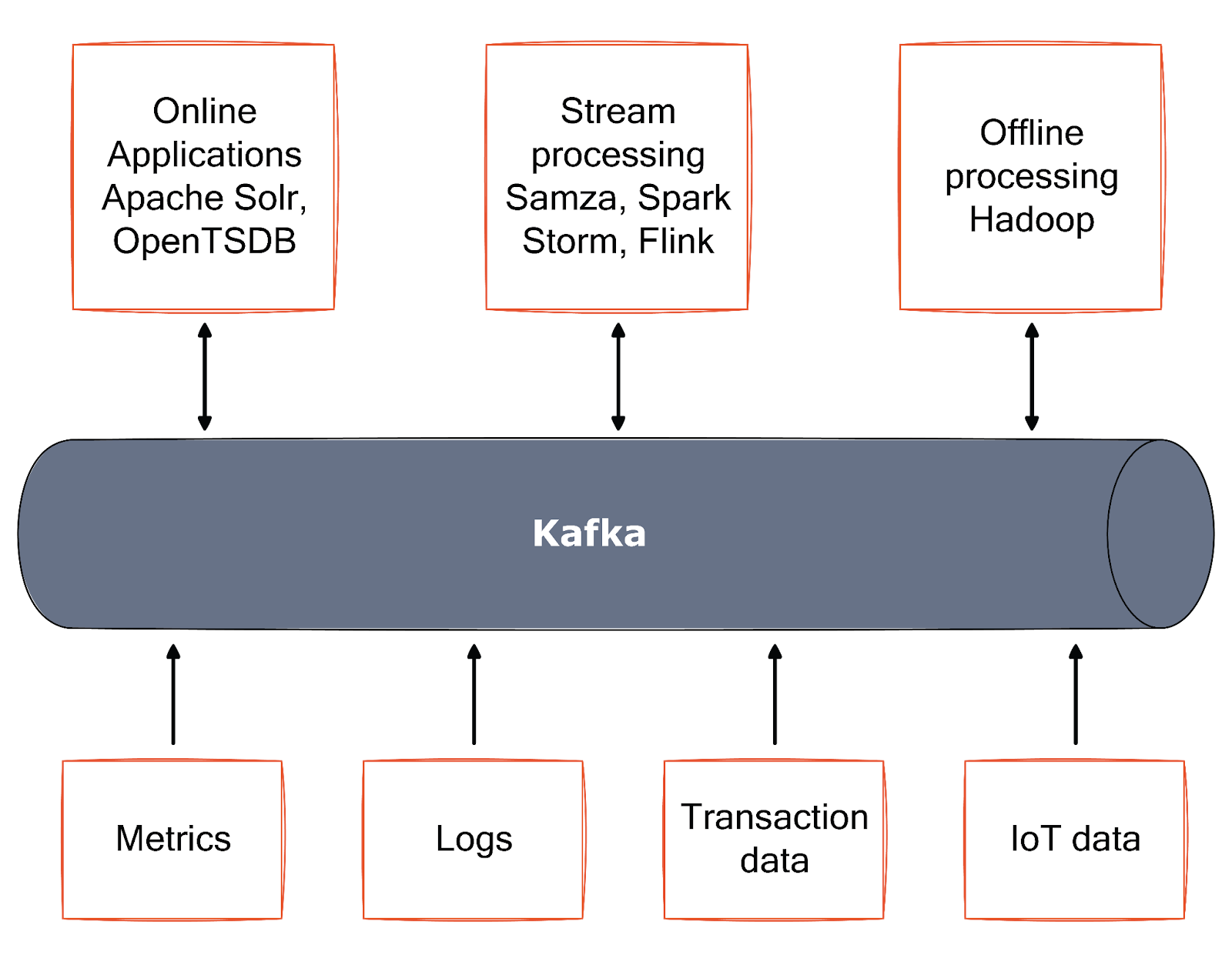
Kafka in the real world
Kafka has undeniably brought about a change in the way we build tech and data systems. Apache Kafka, in a way, provides the circulatory system for the data ecosystem. It carries messages between the various members of the infrastructure, providing a consistent interface for all.
Use cases
Let us take a quick look at some of the use cases of Kafka in the industry:
User activity tracking
Site activity (page views, searches, or other actions users may take) can be published to central topics with one topic per activity type. These feeds are subscription-based for various use cases, including real-time processing, monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Log aggregation
Kafka provides a cleaner abstraction of log or event data as a stream of messages. Compared to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
Metrics collection
Kafka is often used to monitor operational data. This involves aggregating statistics from distributed applications to produce centralized operational data feeds.
Commit log
Since Kafka is based on the concept of a commit log, database changes can be published to Kafka. The log helps replicate data between nodes and is a re-syncing mechanism for failed nodes to restore their data.
Stream processing
Stream processing means operating on data in real time as quickly as messages are produced. Stream frameworks allow users to write small applications to operate on Kafka messages, performing tasks such as counting metrics, partitioning messages for efficient processing by other applications, or transforming messages using data from multiple sources. In addition, Apache Kafka itself has Streams API to enable the building of real-time applications and microservices.
Final thoughts
Kafka architecture is distributed, fault-tolerant, and scalable. Users can handle large data volumes while ensuring reliability and performance. However, due to its open-source nature, Apache Kafka is complex and challenging for developers to work with. It has a steep learning curve and can take a long time to configure and run to meet project requirements.
Redpanda is a source-available (BSL), Kafka-compatible, streaming data platform designed to be lighter, faster, and simpler to operate. It employs a single binary architecture free from Apache ZooKeeper™ and JVMs, with a built-in Schema Registry and HTTP Proxy. It is much less complex, faster, and more affordable. You can choose from self-deployed or serverless options and get started in seconds instead of days. You can also opt for enterprise-grade support and security for complete peace of mind.