





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

A reference framework for efficiently processing and analyzing vast amounts of industrial IoT data in real time.








This blog lists several key capabilities for a scalable IoT data processing architecture. These include edge device control and communication, scalable data ingestion, real-time and near real-time data processing, and fault-tolerance and reliability. The architecture should also support horizontal scalability, allowing for seamless expansion as the IoT deployment grows.
Edge devices are deployed at the edge of the network and located in close proximity to IoT sensors. They are equipped with computing resources, such as processors, memory, and storage, as well as communication capabilities to connect with IoT sensors or cloud platforms. When equipped with adequate processing power, edge devices can preprocess sensor data at the edge of the network without sending the full dataset to the cloud.
A distributed streaming data platform like Apache Kafka® or Redpanda is important for ingesting and processing large streams of data in real-time or near-real-time, accommodating high data volume, velocity, and veracity. When considering data ingestion at very high throughputs, like double-digit GB/s, with low latency, Redpanda is a good fit overall.
IoT sensors are small, embedded devices that collect real-time data about the environment or the objects they are attached to. They are typically deployed at remote locations where human interaction is limited or nonexistent. Sensors connect to a cloud platform or an edge device to transmit the data they collect. Real-time data transmission happens through wired or wireless connections.
An IoT data processing architecture should prioritize fault tolerance, reliability, and data integrity to ensure data durability and prevent data loss in case of failures or disruptions. It should include mechanisms for data replication, data backup, and high availability. Additionally, robust security measures, including data encryption, access control, and authentication mechanisms, should be implemented to safeguard sensitive IoT data throughout the processing pipeline.
In the era of the Industrial Internet of Things (IIoT), billions of industrial devices are interconnected and generated an exponential volume of data. To harness the full potential of this data and unlock valuable insights, organizations need a scalable IoT data processing architecture.
This post explores the critical capabilities when building such an architecture and provides a reference framework for efficiently handling and analyzing vast amounts of industrial IoT data. From real-time data ingestion and processing to device management and integration with data analytics systems, we'll walk you through the essential components that form the backbone of a scalable industrial IoT data processing architecture.
By adopting these capabilities, you can navigate the challenges of managing and processing massive IoT data streams and pave the way for countless innovative applications and business opportunities.
Let's start from the top.
The Internet of Things (IoT) refers to the interconnected network of physical devices embedded with sensors, software, and connectivity capabilities to collect and exchange data over the Internet. These devices, also known as "smart" or "connected" devices, can be everyday objects (like home appliances and wearables) to industrial machinery and infrastructure.
The Industrial Internet of Things, also known as Industry 4.0 or Industrial IoT, specifically refers to the application of IoT technology in industrial settings and sectors, such as manufacturing, energy, transportation, and agriculture. IIoT focuses on leveraging IoT devices, sensors, and connectivity to optimize industrial operations, improve productivity, and enable data-driven decision-making.
These continuous streams of information from numerous sensors and devices across various environments generate an immense quantity of data. In fact, the global IoT market is estimated to generate 79.4 zettabytes (ZB) of data by 2025!
A scalable IoT data processing architecture requires several key capabilities to effectively handle the ever-increasing volumes of data generated by IoT devices, including:
Edge device control and communication: An IoT processing architecture should prioritize a reliable communication channel between the IoT devices located at the edge of the network and the cloud or the on-prem data center. Furthermore, a centralized device management practice should be enforced to manage the fleet of IoT devices, facilitating zero-touch upgrades, troubleshooting, and registrations.
Scalable data ingestion: The architecture should be able to ingest and process large streams of data in real-time or near-real-time, accommodating high data volume, velocity, and veracity.
A distributed streaming data platform like Apache Kafka® or (the much faster and simpler) Redpanda are popular options. When considering data ingestion at very high throughputs, like double-digit GB/s, with low latency, Redpanda is a good fit overall.
Additionally, the architecture should support horizontal scalability, allowing for seamless expansion as the IoT deployment grows. This involves leveraging technologies that enable elastic scaling, such as containerization with orchestration frameworks like Kubernetes, or auto-scaling capabilities provided by cloud platforms. Horizontal scalability ensures that the system can handle the growing influx of data and accommodate the increasing number of connected devices without sacrificing performance or availability.
Real-time and near real-time data processing: An IoT data processing architecture should integrate with distributed computing frameworks, like Apache Spark™, Apache Flink®, or MongoDB Atlas Stream Processing, for advanced data analytics and processing. These frameworks are ripe for performing complex computations, aggregations, machine learning algorithms, and real-time analytics on IoT data streams.
Fault-tolerance and reliability: An IoT data processing architecture should also prioritize fault tolerance, reliability, and data integrity. It should include mechanisms for data replication, data backup, and high availability to ensure data durability and prevent data loss in case of failures or disruptions. Additionally, robust security measures, including data encryption, access control, and authentication mechanisms, should be implemented to safeguard sensitive IoT data throughout the processing pipeline.
A typical IoT architecture consists of IoT devices deployed at the edge of the network and a central platform deployed in the cloud. The devices are resource-constrained, hence sending the data they collect to the central cloud platform, which leverages scalable storage and computational power for real-time processing.
Addressing the capabilities listed above, we can recommend the following reference architecture for building a scalable, resilient, and secure platform for processing real-time IoT data.
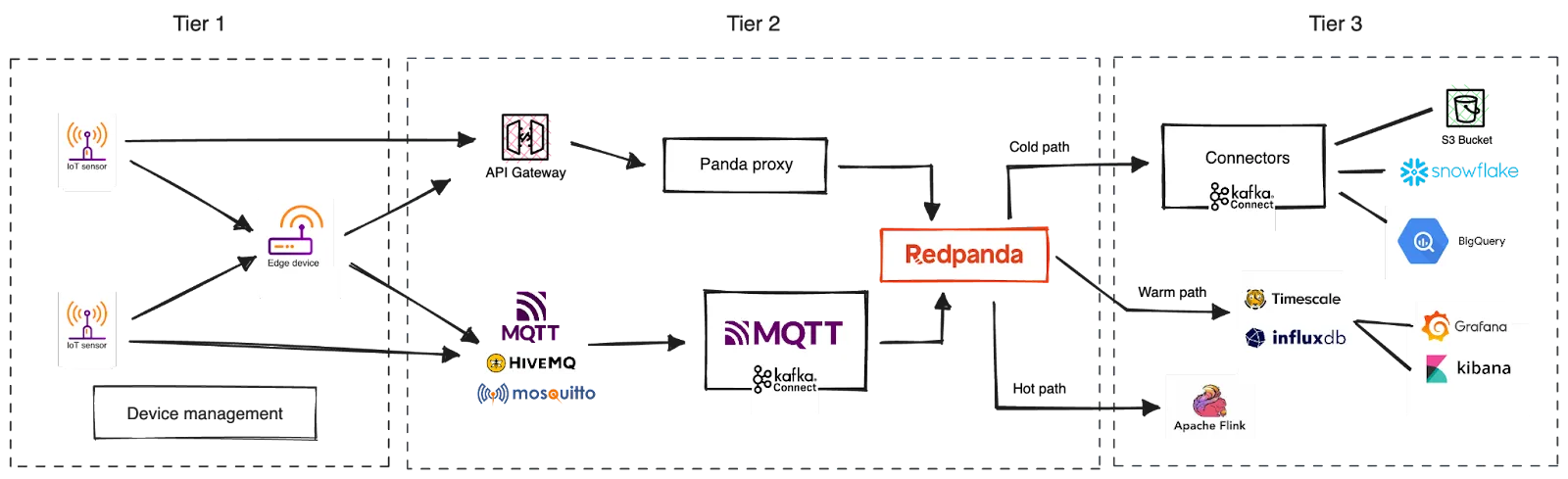
The solution can be partitioned across three tiers based on their role and responsibility.
Tier 1—Devices: Managing IoT devices and their communication with the cloud. This includes the sensors and edge devices deployed at the edge of the network.
Tier 2—Streaming data ingestion: Ingest the streaming data flow originating from devices into the cloud. This includes the cloud gateway and the streaming data platform.
Tier 3—Real-time processing: Process the ingested data in real-time or near real-time to uncover valuable insights and react to them accordingly.
Let’s walk through each component in these tiers to identify its role and the value they add to the overall solution.
IoT sensors are small, embedded devices that collect real-time data about the environment or the objects they are attached to. They are equipped with various types of sensors, such as temperature sensors, humidity sensors, motion sensors, light sensors, pressure sensors, and many others, depending on the specific application.
IoT sensors are typically deployed at remote locations where human interaction is limited or nonexistent. Powered by batteries or solar panels, they are designed to operate with lightweight and resource-constrained operating systems to ensure efficient performance and optimal resource utilization. Some of the common operating systems used for deploying IoT sensors include FreeRTOS, TinyOS, MBed OS, etc.
Sensors don’t work alone. They connect to a cloud platform or an edge device, typically deployed in close proximity, to transmit the data they collect. Real-time data transmission happens through wired or wireless connections, such as Wi-Fi, Bluetooth, cellular networks, or low-power wide-area networks (LPWAN).
An edge device is a device deployed at the edge of the network and located in close proximity to IoT sensors. Edge devices come in various forms and can include gateways, routers, edge servers, embedded systems, industrial controllers, and even IoT sensors with built-in processing capabilities. They are equipped with computing resources, such as processors, memory, and storage, as well as communication capabilities to connect with IoT sensors or cloud platforms.
When equipped with adequate processing power, edge devices can preprocess sensor data at the edge of the network without sending the full dataset to the cloud. For example, they can perform data processing locally, such as filtering, aggregation, analytics, and decision-making. That reduces latency, minimizes bandwidth usage, enhances privacy and security, and enables real-time or near-real-time responses.
When several devices are connected, we need centralized control, security, and efficient management of connected devices in the solution. That’s where a device management system (DMS) becomes important, which plays a vital role in managing and controlling IoT sensors and edge devices.
The device management system facilitates device provisioning and enrollment by ensuring proper registration, authentication, and authorization of devices in the IoT network. The devices are often configured to auto-enroll with the DMS on startup. Alternatively, bulk enrollments are also supported.
Given that the devices are deployed remotely, a zero-touch approach is needed for the configuration, troubleshooting, and administration of devices. Therefore, the DMS enables centralized configuration and updates, allowing administrators to remotely manage device settings, security policies, firmware updates, and software patches as over-the-air (OTA) updates.
Once the sensors and edge devices connect to the network, they start streaming data in real time. The cloud gateway is the component that bridges the network connectivity between IoT devices and the cloud, completing the IoT solution by allowing IoT data streams to reach the central cloud processing infrastructure.
Typically, the cloud gateway is a message broker or an API gateway that translates the communication protocols used by IoT devices to more enterprise-ready protocols. MQTT brokers have been a popular choice here because of the reliable delivery semantics built into the protocol, which is instrumental in handling unreliable Internet connections between the edge and the cloud. HiveMQ and Mosquitto are two popular MQTT brokers in this space.
Alternatively, the devices in the edge could transmit data to the cloud via an API gateway over protocols such as WebSockets, Server-sent Events (SSE), etc.
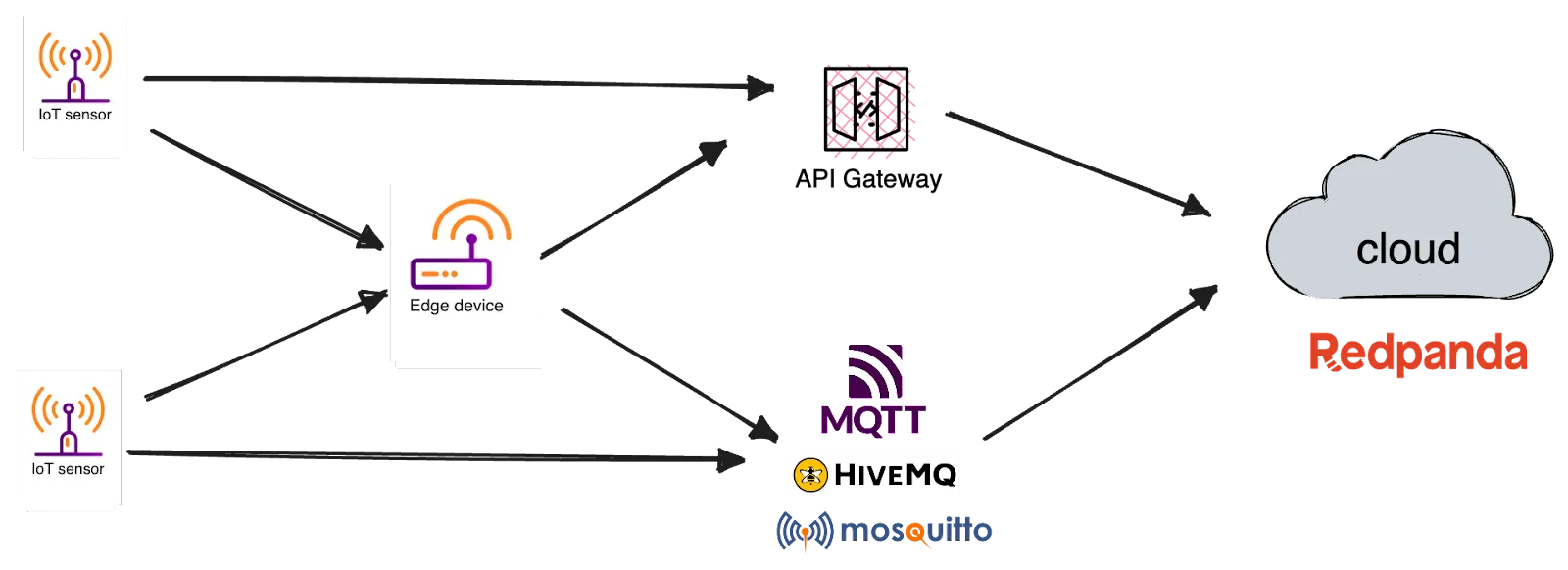
The solution then requires a component to ingest the data streams coming from the Cloud gateway and make them available for downstream processing. This is where a streaming data platform comes into the picture, acting as the first point of contact for incoming IoT data streams.
Redpanda, as a streaming data platform, adds value to the solution across three factors.
Scalable data ingestion: Redpanda enables low-latency, high-volume data ingestion from vast amounts of sensors and devices, allowing downstream systems to react and run real-time analytics on them. Redpanda's elastic scaling capabilities let you add or remove nodes dynamically based on workload demands, ensuring efficient resource utilization and adaptability to changing IoT data requirements.
Seamless compatibility with Apache Kafka: Redpanda is fully compatible with the Apache Kafka protocol and API, allowing you to leverage existing Kafka applications, connectors, and tools within your IoT solution. This compatibility lets you easily integrate with the Kafka ecosystem and seamless migration from Apache Kafka to Redpanda. For example, you can reuse the Kafka Connect MQTT source and sink connector to ingest data from MQTT brokers to Redpanda.
Furthermore, Kafka API compatibility also provides flexibility in connecting Redpanda with other components of your IoT solution, such as data processing frameworks or analytics tools like Apache Flink that are built to work with Kafka.
Cost-efficient event storage: Redpanda’s cloud-first storage engine treats cloud object stores, such as Amazon S3, as the default storage tier, enabling cost-efficient and elastic storage for IoT events in the long term. That means even actively used topics are stored in the cloud, making this data available for a variety of purposes—such as Tiered Storage, remote read replicas, and disaster recovery—regardless of whether the original cluster is still running. This also enables future advanced use cases, such as migrating to other clouds and curating for downstream applications, making the architecture flexible and future-proof.
From a deployment perspective, the solution can benefit from Redpanda Cloud, a fully managed streaming data service deployed in a cloud provider of your choice. Redpanda Cloud offloads management and operational burden from organizations and lets them focus on harnessing value from IoT data. If there are data sovereignty and privacy concerns, consider using BYOC (bring your own cloud) Redpanda clusters, which are hosted in your own VPC, but are fully managed by Redpanda via its control plane.
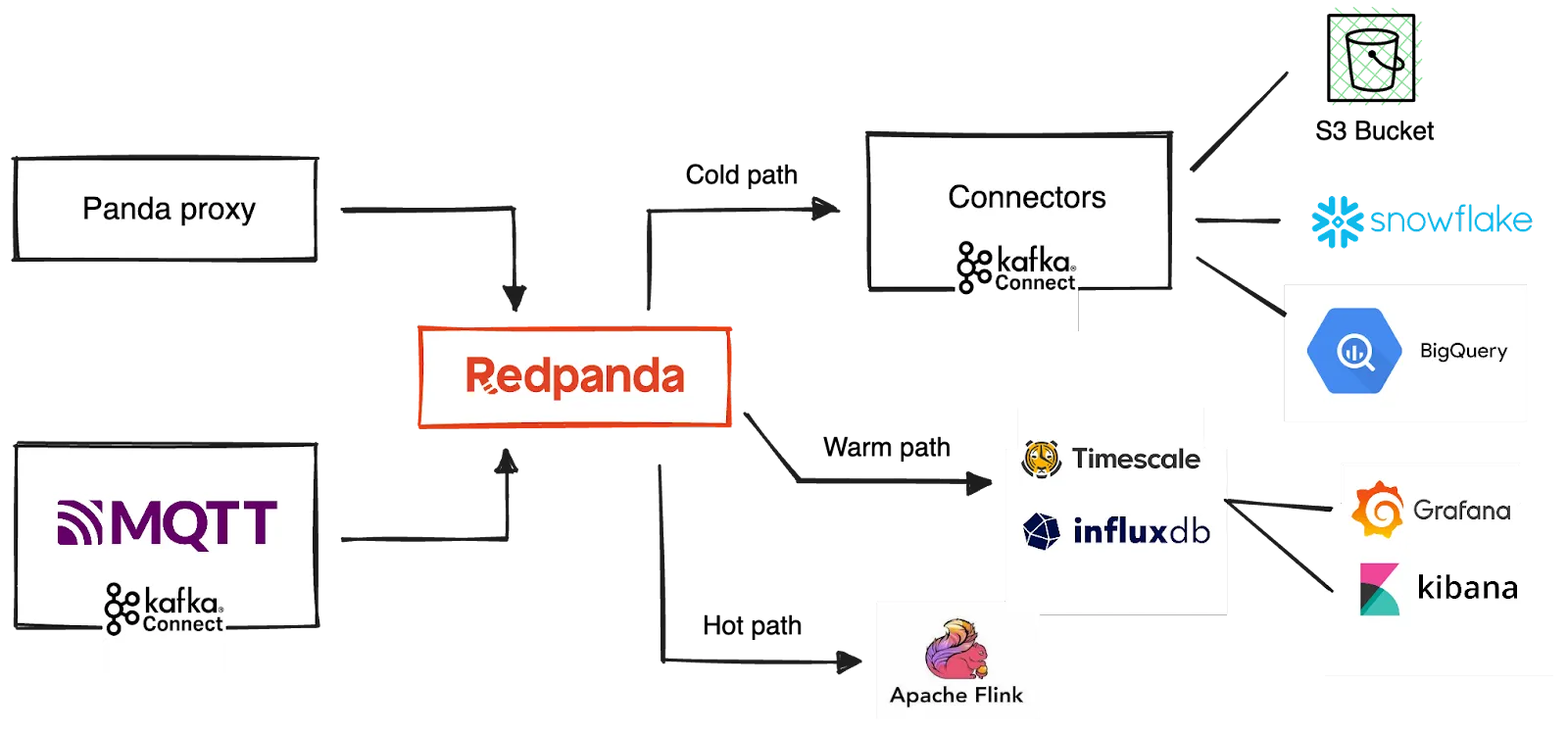
Once the streams are ingested in Redpanda, you can process and explore them to derive meaningful insights and act upon them. The processing typically takes three paths — hot path, warm path, and cold path — based on the requirements for latency and data access.
Hot path analysis: The hot path analyzes data in near-real-time as it arrives and must be processed with very low latency. The solution uses any stream processing engine for this that is compatible with Kafka APIs, such as Spark, Flink, or a streaming database like Materialize. The hot path output typically detects anomalies in the data and triggers alerts for immediate human intervention, like raising an alarm or sending a PagerDuty alert. Alternatively, the processed output is written in a structured format that can be queried using analytical tools.
Warm path analysis: The warm path involves processing data that can accommodate longer delays for more detailed processing. The output is typically written to a time series database for efficient indexing and time series analysis. InfluxDB, Timescale, and Elasticsearch are some popular choices among them. These databases can work with Kafka APIs or can be integrated via Kafka Connect connectors. Once indexed, these databases can feed the real-time dashboards for BI needs, enabling interactive data analysis on time series data. Kibana and Splunk are two popular choices here.
Cold path analysis: The cold path enables long-term data archival as well as batch processing. Organizations typically archive the complete data set coming from IoT devices for compliance and reporting purposes. Redpanda Cloud, the streaming data platform in the solution, provides built-in connectors to cold storage locations, including AWS S3, to move data from Redpanda Cloud for long-term archival. Self-hosted Redpanda deployments can utilize Kafka Connect and its sink connectors as an alternative.
Additionally, the cold path feeds the batch-processing pipelines that move data from Redpanda to a data warehouse, a data lake, or a data lakehouse, enabling BI dashboards and exploratory data analysis for data analysts. The solution benefits from the built-in Snowflake and BigQuery Connectors here.
Also, the cleansed data can be used for machine learning, powering model training, testing, and scoring.
Designing a scalable IoT data processing architecture is paramount to successfully harnessing the potential of the Internet of Things. As the volume and velocity of IoT data continue to surge, organizations must embrace technologies and capabilities that can handle the growing demands. The key capabilities discussed in this post, including real-time data ingestion and processing and device management, form the foundation of a scalable architecture.
As the streaming data platform, Redpanda adds value to the solution by enabling high-volume low-latency IoT event ingestion. By combining its Tiered Storage and efficient hardware resource usage, organizations can keep costs low in the long run.
Furthermore, Redpanda’s full compatibility with the Kafka ecosystem opens the door for endless data integrations—facilitating device data ingestion, stream processing, and moving streaming data toward data lakes, warehouses, and lakehouses to power both real-time and batch and machine learning workloads.
To get started with Redpanda, try Redpanda for free! Then go ahead and dive into the Redpanda Blog for examples, step-by-step tutorials, and real-world customer stories. If you have questions or want to chat with our engineers and fellow Redpanda users, introduce yourself in our Redpanda Community on Slack.
You can't scale what you can't trust. A governance layer fixes that.

Your lakehouse mirrors the database, instantly.

What is it, why enterprises need it, and how to evaluate one
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.