




What is an Agentic Data Plane?
What is it, why enterprises need it, and how to evaluate one
Pros, cons, emerging trends, and getting started









Vector databases store data as vectors, ensuring quick query returns and handling increasing scale well. They use approximate nearest neighbor search to accelerate the search process, making them suitable for tasks such as retrieval-augmented generation with large language models. Knowledge graphs, on the other hand, emphasize the relationship between data points using a graph data structure. They represent data in semantic triples, which provide more context but may not be as fast or scalable as vector databases.
Knowledge graphs use a graph data structure that emphasizes the relationship between data points. Graphs are typically made up of nodes (entities or objects) and edges (relationships). Knowledge graphs go beyond this by representing data in semantic triples, which include a subject (a node), a predicate (an edge that defines a relationship), and an object (another node). These triples combine to form the knowledge graph. They are used for tasks like semantic search, recommendation, and retrieval-augmented generation.
While vector databases are excellent at quickly identifying similar data points, they sacrifice some accuracy. They may not produce the correct results or an exact number of correct results. The accuracy of vector databases also decreases as the vectors' dimensions increase. They can only relate data points based on numeric similarity, limiting their precision and specificity compared to knowledge graphs. They provide less context to large language models and the results are less interpretable. Vector databases also struggle with complex queries.
Vector databases are optimized for similarity search, storing raw data as vectors or embeddings, which represent high-dimensional data in a memory-efficient format. They offer high speed and scalability due to their use of approximate nearest neighbor search. They can work with structured and unstructured data, making them versatile. They are also more cost-effective and easier to learn and use than knowledge graphs. Vector databases are well-suited for applications that require continuous or batch data processing.
Vector databases are specialized systems designed to store, index, and query high-dimensional vector embeddings that represent complex data like text, images, audio, or user behaviors. Unlike traditional databases that search for exact matches, vector databases find similar items using distance metrics like cosine similarity or Euclidean distance. They work by converting data into numerical vector representations using embedding models (like BERT for text or ResNet for images), then organizing these vectors using specialized indexing algorithms such as HNSW, LSH, or IVF for efficient similarity search. When querying, the database converts the query into a vector and finds the nearest neighbors in the vector space. Popular vector databases include Pinecone, Weaviate, Milvus, and Qdrant. They enable use cases like semantic search, recommendation systems, image similarity, anomaly detection, and retrieval-augmented generation (RAG) for LLMs. Integration with streaming platforms like Redpanda allows real-time vector updates and similarity searches on streaming data. Key challenges include managing high-dimensional data, maintaining search accuracy while scaling, and balancing between search speed and precision.
Humans learn to understand the world through relationships between objects. For example, most people will recognize a dog as an animal, or that books go on shelves. This mutual understanding of objects facilitates daily interactions and societal functions. Similarly, computers must grasp relationships between data points for tasks like content retrieval or answering queries. Vector databases and knowledge graphs are commonly used methods for organizing this data.
Although you can’t talk about vector databases without understanding vectors. In this context, vectors are numerical arrays that contain fundamental information about specific data points. A vector database stores these vectors with pointers to the raw data they represent, which lets you perform all the typical CRUD operations associated with databases quickly and at scale.
Knowledge graphs, on the other hand, use a graph data structure that emphasizes the relationship between data points. Graphs are typically made up of nodes (entities or objects) and edges (relationships). Knowledge graphs go beyond this by representing data in semantic triples, which include a subject (a node), a predicate (an edge that defines a relationship), and an object (another node). These triples combine to form the knowledge graph.
Vector databases and knowledge graphs let you actually use the data and build systems that carry out tasks like semantic search, recommendation, and retrieval-augmented generation (RAG). This post compares these data layers based on how they structure data, their speed, and scalability, the types of data they work best with, how well they integrate with machine learning models, how simple they are to learn and use, and their suitability for streaming data and applications.
A vector database stores mathematical summaries of high-dimensional data, also known as vectors or embeddings. These representations capture the essence of various types of data, such as text, images, audio, or tabular information. By condensing the data into a smaller array, the database maintains enough detail for the computer to comprehend the original information. You can then easily query these vectors, whether you're looking for an exact match or similar data points.
Vector databases are designed to ensure that your queries return the desired results quickly. They also handle increasing scale very well. Some can search millions of vectors with a latency of milliseconds.
This capability relies on the nearest neighbor search technique, which compares a query vector to stored vectors and returns the ones with the highest similarity scores. In vector space, similarity is indicated by the proximity of vectors to each other. While this approach (particularly the k-nearest neighbors algorithm) is popular, it struggles with scalability.
To address this, vector databases employ approximate nearest neighbor search, a modification of the algorithm that accelerates the search process while sacrificing accuracy to some extent. Vector databases implement this in a variety of ways, including graph-based search techniques like hierarchical navigable small world (HNSW), hashing, and quantization. This makes them suitable for tasks such as RAG with large language models (LLMs), anomaly detection, and similarity search.
Some of the advantages of using a vector database are listed below:
Some disadvantages of using a vector database are listed below:
Vector databases can be integrated with data streams from a variety of sources. When data is ingested from these sources, a message can be published via Redpanda, a streaming data platform that can be used as a drop-in replacement for Apache Kafka®. You can then consume these messages via a service that generates vectors from raw data using an appropriate machine learning model and then returns a message indicating that a vector has been produced.

This message can then be consumed by a vector database, such as Pinecone, and the vector stored. Any service requiring access to the database can then perform queries. Thus, you can use Redpanda to integrate a vector database with a continuous stream of data.
A knowledge graph represents a collection of real-world entities and their relationships. The graph organizes data into subject-predicate-object (SPO) triples, like "Victoria-plays-the clarinet." These triples contain context about aspects of the data, and multiple triples may be required to describe a single data point. Knowledge graphs are typically created using data from various sources, fed into a schema that normalizes them to the SPO format.
Machine learning techniques (such as natural language processing) can aid in this process by extracting entities and their relationships from data and incorporating them into the graph through a process known as semantic enrichment.
Knowledge graphs are "directed" graphs because the SPO structure is only meaningful in one direction. The subject does not have the same relationship to the object as the reverse. A statement like "Christopher wears shoes," in which each word represents the subject, predicate, and object in that order, has no meaning when read backward: "shoes wears Christopher." The directional nature of knowledge graphs is useful since it allows you to track the relationship between items and understand the nature of that connection. In a graph containing information about Christopher's wardrobe, you can precisely retrieve all the items he wears by following the "wearing" relationship between Christopher and his wardrobe items.
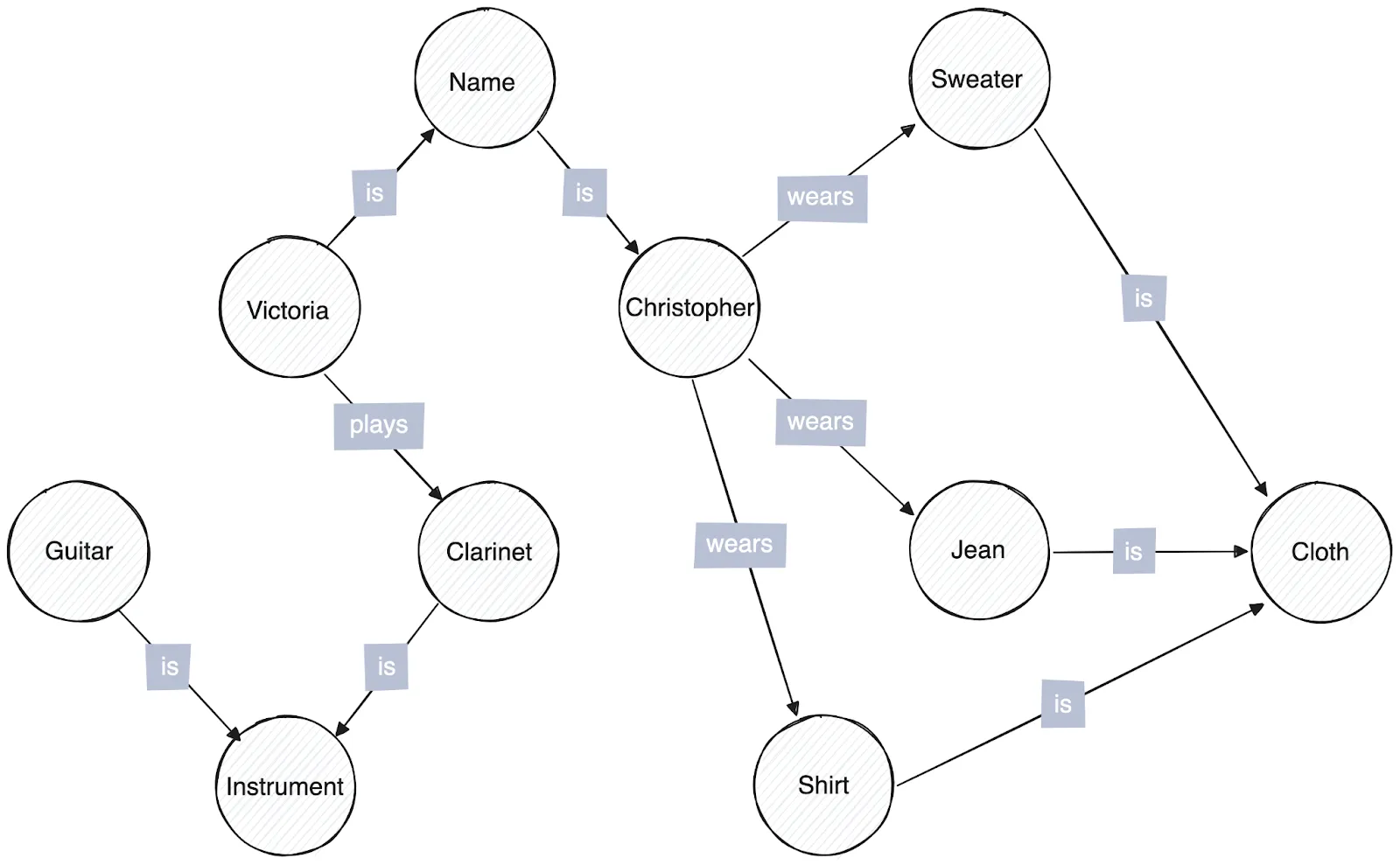
Aside from the relationship in the data, knowledge graphs formalize the relationship between entities using well-defined ontologies. For example, if a graph connects users to phone models, there would be triples connecting those models to brands, brands to the company that created them, companies to industries, and so on. Search engines such as Google and Bing have used this data representation technique to create graphs that connect the entire public internet, making searching more efficient and useful. Facebook and eBay have also used knowledge graphs to build user and product recommendation systems. They are also increasingly being used to augment LLMs in solving RAG problems.
Some of the important advantages of using a knowledge graph include:
Some disadvantages of using a knowledge graph include:
Lower speed and scalability: Knowledge databases require more time to create and update. This is due to the number of entities and relationships that may need to be extracted from the data and accurately inserted into the graph. This makes them slower than vector databases, designed to operate much faster. This speed issue worsens with scale, making vector databases the better option.
Limited support for unstructured data types: Knowledge graphs are also limited in terms of the types of data they can process. They work best with structured data, as the relationships between entities are easier to determine. Unlike vector databases, they fall short with unstructured data and may require additional machine learning operations to extract entities and relationships from them to form the required knowledge structure.
Higher operational costs: Knowledge graphs tend to incur significantly higher costs due to the rapid expansion of graph size as more data points are added, as well as the ongoing expenses associated with updating them in terms of time and resources. This makes vector databases the preferred option when storage and maintenance costs need to be minimized.
Steeper learning curve: Knowledge graphs are an interesting but complex data structure to understand and implement. To create a useful knowledge graph, you must first understand your data thoroughly. They also require you to learn a query language to interact with them. This leads to a steeper learning curve for knowledge graphs compared to vector databases, making them less usable, especially for beginners.
Limited streaming applications: Knowledge graphs are also limited in handling data streams in real time. They are typically designed to process data and update the graph in batches, as opposed to vector databases, which can be used for real-time streaming or batch processing, depending on your needs.
Knowledge graphs, such as ones from Neo4j, can be configured to accept data from multiple sources and convert it into SPO triples. However, due to the slow insertion time of graphs, data must be aggregated over a fixed time window or number of samples before being processed in batches. Redpanda allows you to accumulate data ingested by tracking the corresponding messages produced and then consuming them for processing once a batch is complete.
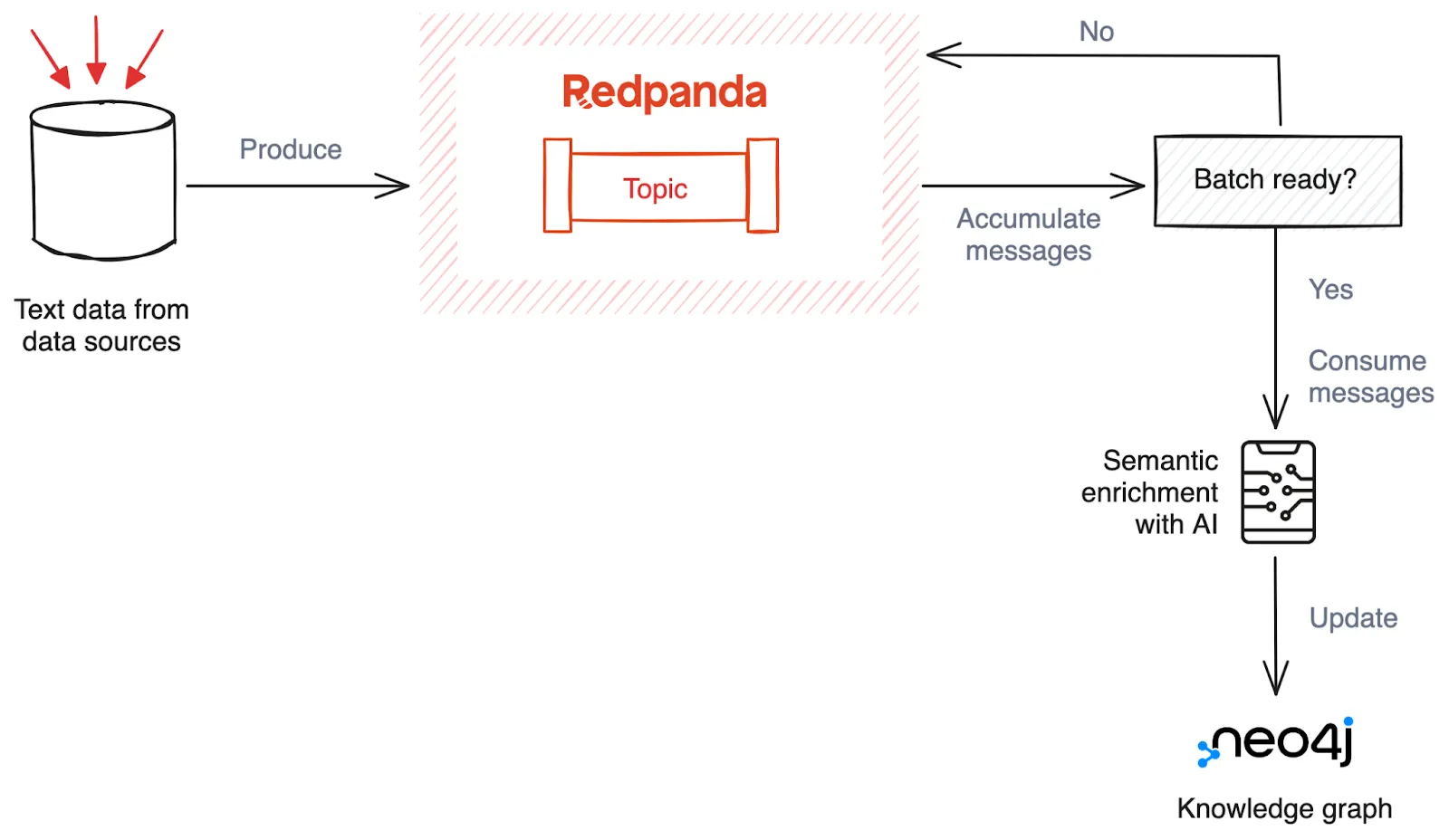
This processing may require an additional service that employs machine learning models to extract entities from unstructured data to populate the graph. The knowledge graph is then updated, and a message can be generated using Redpanda, after which your system can proceed with other tasks. (Psst! Check out Redpanda’s Engineering Corner on YouTube. You might be interested in their demo featuring Neo4j for advanced graph analysis.)
The table below summarizes how vector databases and knowledge graphs compare:
This post should help you decide which data layer suits your specific use case and requirements. For example, if you need to stream data in your application, vector databases are a better fit.
Whether you choose a vector or knowledge graph database, you can use Redpanda to manage your data streams. To take it for a free spin, sign up for Redpanda Serverless and follow along with the documentation.
Want to keep learning? Check out our post on vector databases vs. graph databases.
What is it, why enterprises need it, and how to evaluate one

Enterprise agents need governance infrastructure, not just better models

What AI trends will shape analytics in the coming months?
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.