





10X more data, same 4 seconds: testing Redpanda SQL at scale
A benchmark on how a single analytical query behaves as the dataset and cluster grow

Redpanda delivers at least 10x faster tail latencies than Apache Kafka and uses up to 3x fewer nodes to do so!








Redpanda invests hundreds of compute hours in continuously regression testing performance aspects of its codebase to microsecond accuracy. This approach ensures that no creeping death of performance degradation is introduced.
Redpanda is able to work on ARM-based hardware with no problem, and actually runs faster on smaller machines. However, Kafka suffers severe performance degradation and is unable to complete the workload, due to previously documented problems running Java on ARM.
Redpanda can deliver the same results on instances smaller than i3en.large, such as the Graviton is4gen.medium. Kafka, on the other hand, has severe performance issues running on ARM hardware due to inefficiencies in Java’s crypto providers. This alone can offer an immediate 57% byte-per-dollar cost saving with Redpanda.
Redpanda is written from scratch in C++, with a completely different internal architecture than Apache Kafka. This unique architecture is designed to keep latencies consistent and low, which is one of the principal tenets of Redpanda.
The performance benchmark suggests that Redpanda delivers at least 10x faster tail latencies than Apache Kafka—with up to 3x fewer nodes. Even at higher throughputs, Redpanda remains at least 2-3x faster. Redpanda can break the 1GB/sec barrier without breaking a sweat, while Kafka requires at least double the hardware and introduces severe latency penalties.
Check out our latest performance analysis: Redpanda vs. Kafka with KRaft
Written from scratch in C++, with a completely different internal architecture than Apache Kafka®, Redpanda was built by an engineering team obsessed with performance. Keeping latencies consistent and low is one of the principal tenets of Redpanda.
Our initial blog on this topic remains one of our most-read blog posts. So it only made sense for us to refresh the performance benchmark to see how we’ve done on speed since then. After all, subsequent software releases are notorious for impacting performance (for example, Microsoft famously changed its engineering practices to focus on performance for Windows 7).
Redpanda invests hundreds of compute hours in continuously regression testing performance aspects of its codebase – to microsecond accuracy – an approach that ensures that we don’t introduce a creeping death of performance degradation.
In this post, we will explore the end-to-end latency of Redpanda and Apache Kafka 3.2 under workloads (up to 1GB/sec) that are common to our customer environments. We will compare the average latencies as well as the 99.99th percentiles (p99.99) to understand how both systems fare while keeping the hardware and configuration settings identical. (If you also want to learn about the Total Cost of Ownership for Redpanda vs. Kafka, check out this post.)
In short, our findings suggest the following: Redpanda delivers at least 10x faster tail latencies than Apache Kafka—with up to 3x fewer nodes!
We used The Linux Foundation’s OpenMessaging Benchmark, including a number of changes that were introduced by Confluent two years ago and more recent improvements such as avoiding the Coordinated Omission problem of incorrect timestamp accounting. We also addressed an issue in the OpenMessaging Benchmark Kafka driver that would repeatedly send async consumer offset requests without any coalescing.
For each test, we did three runs of each workload, each with a 30-minute warm-up. For the clients, we ran on four m5n.8xlarge instances, which ensured guaranteed 25Gbps network bandwidth with 128GB of RAM and 32 vCPUs to ensure our clients were not the bottleneck. We used Kafka v3.2.0 and Redpanda v22.2.2 throughout.
We devised three workloads based on increasing throughput and a partition count based on the number of CPUs in our target instance types.
We used 50 MB/sec, 500 MB/sec, and 1 GB/sec as representative workloads. These values indicate the write throughput and we have assumed a 1:1 read-to-write ratio, so the total throughput of each workload can be effectively doubled. We regularly work with customers who have workloads within these ranges and often above as well. For these tests, we measure end-to-end throughput and end-to-end latency, with two producers writing and two consumers reading from a single topic across a number of partitions. Consistency in end-to-end latency is important for ensuring that applications are able to meet SLAs at scale.
All tests were conducted on AWS, with identical instance types for running both Kafka and Redpanda in each test. The three workloads we tested are summarized in Figure 1 below:
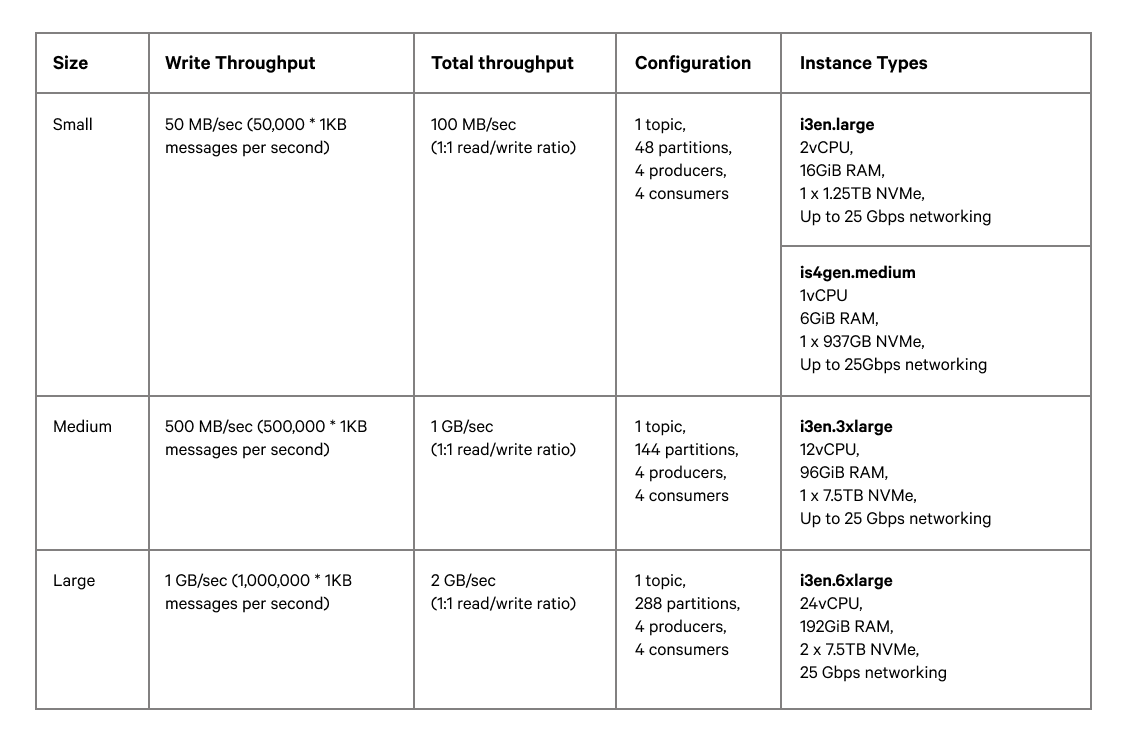
Figure 1. Details of small, medium, and large workloads used in testing.
The instance sizes are chosen to include NVMe disks, which are 1000x faster in terms of IOPS compared to spinning disk, with Redpanda specifically optimized to take advantage of modern hardware. The quicker we can commit transactions to disk, the better the data safety we can offer — meaning Redpanda remains the obvious choice when choosing based on both performance and data availability.
We experimented with different partition quantities for each workload, but didn’t see significant differences above 4 partitions per core on each machine.
The tests all ran with the following client settings:
Both Kafka and Redpanda are configured for maximum data safety as we repeatedly hear that users are unwilling to lose customer or audit data in the event of some sort of failure, transient or otherwise. Again, our goal was to mimic mission-critical customer environments as closely as possible.
After more than 200 hours of testing various configurations and permutations, our results confirmed what we have previously seen when comparing Redpanda against Kafka:
We also found that once Kafka reached its stress point, it wasn’t easily rectified by adding more nodes. This indicates that there is additional stress on Kafka’s internal synchronization mechanisms that are not alleviated by adding nodes in the way that we would have previously expected.
The following sections compare each of the workloads in more detail.
We started the testing with the smallest of our workloads, at 50MB/sec against i3en.large instance types. Redpanda was able to comfortably handle the workload, yet Kafka showed performance degradation at the tail percentiles. As we felt that the hardware was being under-utilized with Redpanda we investigated using is4gen.medium (AWS Graviton) instances.
Redpanda is able to work on ARM-based hardware with no problem, and actually ran faster on the smaller machines. However, Kafka suffered severe performance degradation and was unable to complete the workload, due to previously documented problems running Java on ARM. Because our workloads are configured to use TLS for produce and consume traffic, the OpenJDK JRE was unable to handle the throughput.
To date, Amazon does not provide an official build for the Corretto Crypto Provider and, at the time of writing, the trunk build did not pass unit tests and would not build on ARM. For this reason, we were unable to proceed testing Kafka on ARM. However, the conclusion is clearly that Redpanda is able to thrive on these smaller and more efficient instances (in fact, the is4gen.medium instance was able to sustain throughput at almost double the 50MB/sec test workload!).
Figures 2 and 3 show the latency profile for Redpanda and Kafka with a 50MB/sec workload on a same-sized cluster. Redpanda was up to 38% faster than Kafka at the tail (P99.99 and above) and 17% faster at the average. However, in Figure 3 we can see that Kafka’s average latency was much less stable than Redpanda’s, which could perhaps be attributed to factors such as Java Virtual Machine (JVM) garbage collection and interactions with the Linux page cache.
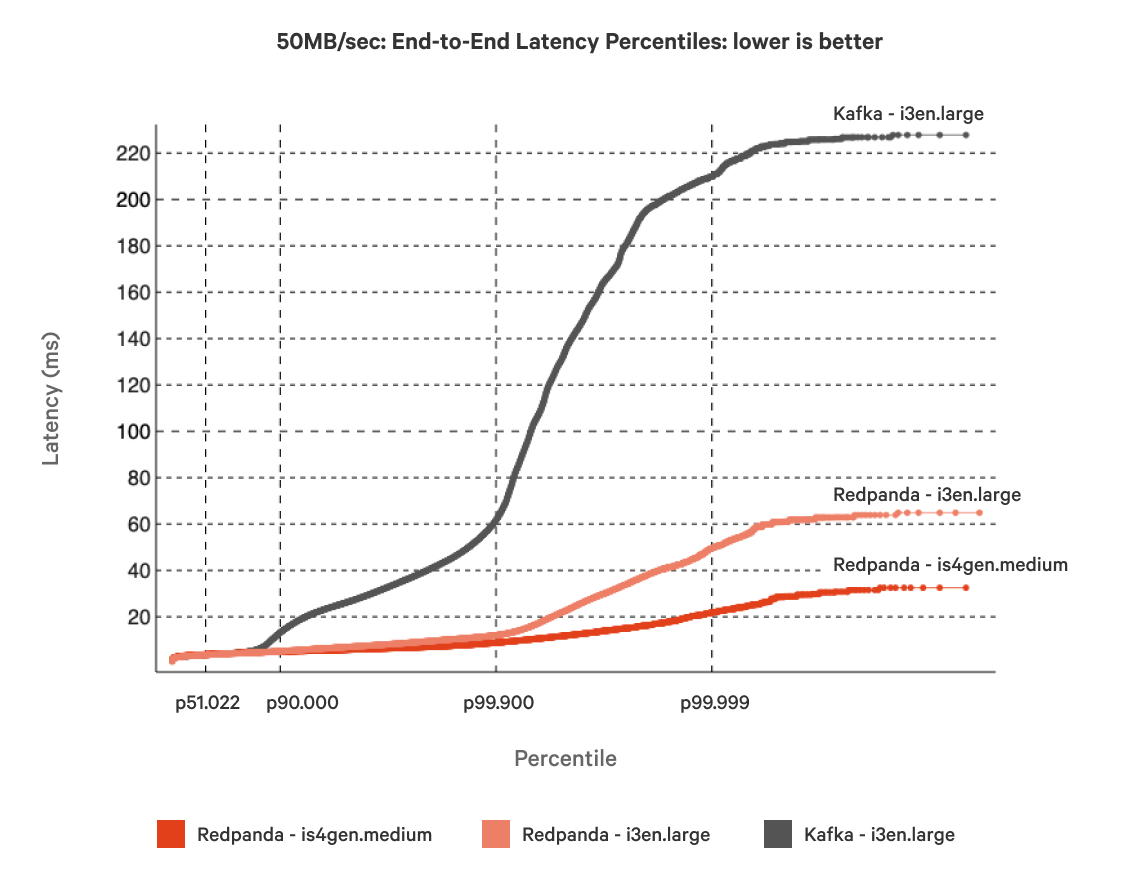
Figure 2. End-to-end latency percentages of 3-node Kafka clusters (i3en.large) vs. 3-node Redpanda clusters (is4gen.medium and i3en.large), using 50MB/sec workloads for all.
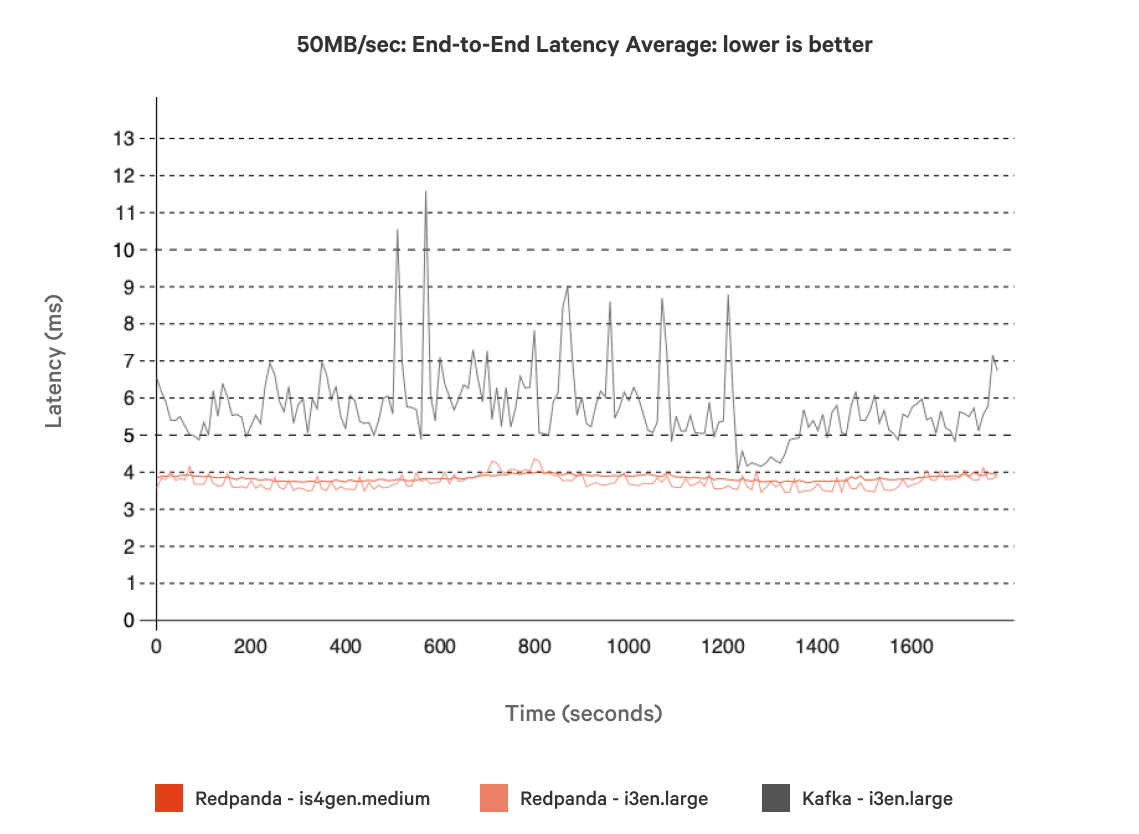
Figure 3. Average end-to-end latency of a 3-node Kafka cluster vs. a 3-node Redpanda cluster, using 50MB/sec workloads for both.
For the 500MB/sec workloads running on i3en.3xlarge instances, Redpanda was able to comfortably handle the workload with just 3 nodes.
When running the same workload on Kafka we found that Kafka was not able to sustain the publish rate with three nodes. We re-ran the workload on Kafka with up to 9 nodes to evaluate whether we could bring Kafka’s throughput in line with Redpanda’s.
In comparing tail latencies, Figure 4 shows that a 3-node Redpand cluster is 10x faster against a 4-node Kafka cluster, and 4x faster against a 9-node Kafka cluster.
In comparing average (mean) latencies, Figure 5 shows that a 3-node Redpanda cluster is 5x faster when Kafka ran with 4 nodes and 3x faster when Kafka ran with triple the node count (i.e. 9 nodes).
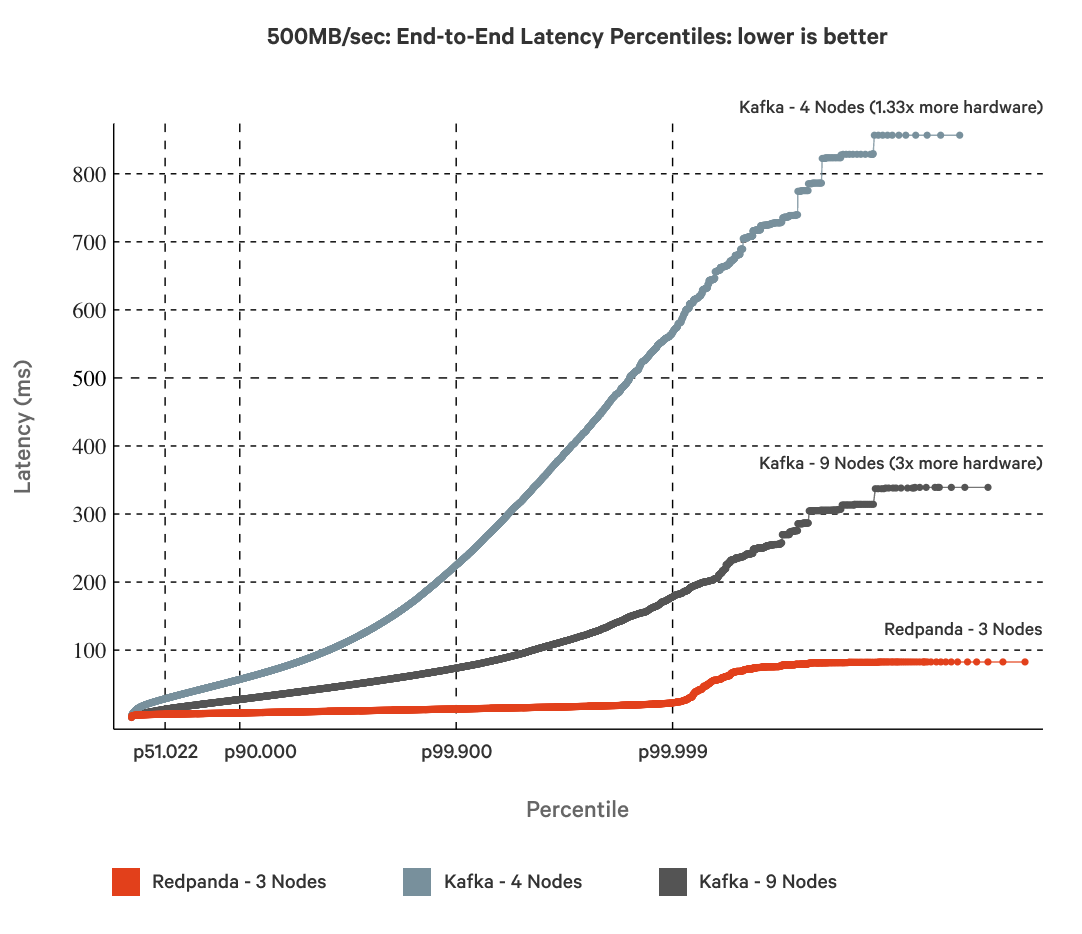
Figure 4. End-to-end latency percentages of a 9-node and 4-node Kafka cluster vs. a 3-node Redpanda cluster, using 500MB/sec workloads for all three.
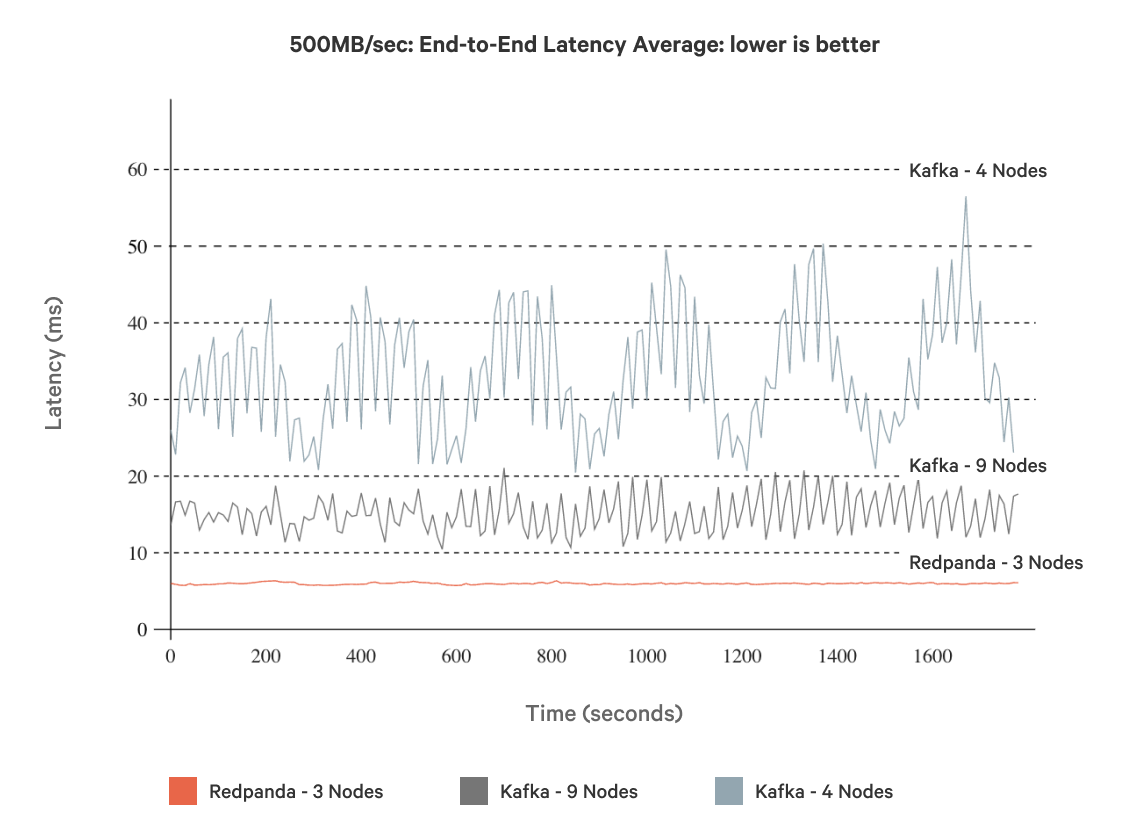
Figure 5. Average end-to-end latency of a 9-node and 4-node Kafka cluster vs. a 3-node Redpanda cluster, using 500MB/sec workloads for all three.
We increased the size of the instance types to i3en.6xlarge for the 1GB/sec workload, and again Redpanda was able to comfortably sustain this high throughput with 3 nodes.
Again, Kafka was unable to complete the test on 3 nodes so we repeated the test multiple times, adding more nodes at every iteration, until Kafka got closer to Redpanda’s performance.
At 1GB/sec throughput, the percentile graph for this workload (Figure 6) shows that Redpanda is a staggering 70x faster than Kafka with half the amount of hardware (3 nodes versus 6 nodes) at the tail end.
With additional 3 nodes added to Kafka (a total of 9 nodes), Redpanda still remains 7x faster. However, at this point, Kafka is running 3x the hardware (9 nodes of Kafka versus 3 nodes of Redpanda)! The average latency (Figure 7) showed significant variability at 6 nodes, whereas at 9 nodes Kafka was within 16% of Redpanda.

Figure 6. End-to-end latency percentages of a 9-node and 6-node Kafka cluster vs. a 3-node Redpanda cluster, using 1GB/sec workloads for all three.
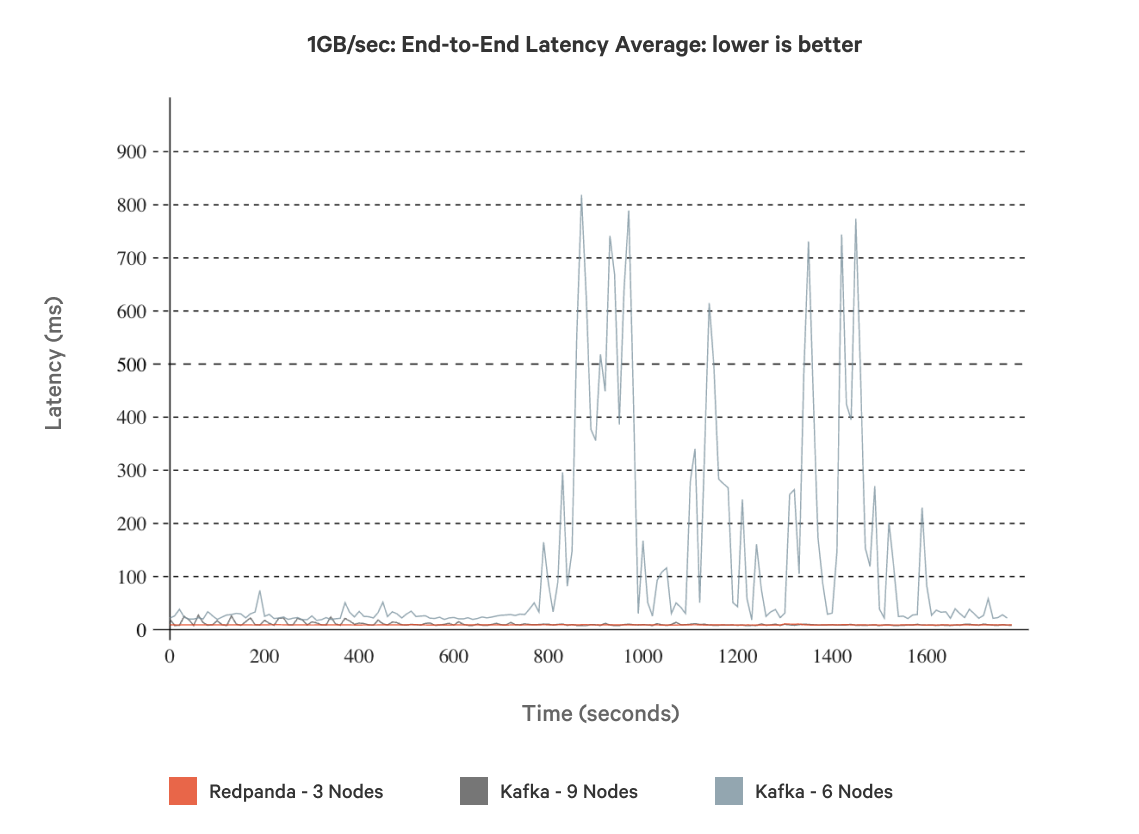
Figure 7. Average end-to-end latency of a 9-node and 6-node Kafka cluster vs. a 3-node Redpanda cluster, using 1GB/sec workloads for all three.
We’d love to have compared Redpanda and Kafka on equal resources, but Kafka could not deliver the medium and large workloads without additional hardware and wouldn’t run on ARM for the smaller workload.
Our conclusion is that with a similar number of nodes, (in some cases giving Kafka the additional nodes it needs to run the workloads successfully), Redpanda performs at least 10x faster at tail latencies (p99.99). On the same hardware, Kafka simply cannot sustain the same throughput.
The results of our investigation are summarized below. In each case, we’ve highlighted the best possible performance for Kafka and Redpanda, giving each the minimum possible hardware required to sustain the desired throughput.
| Workload size/Throughput | Kafka P99.99 | Redpanda P99.99 | Redpanda faster by |
|---|---|---|---|
| Small - 50MB/s | 164.57ms (3 nodes) | 13.91ms (3 nodes) | 12x |
| Medium - 500MB/s | 388.66ms (4 nodes) | 16.658ms (3 nodes) | 23x |
| Large - 1GB/s | 5509.73ms (6 nodes) | 79.574ms (3 nodes) | 70x |
Figure 8. Summary of results, highlighting the best performance of Kafka and Redpanda across workloads.
Redpanda’s speed enables use cases that were never before possible or previously too costly. Consider Alpaca, who boosted their performance by 100x by rearchitecting their order management platform around Redpanda.
Moreover, Redpanda enables you to achieve this type of performance with the smallest hardware footprint possible in the market, and at a significantly lower TCO. We’ll follow up with exactly how much Redpanda could save you in due course.
We’d love to see what you could do with Redpanda! Take us for a test drive here. Check out our documentation to understand the nuts and bolts of how the platform works, or read more of our blogs to see the plethora of ways to integrate with Redpanda. To ask our Solution Architects and Core Engineers questions and interact with other Redpanda users, join the Redpanda Community on Slack.
A benchmark on how a single analytical query behaves as the dataset and cluster grow

47% lower latencies using 15% less CPU means better performance for intensive workloads

Benchmark shows Vera provides 5.5x lower latencies and up to 73% higher throughputs than other leading CPU models
Subscribe to our VIP (very important panda) mailing list to pounce on the latest blogs, surprise announcements, and community events!
Opt out anytime.