




Bridge Queries in Redpanda SQL
Have your real-time cake and eat your analytics too
Better performance and lower latencies = happy customer









Alpaca plans to continue improving their OMS by reducing order processing time, lowering latencies, and enhancing the data throughput of their order execution services. They also plan to leverage Redpanda across many more services based on their positive experience with the platform.
Key components of Alpaca's OMS include OMS nodes with in-memory state, a Distributed Write Ahead Log (WAL) powered by Redpanda, and stateless load balancers. The OMS nodes maintain the account state entirely in memory, while the WAL ensures durability and recovery. The load balancers maintain GRPC connections to each healthy OMS node and forward route calls from the API to the appropriate OMS instance.
Version 2.0 of Alpaca's OMS introduced significant performance improvements including 100x faster order processing and consistently low latency, even during heavy trading volumes. The system is entirely in-memory and independent from other systems and services, eliminating overhead of data marshaling and network round trips of the previous OMS.
Alpaca's Order Management System (OMS) is the intermediary between every client order and the market. It processes orders efficiently and includes processes such as request processing and validation, account state evaluation, market venue routing, execution report processing, and complex order triggers. The OMS is designed for ultra-low latency and scalability to serve millions of investors worldwide.
Redpanda powers the Distributed Write Ahead Log (WAL) in Alpaca's OMS for durability and recovery. When an OMS instance starts up, it can rebuild the state by hydrating the account state from a database and replaying events from Redpanda. This setup also allows other services to listen to trade and order-related events by consuming the WAL in a decoupled fashion.
After years of high-volume algorithmic trading, Alpaca set out to introduce major performance improvements into our Order Management System (OMS). For the unfamiliar, Alpaca is a developer-first API for stock, options, and crypto trading. Our custom-built OMS is designed for ultra-low latency and scale to accommodate millions of investors worldwide.
Performance is at the core of Alpaca’s DNA, and we wanted to build a best-of-breed system that could keep up with our rapid growth. To roll out a faster and easily scalable version of this system, we turned to Redpanda — a unified streaming data platform fully compatible with Apache Kafka® APIs without the need for JVM or other complexities.
Now, Alpaca is excited to roll out version 2.0 of our OMS and provide customers with the following upgrades:
The graph below illustrates how Alpaca’s order processing improved from ~150 milliseconds to consistently under 1.5 milliseconds!

In this post, we walk through Alpaca’s journey to 100x faster order processing with the help of Redpanda’s lean streaming data platform and their invaluable tech support.
At Alpaca, The OMS is the “middle man” between every client order and the market. As the backbone of our trading service, the OMS needs to process orders efficiently. At a high level, OMS processes include:
Since order processing is sequential per account, optimizing order processing time dramatically benefits getting the order to market swiftly. The OMS v2 is entirely in-memory and independent from other systems and services, so we eliminated all the overhead of data marshaling and network round trips of our previous OMS.
For the curious, here’s an overview of our OMS’ architecture.
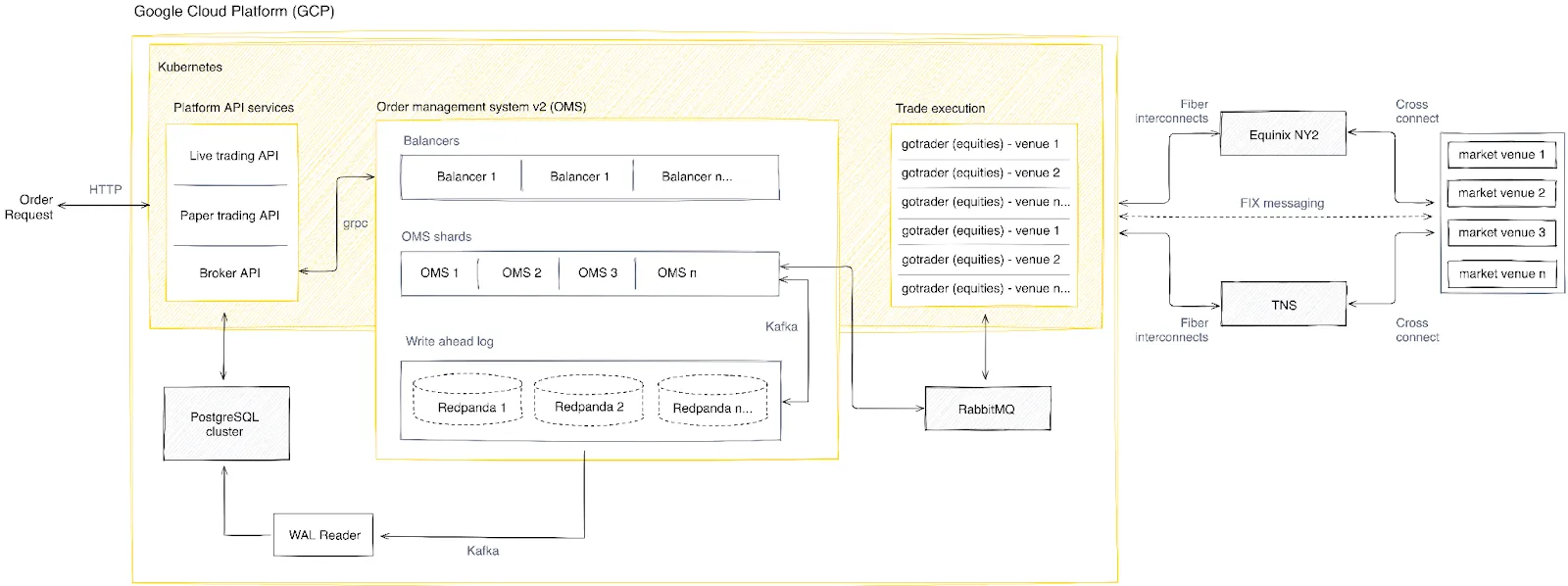
We won’t go into every detail here, but a few key components are worth highlighting.
At the core of OMS v2 are horizontally scalable OMS nodes that maintain the account state entirely in memory. Each OMS is responsible for a particular set of accounts (defined via our sharding strategy).
By maintaining all account states in memory, we avoid significant overhead of the round trips required if the account state lived in a traditional RDBMs. We shifted the account and position state from a single relational database to a set of distributed nodes, each maintaining the state of a subset of accounts.
For durability and recovery, we built a write-ahead log powered by Redpanda. When an OMS instance starts up, it can rebuild the state by hydrating the account state from a database and replaying events from Redpanda, given the last known partition offsets the particular OMS node consumes.
This setup has the added benefit that other services can listen to trade and order-related events by consuming the WAL in an entirely decoupled fashion.
As a bonus, Redpanda introduced us to Travis Bischel — creator of franz-go — the Go client we used to interact with Kafka within OMS v2. TraAs a bonus, Redpanda introduced us to Travis Bischel — creator of franz-go — the Go client we used to interact with Kafka within OMS v2. Travis was extremely helpful in providing suggestions and adding changes to franz-go to support our use case.
We use stateless load balancers that are made aware of the OMS nodes via configuration. Our externally facing platform API communicates with OMS v2 via GRPC calls to our OMS balancer pool. The balancers maintain GRPC connections to each healthy OMS node and forward route calls from the API to the appropriate OMS instance.
While we’re thrilled with our new OMS's significant improvements and scalability, we look forward to continuing our roadmap with further improvements to reduce our order processing time, lower latencies, and enhance the data throughput of our order execution services.
Lastly, we’d like to thank the Redpanda team for their continued support and guidance in designing our write-ahead log. We highly recommend checking out Redpanda’s streaming data platform for its speed and simplified deployment. Working with both the platform and their team — from development to production — was a pleasure. Based on our experience, we plan to leverage Redpanda across many more services.
Check out the Redpanda Blog for examples, step-by-step tutorials, and real-world customer stories. To get started with Redpanda, sign up for a free trial and dive into the Docs.
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.

