





10X more data, same 4 seconds: testing Redpanda SQL at scale
A benchmark on how a single analytical query behaves as the dataset and cluster grow

How does Apache Kafka measure up after introducing KRaft?








Deploying Kafka with KRaft can be complex as it results in two types of Kafka brokers with different configurations. Kafka clusters continue to risk losing two controller nodes as the brokers, and still rely on the controller cluster retaining quorum to stay operational. Additionally, additional nodes are needed to host the cluster state, as was the case with ZooKeeper.
There are several limitations of KRaft in Apache Kafka. It does not support upgrading existing clusters from ZooKeeper to KRaft, it does not support SASL/SCRAM authentication, and there are changes to command line tooling that don't work with TLS. These limitations can be challenging for users looking to migrate to KRaft.
Last year, a performance benchmark was conducted between Apache Kafka and Redpanda across three different workloads. The results showed that Redpanda is up to 10 times faster than Kafka while running on significantly fewer nodes.
KRaft was introduced in the latest version of Apache Kafka to manage cluster metadata. It leverages the Raft protocol but it's not yet used to manage the data itself. Kafka continues to use its legacy protocol, ISR, for data replication within the cluster.
Last year, we ran a performance benchmark of Apache Kafka® vs. Redpanda across three different workloads. The evidence was clear: Redpanda is up to 10x faster than Kafka while running on significantly fewer nodes.
But our work doesn’t stop there, and competition drives innovation. When releasing exciting new features for improved scalability, reliability, security, and administration—our engineers continually ensure that Redpanda maintains the impressive performance and scale our customers expect.
So with the introduction of KRaft in the latest version of Apache Kafka, we wanted to explore whether this change affected Redpanda’s performance advantage when comparing like-for-like workloads. In this post, we test how Redpanda truly performs compared to Apache Kafka—with and without KRaft—so you can confidently choose the right tool for your real-time streaming needs.
Like others in the Apache Kafka community, we use the Linux Foundation’s OpenMessaging Benchmark project to fairly compare Redpanda against Kafka. The reasons for this include:
We also use the same message sizes as others in the Kafka ecosystem for various benchmarks to ensure a level playing field—and we encourage others to do the same!
An important note is in regard to fsync, which is a function used by Linux to guarantee that the data written to the filesystem is flushed to permanent storage. This is because inherent weaknesses in the In-Sync Replica (ISR) mechanism in Kafka mean that without fsync enabled, you run the risk of losing data in the event of cluster partitioning or common-cause failures.
In keeping with Redpanda’s mission to guarantee data safety and reliability, our testing configures Kafka to fsync all messages. Independent third-party testing has shown that Redpanda is immune to these data safety weaknesses, so you can be sure your data is safe with us.
Furthermore, we also test with TLS encryption and SASL authentication enabled. This is simply because the vast majority of our customers deploy Redpanda with security enabled, and we firmly believe our benchmarks should reflect real-world environments.
Next, we’ll briefly introduce you to KRaft, its pros and cons, and what we factored into our testing. Then we’ll dive into the performance analysis and summarize our findings.
Note: KRaft doesn’t support SASL, so our KRaft tests were performed with SASL/authentication disabled, which may have given Kafka a slight performance advantage in these tests.
{{featured-report="/components"}}
The latest version of Kafka introduced KRaft as a replacement for Apache ZooKeeper™. KRaft, as the name implies, leverages the Raft protocol to manage cluster metadata. However, it’s not yet used to manage the data itself.
Kafka continues to leverage its legacy protocol, called ISR, to manage data replication within the cluster. That said, we welcome the evolution of Kafka to a more current consensus mechanism and hope to see Kafka embrace Raft across its architecture.
KRaft is marked as production-ready in Apache Kafka 3.4.0. Although some limitations remain, including:
These limitations prove challenging for users looking to migrate to KRaft, particularly with no direct migration path. It may also require reworking client applications with changing authentication protocols.
With KRaft, only the metadata and cluster state is stored in the KRaft quorum, whereas topic and partitions still use the ISR mechanism. This inevitably means they continue to suffer from issues like slow-followers and publish latency when replicas are ejected from the ISR set.
In contrast, Redpanda uses Raft for cluster configuration, state, and maintaining consensus around partition replicas. This use of Raft for replication allows Redpanda to offer superior data safety guarantees and avoid documented scenarios where Kafka can lose state and require unsafe leader election.
In the end, it’s still inherently complex to deploy Kafka since you now have two types of Kafka brokers with different configurations. Kafka clusters continue to risk losing two controller nodes as the brokers, and still rely on the controller cluster retaining quorum to stay operational. You also need additional nodes to host the cluster state, as was the case with ZooKeeper.
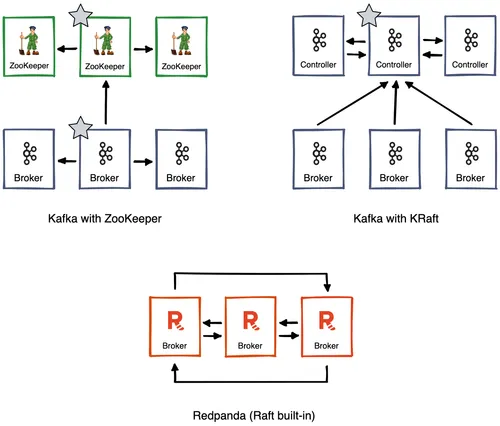
The diagram above illustrates how Kafka’s deployment topology changes as Kafka moves from ZooKeeper to KRaft. In this example of a three-node Kafka cluster, with ZooKeeper there are two leaderships: one for ZooKeeper and one for Kafka itself.
With KRaft, there are now six Kafka brokers: three for Kafka itself and three acting as controllers. Amongst these controllers, Kafka elects a leader for the whole cluster. In Redpanda, Raft is built into the internals of the cluster, so there’s no need for an external quorum service.
In good news for Kafka, its metadata updates do show significantly faster performance. We previously fixed a bug in OpenMessaging Benchmark where Redpanda deleted topics too quickly for OMB to handle. We now find that Kafka hits this bug too!
We carried out tests with and without KRaft controller nodes collocated with brokers, and found that collocation can impact tail performance by 1.5-2x compared to running KRaft on separate nodes. It’s unclear whether Kafka users are deploying KRaft collocated with brokers, but users should be aware of the performance implications of doing so.
To use KRaft, we made changes to the OpenMessaging Benchmark deployment Ansible to deploy KRaft controllers and multi-role brokers. You can find this code in our GitHub repository.
Originally, we ran the 1GBps workload on i3en.6xlarge instance types in AWS and found that Redpanda comfortably handled this workload on a three-node cluster. Next, we explored whether different instance types would affect Redpanda or Kafka’s performance. We tested using the following instance types:
On a like-for-like basis, when running the same number of brokers—Kafka cannot achieve the performance to sustain 1GBps of throughput. We had to add additional nodes to our Kafka clusters just to get them to compete. On Graviton instances (is4gen), Kafka can’t complete the workload at any reasonable scale because of limitations of the Java Virtual Machine (JVM) when running with TLS enabled.
The following table shows how many instances were needed to complete the workload:
Note that when running Kafka, we needed additional nodes to host either ZooKeeper or KRaft controllers, on top of the additional nodes to sustain the equivalent throughput.
Redpanda’s performance was very similar when running on all of these different instance types, which frees the user to consider which instance types best suit their environment (disk size and cost most likely being the determining factors).
The results for Redpanda 23.1 are shown in the following table:
By comparison, the results for Kafka 3.4.0 are shown in the following table:
As you can see, Kafka simply can’t compete on like-for-like hardware. On its nearest comparison, Redpanda is 20x faster at tail latencies than Kafka, with Redpanda running three nodes and Kafka running four nodes—and a further three nodes for KRaft, totaling seven extra nodes.
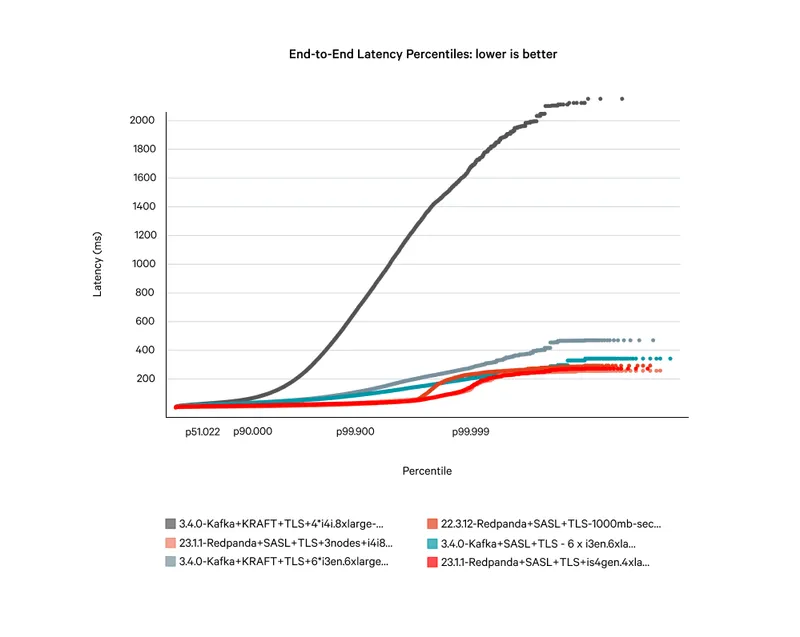
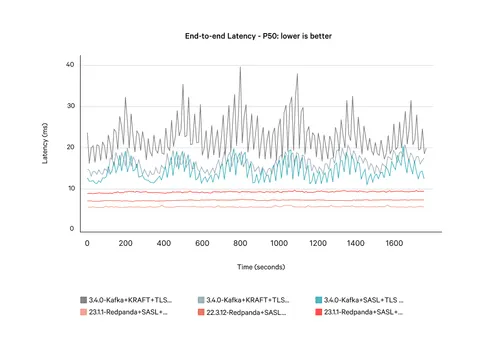
One of the reasons why customers love Redpanda is its strong data safety, thanks to its use of Raft architecture, cloud-first storage for zero data loss, and thorough Jepsen testing. Your data is safe when you store it, without compromising other mission-critical characteristics, such as performance.
This is why Redpanda only acknowledges producing requests once a majority of replicas have fsync’d the request to disk. As mentioned before, the benchmarks in this post run Kafka with fsync since the ISR mechanism can incur data loss when fsync (or flush.messages) is disabled.
But for the sake of argument, what happens when we run with fsync disabled on Kafka? Does Kafka run faster than Redpanda?
The answer is no.
Running on like-for-like hardware, Kafka still displays poor tail latency when running at sustained load. During these high-latency periods, your data is potentially vulnerable to being lost. The diagram below compares the end-to-end latencies for Kafka with and without fsync, against Redpanda with fsync enabled.
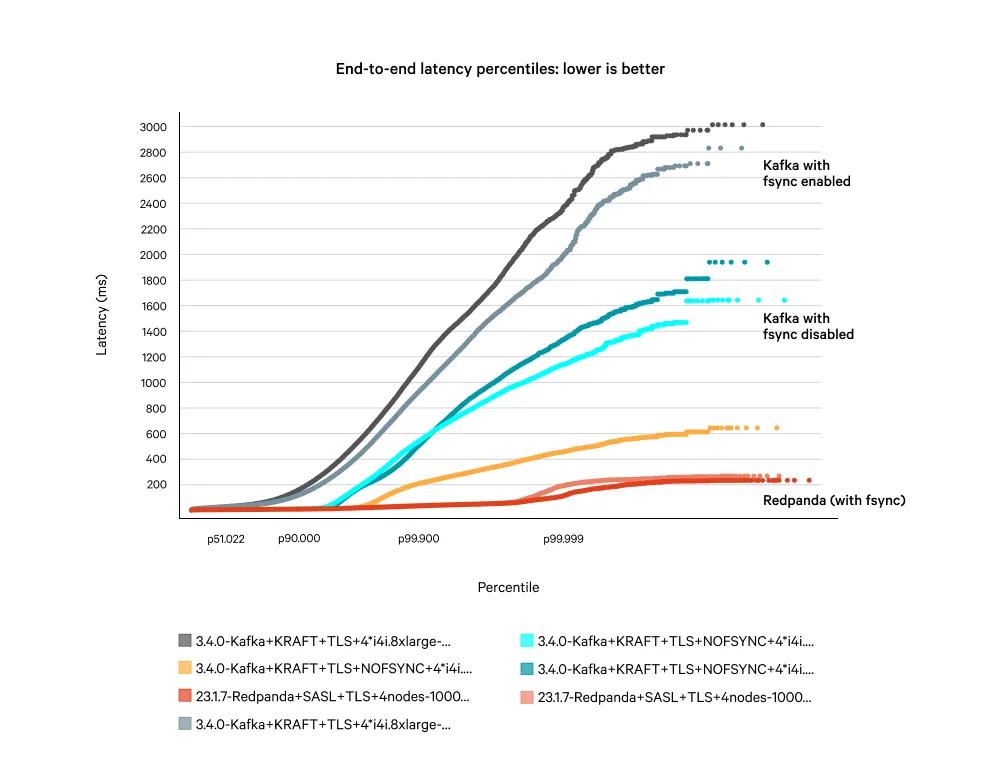
With our latest benchmarking complete, two things are certain: 1) Redpanda remains the most competent and efficient platform for streaming data workloads; and 2) although Apache Kafka has introduced some improvements to metadata performance, including KRaft, the latest updates have not meaningfully impacted Redpanda’s performance advantage.
As we’ve demonstrated, Redpanda can support GBps+ workloads with even the smallest hardware footprints—which remains unrivaled in real-world Kafka deployments.
To summarize:
Bottom line is: Redpanda continues to outperform Apache Kafka with up to 10x lower latencies, thanks to its thread-per-core architecture and hardware-efficient design. As always, you’re welcome to run these benchmarks to see for yourself. For details on how to do this, see our guide to benchmarking.
Have questions about how you can stream data 10x faster with Redpanda? Join the Redpanda Community on Slack or contact us and one of our team will be in touch.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

