




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
The skyrocketing SaaS industry demands adaptable architectures that can handle real-time data. Here’s how to build them with Redpanda.









The Software as a Service (SaaS) industry is showing unstoppable growth, with a projected $317.55 billion market size in 2024 almost quadrupling to $1,228.87 billion by 2032. This expansion highlights the growing need for enhanced and robust data strategies. This trend is propelled by the increasing volume, velocity and variety of data generated by businesses, coupled with the integration of AI.
However, this escalating growth introduces several important challenges such as managing peak traffic, transitioning from online transaction processing (OLTP) to online analytical processing (OLAP) in real time, ensuring self-service and decoupling, and achieving cloud agnosticism and multiregion deployment.
Addressing these challenges requires a sophisticated architectural framework that ensures high availability and robust failover mechanisms without compromising system performance.
The reference architecture in this post shows you how to build a scalable, automated, flexible data platform to support the growing SaaS industry. This architecture supports the technical demands of handling large-scale data, while also aligning with the business need for agility, cost efficiency and regulatory compliance.
As the demand for services and data volume escalates, several common challenges emerge in the SaaS industry.
Handling peak and burst traffic is necessary to efficiently allocate resources dealing with variable traffic patterns. This requires isolating workloads, scaling up for peak workloads and reducing computation resources during off-peak hours while preventing data loss.
Maintaining OLTP to OLAP in real time means seamlessly supporting OLTP, which manages numerous fast-paced transactions focusing on data integrity, with OLAP systems that enable rapid analytical insights. This dual support is critical for empowering complex analytical queries and maintaining peak performance. It also plays a pivotal role in preparing data sets for machine learning (ML).
Enabling self-service and decoupling requires empowering teams with self-service capabilities to create and manage topics and clusters without heavy reliance on central IT teams. This can speed up development while allowing the application and services to decouple and become independently scalable.
Facilitating cloud agnosticism and stability enables agility and the ability to function seamlessly across different cloud environments (like AWS, Azure or Google Cloud) and geographical locations. Ensuring failover between availability zones and efficiently connecting and sharing data around the globe are also necessary.
To tackle these challenges, large SaaS companies often adopt an architectural framework that includes running multiple clusters across various regions managed by a custom-developed control plane. The control plane's design enhances the flexibility of the underlying infrastructure while simultaneously simplifying the complexity of applications that connect to it.
While this strategy is critical for high availability and robust failover mechanisms, it can also become incredibly complex to maintain uniform performance and data integrity across geographically spread clusters. Not to mention the challenge of scaling resources up or down without compromising performance or introducing latency.
Furthermore, certain scenarios might require isolating data within specific clusters due to regulatory compliance or security concerns. To help you build a robust, flexible architecture that swerves these complexities, I’ll walk you through a few recommendations.
A major challenge with SaaS services is allocating resources to handle various traffic patterns, including high frequency and volume of online queries, data insertions and internal data exchanges.
Transitioning traffic to asynchronous processes is a common solution that allows more effective scaling and quick distribution of computing resources. Data streaming platforms like Apache Kafka® are well-suited for efficiently managing large volumes of data. But, managing a distributed data platform like Kafka presents its own set of challenges.
Kafka’s system is notorious for its technical complexity, as it requires managing cluster coordination, synchronization and scaling, alongside additional security and recovery protocols.
Java Virtual Machine (JVM) in Kafka can also lead to unpredictable latency spikes, primarily due to JVM's garbage collection processes. Managing JVM’s memory allocation and tuning for Kafka's high-throughput requirements is notoriously tedious and can impact the overall stability of the Kafka brokers.
Another hurdle is Kafka’s data policy administration. This includes managing data retention policies, log compaction and data deletion while somehow balancing storage costs, performance and compliance.
The bottom line is it’s tricky to effectively manage a Kafka-based system in a SaaS environment. As a result, many SaaS companies are turning to Kafka alternatives, like Redpanda, a drop-in replacement implemented in C++ that provides highly scalable data streaming without the need for external dependencies like JVM or ZooKeeper.
There’s a growing need for self-service solutions that allow developers to create topics from development to production. Infrastructure or platform services should offer solutions with centralized control, providing sign-on details and automating the quick creation and deployment of resources across various platforms and stages.
This brings up the need for control planes, which come in various forms. Some control planes are used solely for managing the lifecycle of clusters or topics and assigning permissions on the streaming platform. Others add a layer of abstraction by virtualizing the destination and concealing infrastructure details from users and clients.
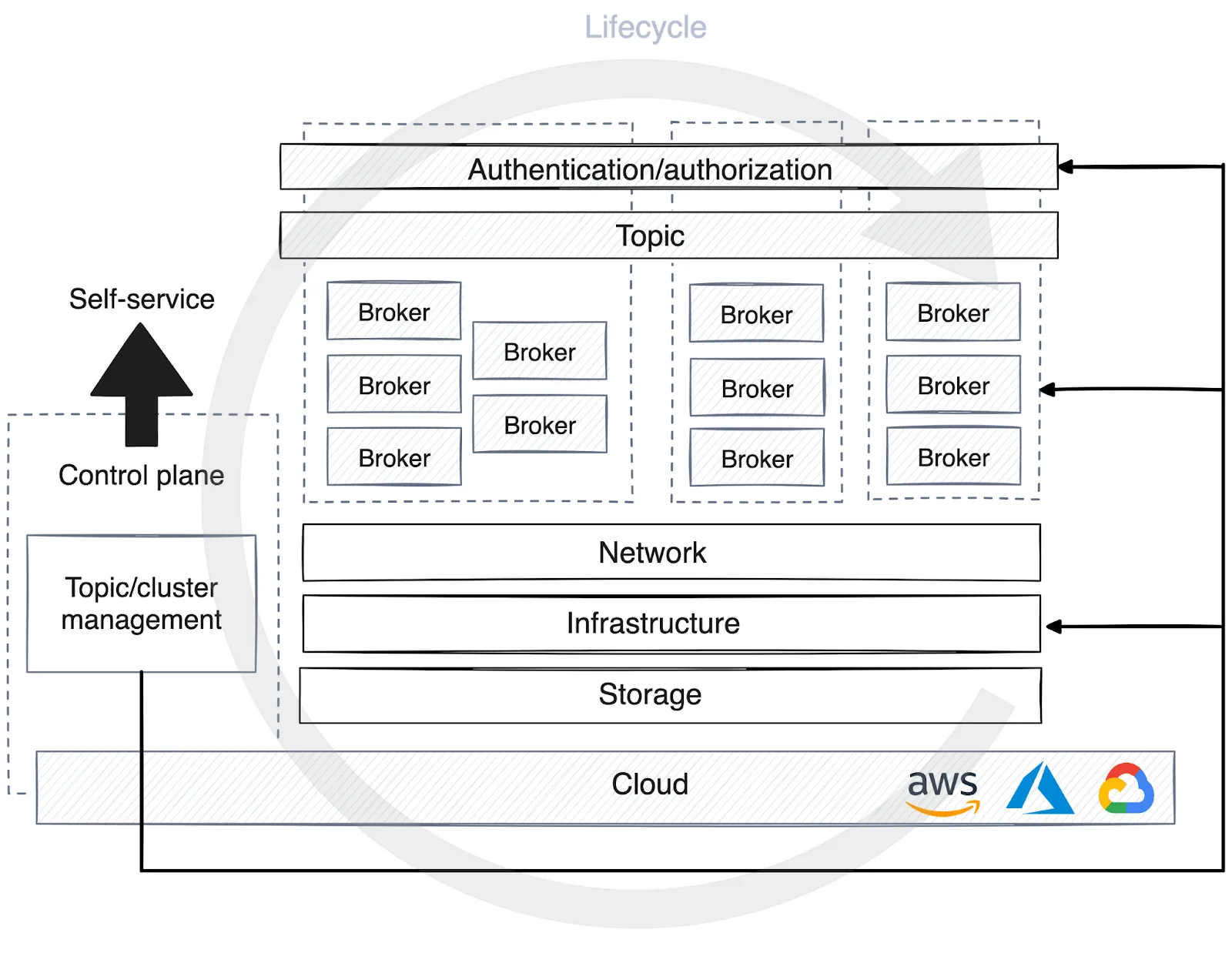
When topics are registered in the control plane of the self-service data platform, different strategies for optimizing computing resources are applied based on the stage of the environment. In development, topics typically share the cluster with other processes, with less emphasis on data retention and most data discarded within days.
In production, however, resource allocation must be meticulously planned according to traffic volume. This planning includes determining the number of partitions for consumers, setting data retention policies, deciding on data location and considering whether dedicated clusters are needed for specific use cases.
It’s helpful for the control plane to automate lifecycle management processes for the streaming platform. This enables the control plane to autonomously commission brokers, monitor performance metrics, and initiate or halt partition rebalancing to maintain the platform's availability and stability at scale.
The shift towards real-time analytics over batch processing has made it essential to integrate OLAP systems into the existing infrastructure. However, these systems often handle large data volumes and require sophisticated data models for in-depth multidimensional analysis.
OLAP relies on multiple data sources and, depending on the company’s maturity, often has a data warehouse or data lake to store the data, as well as batch pipelines running routinely (often overnight) to move data from the data sources. This process merges data from various OLTP systems and other sources — a process that can become complex in maintaining data quality and consistency.
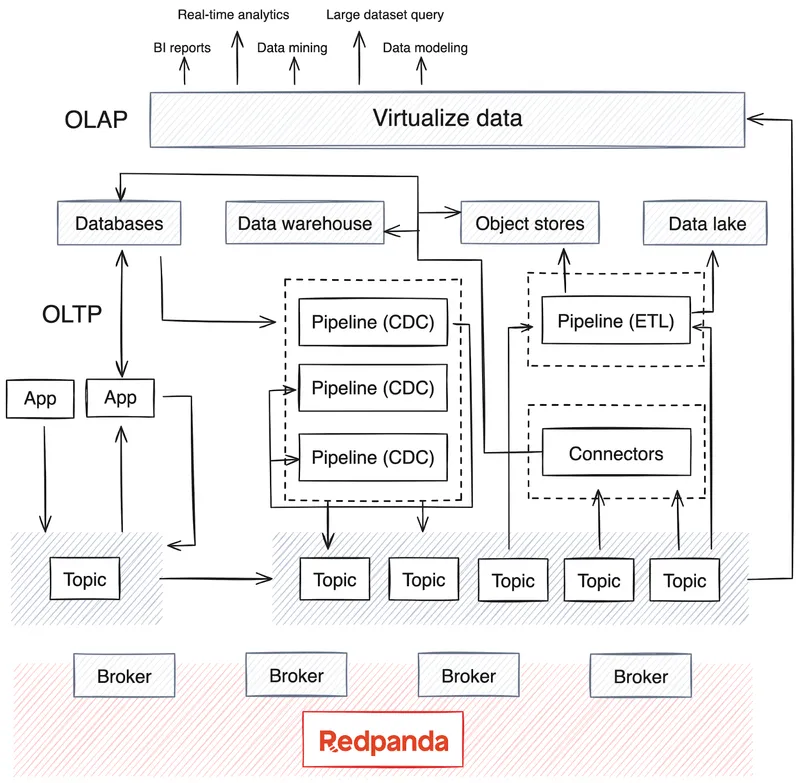
Nowadays, OLAP also integrates AI models with large data sets. Most distributed data processing engines and streaming databases now support the real-time consumption, aggregation, summarization and analysis of streaming data from sources like Kafka or Redpanda. This trend has led to a rise in extract, transform, load (ETL) and extract, load, transform (ELT) pipelines for real-time data, along with change data capture (CDC) pipelines that stream event logs from databases.
Real-time pipelines, often implemented in Java, Python or Golang, demand meticulous planning. To optimize the lifecycle of these pipelines, SaaS companies are embedding pipeline lifecycle management into their control planes to optimize monitoring and resource alignment.
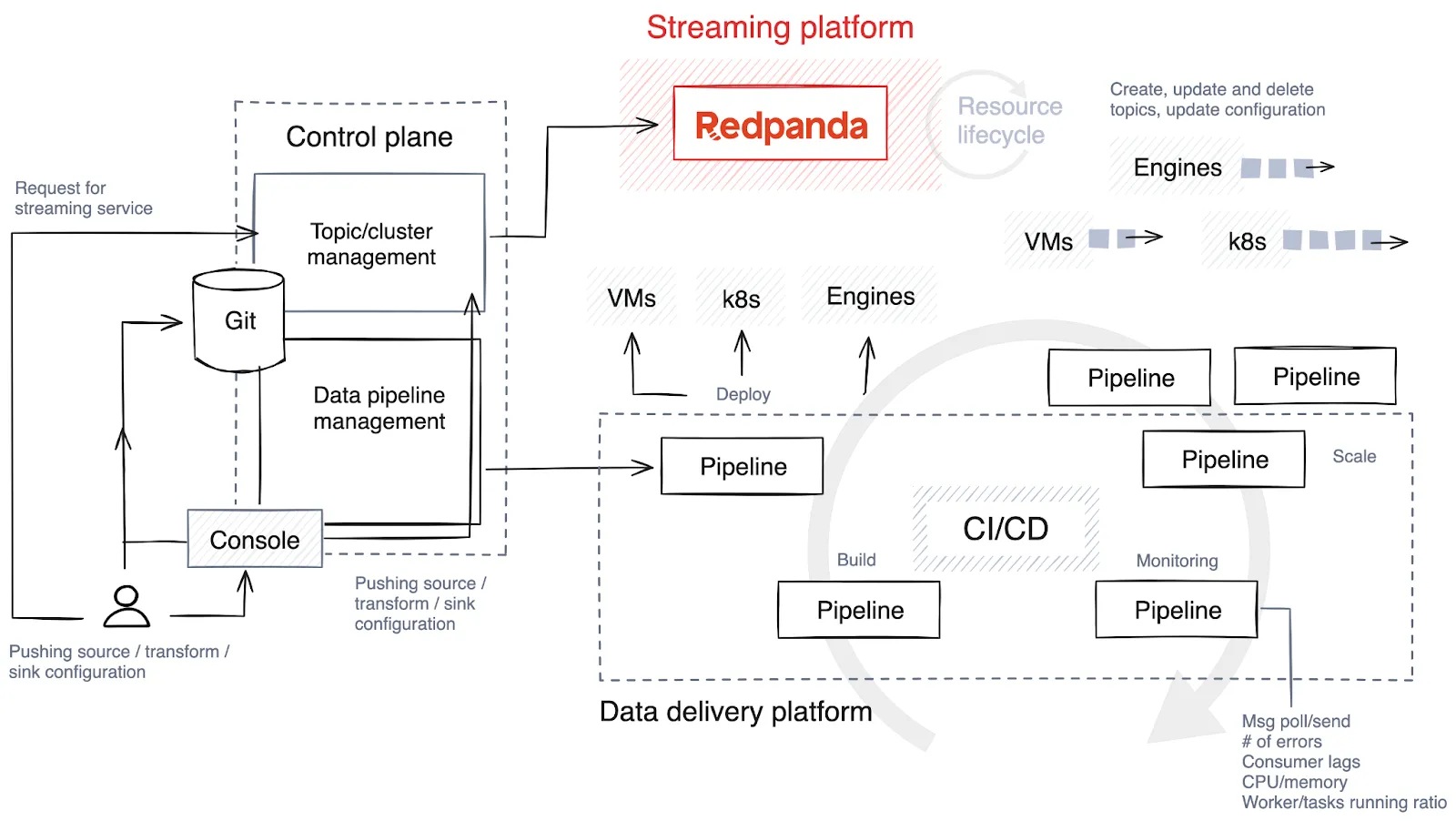
The first step is to choose the technology stack and determine the level of freedom and customization for the users creating pipelines. Ideally, allow them to choose from various technologies for different tasks, and implement guardrails to restrict pipeline construction and scaling.
Here’s a brief overview of the stages involved in the pipeline lifecycle.
Source code is pushed to a Git repository, either directly by pipeline developers or through custom tools in the control plane. This code is then compiled into binary code or executable programs in languages like C++, Java or C#. Post-compilation, the code is packaged into artifacts, a process that may also involve bundling authorized dependencies and configuration files.
The system then conducts automated tests to validate the code. During testing, the control plane creates temporary topics specifically for this purpose, which are promptly destroyed once testing is complete.
The artifact is deployed to a virtual machine (like Kubernetes) or a streaming database, depending on the technology stack. Some platforms offer more creative approaches to release strategies, such as blue/green deployments that enable quick rollbacks and minimize downtime. Another strategy is canary releases, where the new version is applied to only a small subset of data, reducing the impact of potential issues.
The caveat of these strategies is that rollbacks can be challenging, and it can be difficult to isolate data affected by the new release. Sometimes, it’s simpler to do the full release and roll back the entire data set.
Many platforms enable auto scaling, like adjusting the number of running instances based on CPU usage, but the level of automation varies. Some platforms offer this feature inherently, while others require manual configuration, like setting the maximum number of parallel tasks or workers for each job.
During deployment, the control plane provides a default setting based on anticipated demand but continues to closely monitor metrics. It then scales up the number of workers, tasks or instances, allocating additional resources to the topic as required.
Monitoring the right metrics for your pipeline and maintaining observability are key to detecting problems early. Below are some crucial metrics you should proactively monitor to ensure the efficiency and reliability of your data processing pipelines.
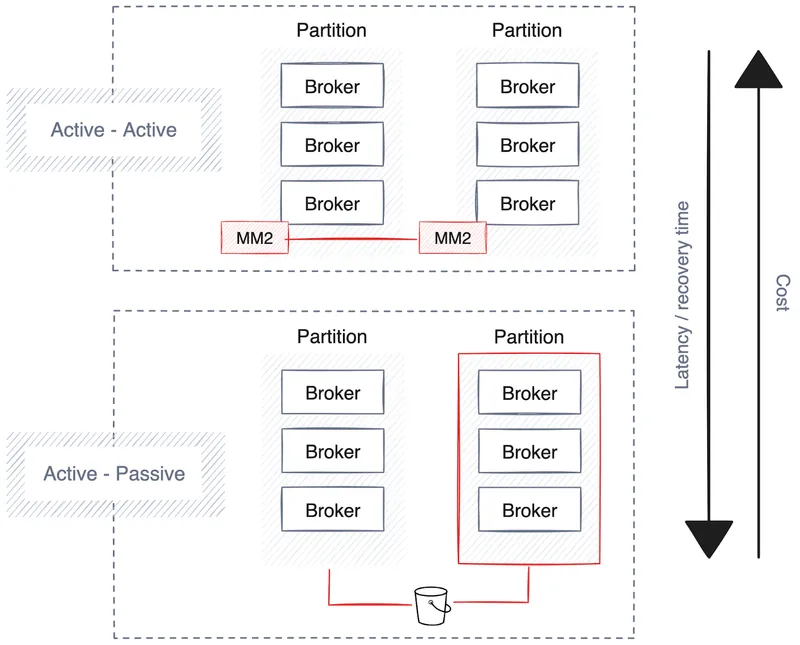
Enterprises prioritize high availability, disaster recovery and resilience to maintain ongoing operations during outages. Most data streaming platforms already have robust guardrails and deployment strategies built-in, primarily by extending their cluster across multiple partitions, data centers and cloud-agnostic availability zones.
However, it involves trade-offs like increased latency, potential data duplication and higher costs. Here are some recommendations when planning for high availability, disaster recovery and resilience.
The automated deployment process managed by the control plane plays a pivotal role in establishing a robust high availability strategy. This strategy ensures that pipelines, connectors and the streaming platform are strategically distributed across availability zones or partitions, depending on the cloud vendor or data center.
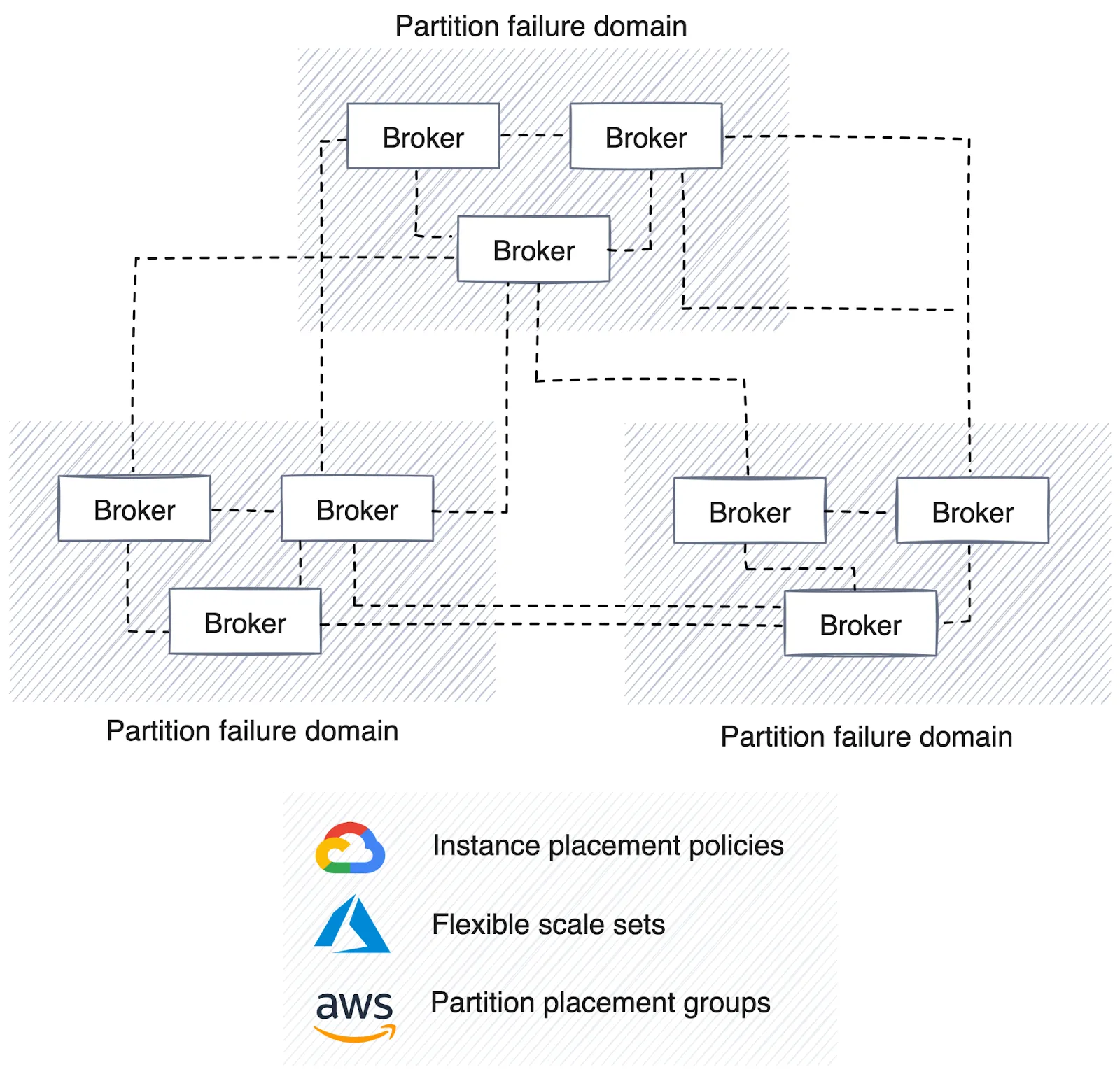
For a data platform, it's imperative to distribute all data pipelines across multiple availability zones (AZs) to mitigate risk. Having redundant copies of pipelines running in different AZs supports continuity to maintain uninterrupted data processing in case of partition failure.
The streaming platform underlying the data architecture should follow suit, automatically replicating data across multiple AZs for resilience. Solutions like Redpanda can automate the distribution of data across partitions, improving the platform's reliability and fault tolerance.
However, consider potential associated network bandwidth costs, taking into account the physical locations of applications and services. For example, having a pipeline running close to the data store lowers network latency and overhead while reducing costs.
Faster recovery from failure drives up costs due to increased data replication, leading to higher bandwidth expenses and mandating an always-on (active-active) setup, doubling hardware usage. Not all streaming technologies provide this capability, but enterprise-grade platforms like Redpanda support data and cluster metadata backups to cloud object storage.
Beyond high availability and disaster recovery, some global businesses require a regional deployment strategy to ensure their data storage and processing conform to specific geographic regulations. Conversely, companies looking to share their data across regions in real time with minimal admin often create a shared cluster, enabling brokers to replicate and distribute data across regions.
However, this approach can lead to significant network costs and latency, as data is continuously transmitted to follower partitions. To mitigate data traffic, follower fetching directs data consumers to read from the geographically nearest follower partition.
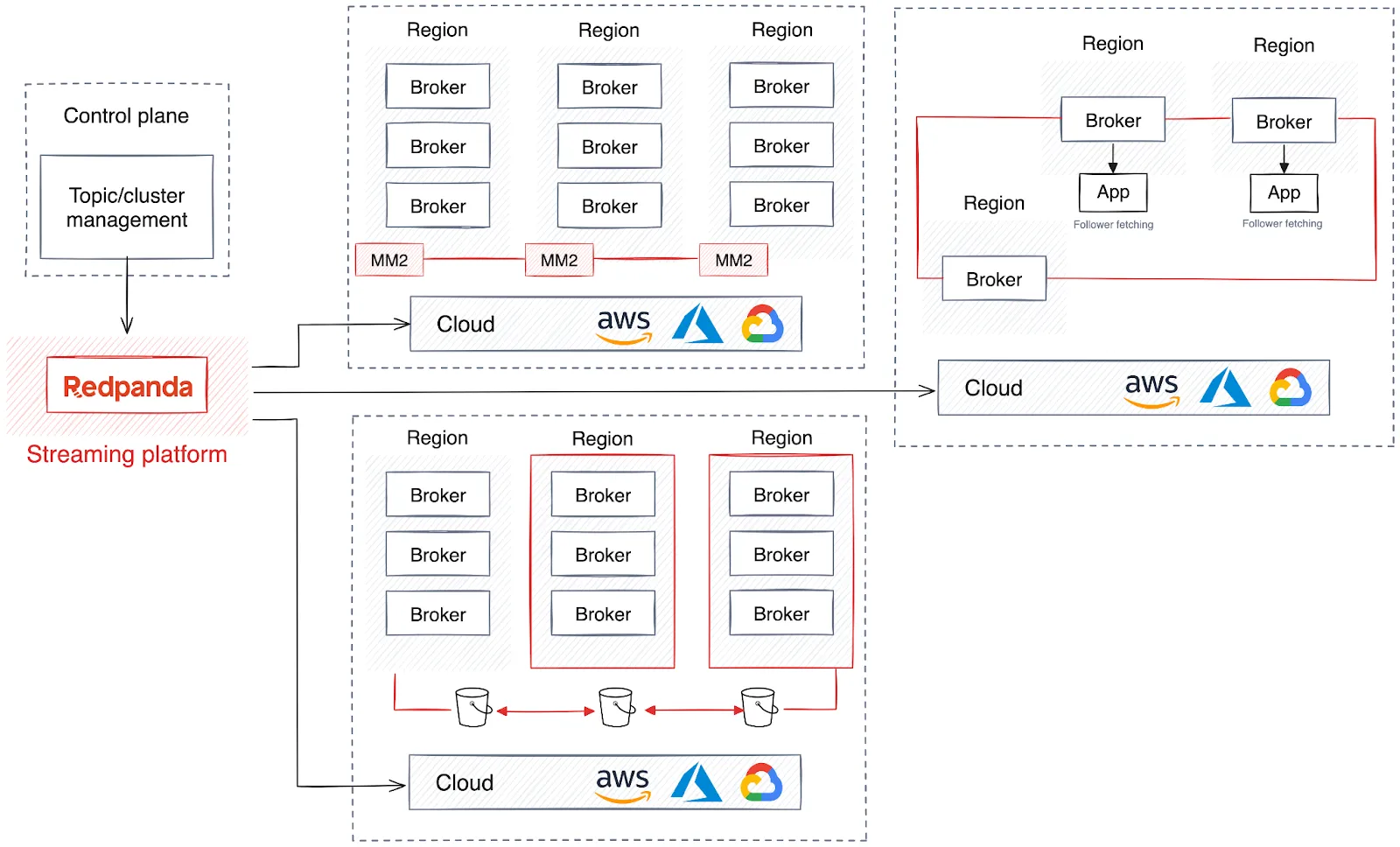
Additionally, expanded clusters for data backfilling improve load balancing across data centers. This scalability is crucial for managing growing data volumes and network traffic, helping enterprises expand without sacrificing performance or reliability.
As companies progress through digital transformation, real-time data becomes increasingly pivotal in guiding decision-making. This involves extracting deeper insights from expansive data sets, enabling more precise predictions, streamlining automated decision-making processes and offering more personalized services — all while optimizing costs and operations.
Adopting a reference architecture incorporating scalable data streaming platforms like Redpanda, a drop-in Kafka replacement implemented in C++. It enables companies to swerve the complexities of real-time data processing by facilitating seamless scaling, an admin API that supports life cycle automation, Tiered Storage to reduce storage costs, Remote Read Replicas to simplify setting up a cost-effective read-only cluster, and seamless geographical distribution.
With the right technologies, SaaS providers can enhance their services, improve the customer experience and sharpen their competitive edge in the digital marketplace. Future strategies should continue optimizing these systems for even greater efficiency and adaptability, so SaaS platforms can thrive in an increasingly data-driven world.
To check out Redpanda for your own streaming data architecture, get in touch with our team for a demo! If you’d rather experiment with it yourself, grab a free trial and get started in seconds.
Originally published on The New Stack.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

