





Deploy agents you can trust with centralized AI governance
You can't scale what you can't trust. A governance layer fixes that.

Meet Evgeny Lazin of the Redpanda Core team, the first engineer to work on our tiered storage architecture.








Working as an engineer at Redpanda offers a lot of freedom and trust, with many opportunities to make an impact on the software developed. Engineers have a sense of ownership over the projects they work on, as their opinions are taken into account. This level of involvement and impact isn't necessarily something that can be found in all engineering roles.
Redpanda's tiered storage solution allows for infinite data retention with good performance at a low cost. It has been engineered to be a beneficial addition to the Redpanda platform. The team is also planning future improvements for tiered storage, including faster data balancing, full cluster recovery, and improved handling of analytical clusters.
Remote Read Replicas is a new feature in Redpanda's tiered storage that allows Redpanda to be used in remote locations. It enables data to be stored in the cloud and made accessible anywhere, facilitating the movement of data across geographic locations. In a way, Redpanda can be used as a CDN for streaming data, allowing consumers to be on the edge instead of a centralized data center.
The Seastar framework powers Redpanda's core platform. It's unique because it allows the full capabilities of modern hardware to be utilized. When engineering tiered storage, the Redpanda team started building basic features through Seastar, such as an HTTP server and S3 client, before moving on to the development of the tiered storage subsystem.
Tiered storage in Redpanda is an architecture that enables cloud storage from Redpanda’s core product. It offloads data to the cloud, helping customers save money on storage costs. The tiered storage subsystem was engineered from scratch to fully utilize the capabilities of modern hardware.
I joined the Core team in the early days of Redpanda, back when the company was still called Vectorized. At the time, tiered storage existed only as a concept. I began developing our tiered storage architecture not long after I started working here and, gradually, other engineers joined that initiative and we built the tiered storage solution we have today.
In this post, I talk about my experience building our tiered storage architecture and what it’s like being an engineer at Redpanda.
When I talk about tiered storage, I’m talking about the architecture that enables cloud storage from Redpanda’s core product. Tiered storage is a feature offloads data to the cloud, thereby helping our customers save money on storage costs. To engineer our tiered storage subsystem, we started completely from scratch and built the architecture to where it is now.
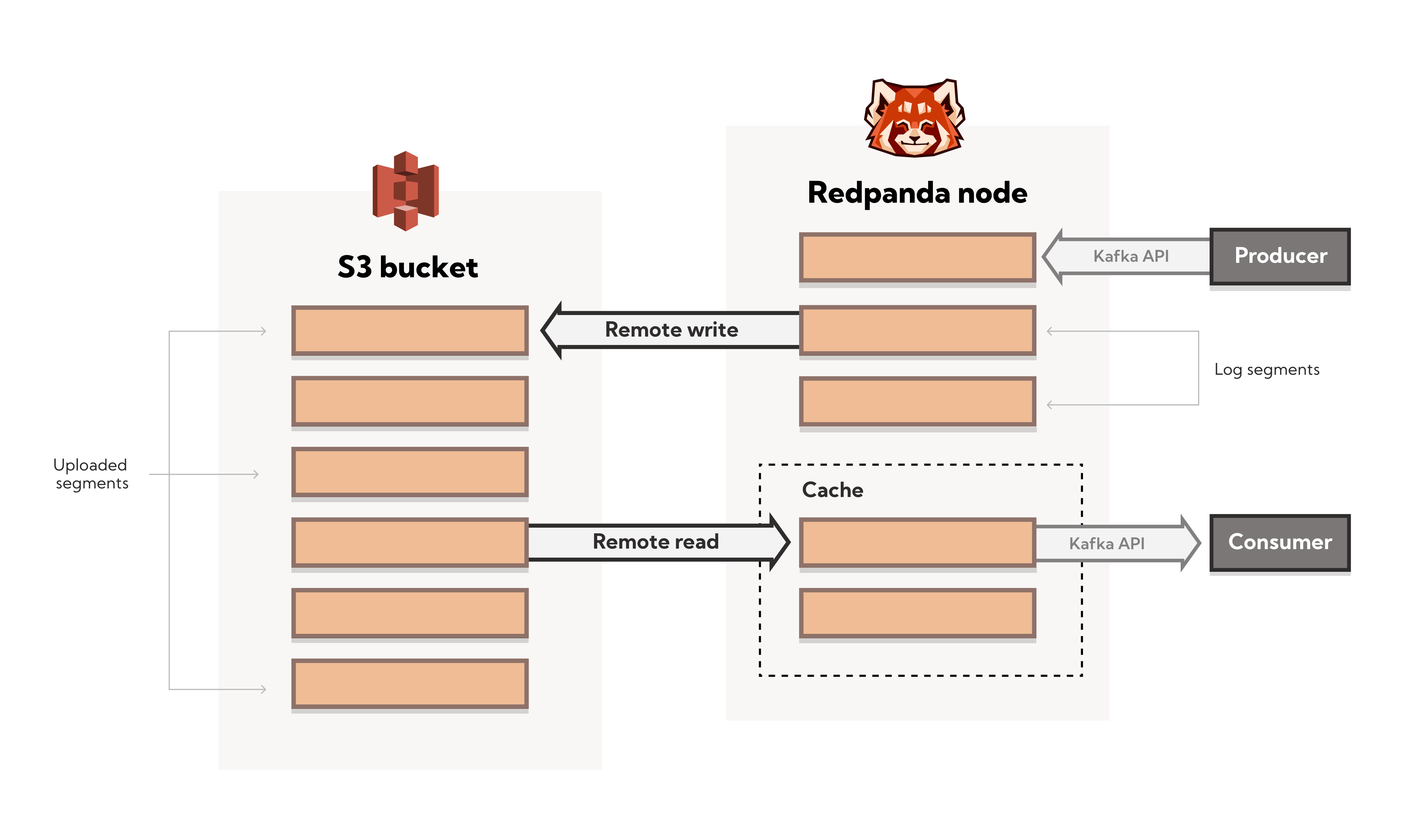
Our core platform is powered by the Seastar framework, which is unique because it lets us use the full capabilities of modern hardware. To engineer tiered storage through Seastar, we had to start out building very basic features. This included building an HTTP server and S3 client. After some of the more basic components of the system were built, we moved on with the development of the tiered storage subsystem.
When the architecture was set up, we went GA with tiered Storage. You can read more about all of these components and how our read and write paths work in my detailed blog post about the architecture here.
As with engineering any new software, developing tiered storage wasn’t without its challenges, but I think the end solution has been a good addition to the Redpanda platform. It allows infinite data retention with good performance at a low cost. Additionally, we’re always planning improvements for Redpanda, and we’ll continue engineering new features for tiered storage in the future. A few items on our list right now are faster data balancing, full cluster recovery, and improved handling of analytical clusters.
Because I like working on projects from the very start and for long periods of time, tiered storage has been especially rewarding to work on. I’ve enjoyed seeing how gradual improvements accumulate and turn proof of concept into a mature product, and I’m excited to see what comes next for tiered storage.
I also like working on tiered storage because it aligns well with my interests. I like to work on storage-related projects and I’m also interested in edge computing. Tiered storage includes a bit of both. It allows Redpanda to be used in remote locations with our new feature called Remote Read Replicas. In some sense, Redpanda can be used as a CDN for streaming data that allows consumers to be on the edge instead of a centralized data center.
For example, perhaps your company has a central database in one location, but it also has various servers around the world. Moving this data across geographic locations can be tricky, but read replicas allow us to store those data in the cloud and make them accessible anywhere.
This job is different from many other engineering jobs. The team here gives you lots of freedom and trust, and you have many opportunities to make an impact on the software we develop. You have a sense of ownership over the projects you work on here because your opinions are taken into account, and it's easy to feel motivated because of that.
In my experience building tiered storage, I got to work on a project for the company over an extended period of time and it had a big impact on what we’re now able to offer to users. Being able to make a difference like that isn’t necessarily something that you can do in any engineering role.
We’re currently hiring for several teams across the company. If working here sounds interesting to you, head over to Careers and browse our open roles. In addition to making an impact on the projects you build, you’ll also get some great benefits, including unlimited vacation days.
Learn more about Redpanda by trying our free Community Edition, check out our source-available GitHub repo, or join the Redpanda Community on Slack to see what other devs are building with Redpanda.
You can't scale what you can't trust. A governance layer fixes that.

What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.